 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatWhy: Formal Verification Tool for Statistical Hypothesis Testing Programs
May 25, 2024
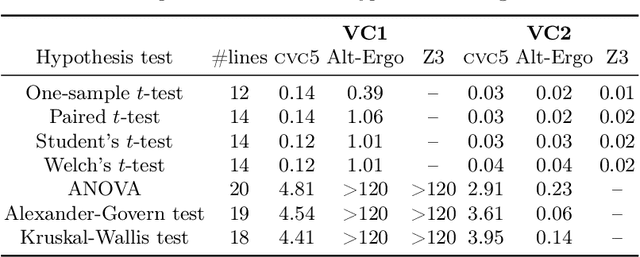

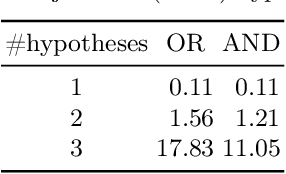
Statistical methods have been widely misused and misinterpreted in various scientific fields, raising significant concerns about the integrity of scientific research. To develop techniques to mitigate this problem, we propose a new method for formally specifying and automatically verifying the correctness of statistical programs. In this method, programmers are reminded to check the requirements for statistical methods by annotating their source code. Then, a software tool called StatWhy automatically checks whether the programmers have properly specified the requirements for the statistical methods. This tool is implemented using the Why3 platform to verify the correctness of OCaml programs for statistical hypothesis testing. We demonstrate how StatWhy can be used to avoid common errors in a variety of popular hypothesis testing programs.
Threats, Vulnerabilities, and Controls of Machine Learning Based Systems: A Survey and Taxonomy
Jan 19, 2023



In this article, we propose the Artificial Intelligence Security Taxonomy to systematize the knowledge of threats, vulnerabilities, and security controls of machine-learning-based (ML-based) systems. We first classify the damage caused by attacks against ML-based systems, define ML-specific security, and discuss its characteristics. Next, we enumerate all relevant assets and stakeholders and provide a general taxonomy for ML-specific threats. Then, we collect a wide range of security controls against ML-specific threats through an extensive review of recent literature. Finally, we classify the vulnerabilities and controls of an ML-based system in terms of each vulnerable asset in the system's entire lifecycle.
Formalizing Statistical Causality via Modal Logic
Nov 01, 2022We propose a formal language for describing and explaining statistical causality. Concretely, we define Statistical Causality Language (StaCL) for specifying causal effects on random variables. StaCL incorporates modal operators for interventions to express causal properties between probability distributions in different possible worlds in a Kripke model. We formalize axioms for probability distributions, interventions, and causal predicates using StaCL formulas. These axioms are expressive enough to derive the rules of Pearl's do-calculus. Finally, we demonstrate by examples that StaCL can be used to prove and explain the correctness of statistical causal inference.
Sound and Relatively Complete Belief Hoare Logic for Statistical Hypothesis Testing Programs
Aug 15, 2022
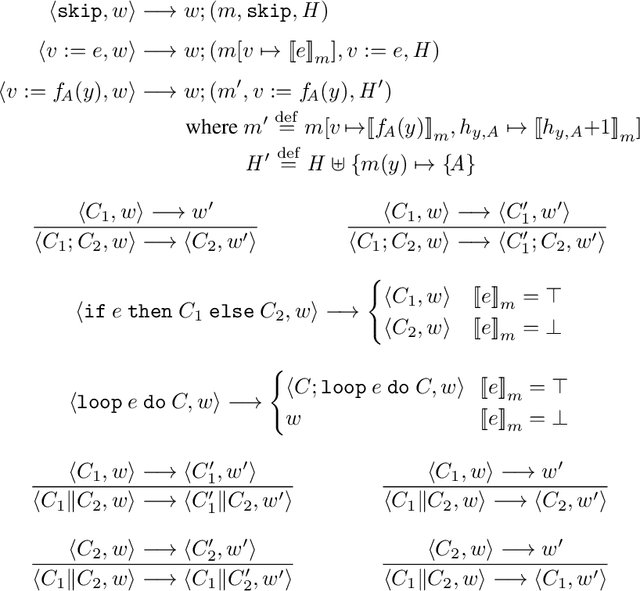


We propose a new approach to formally describing the requirement for statistical inference and checking whether a program uses the statistical method appropriately. Specifically, we define belief Hoare logic (BHL) for formalizing and reasoning about the statistical beliefs acquired via hypothesis testing. This program logic is sound and relatively complete with respect to a Kripke model for hypothesis tests. We demonstrate by examples that BHL is useful for reasoning about practical issues in hypothesis testing. In our framework, we clarify the importance of prior beliefs in acquiring statistical beliefs through hypothesis testing, and discuss the whole picture of the justification of statistical inference inside and outside the program logic.
Information Leakage Games: Exploring Information as a Utility Function
Dec 22, 2020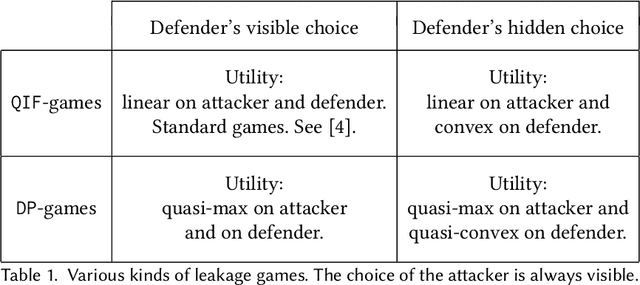
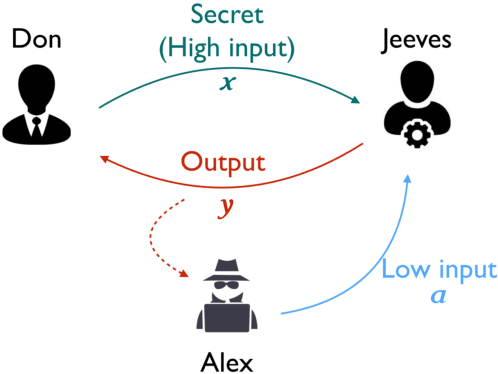

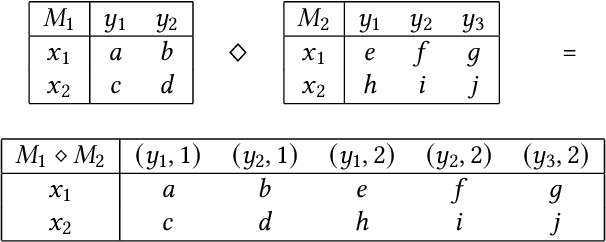
A common goal in the areas of secure information flow and privacy is to build effective defenses against unwanted leakage of information. To this end, one must be able to reason about potential attacks and their interplay with possible defenses. In this paper we propose a game-theoretic framework to formalize strategies of attacker and defender in the context of information leakage, and provide a basis for developing optimal defense methods. A crucial novelty of our games is that their utility is given by information leakage, which in some cases may behave in a non-linear way. This causes a significant deviation from classic game theory, in which utility functions are linear with respect to players' strategies. Hence, a key contribution of this paper is the establishment of the foundations of information leakage games. We consider two main categories of games, depending on the particular notion of information leakage being captured. The first category, which we call QIF-games, is tailored for the theory of quantitative information flow (QIF). The second one, which we call DP-games, corresponds to differential privacy (DP).
TransMIA: Membership Inference Attacks Using Transfer Shadow Training
Nov 30, 2020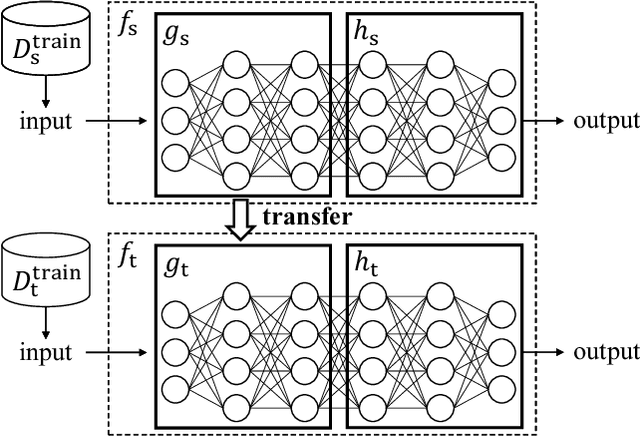
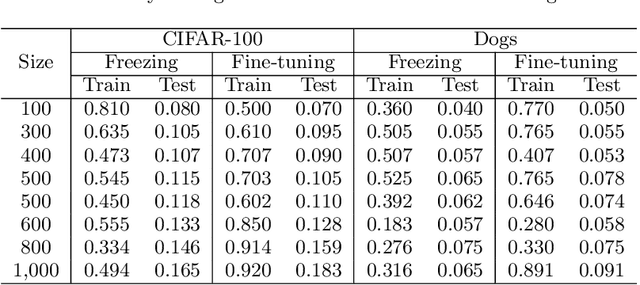
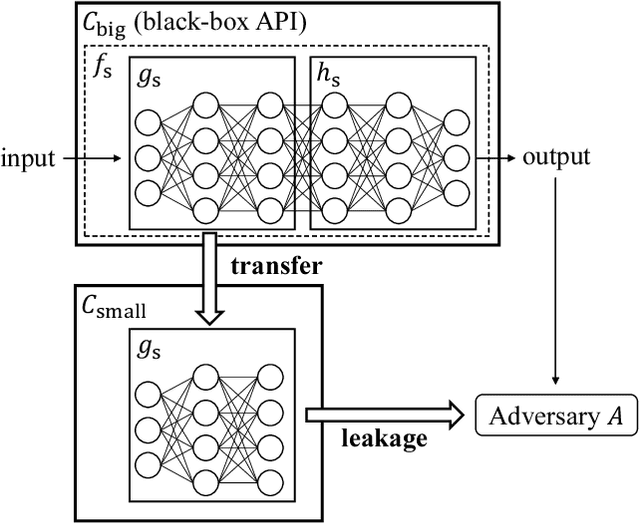
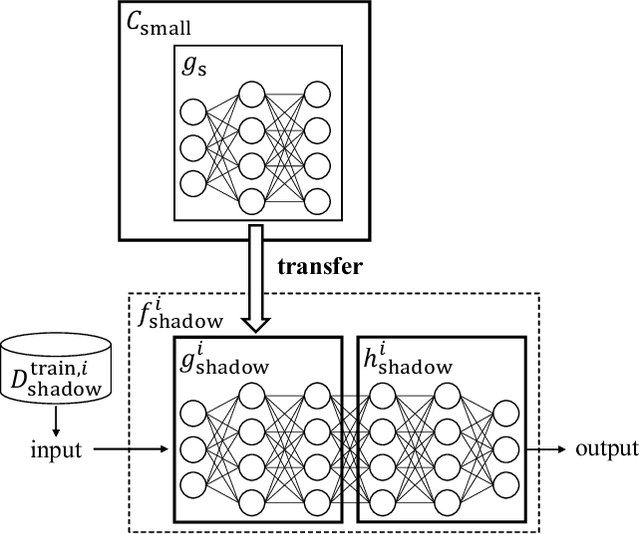
Transfer learning has been widely studied and gained increasing popularity to improve the accuracy of machine learning models by transferring some knowledge acquired in different training. However, no prior work has pointed out that transfer learning can strengthen privacy attacks on machine learning models. In this paper, we propose TransMIA (Transfer Learning-based Membership Inference Attacks), which use transfer learning to perform membership inference attacks on the source model when the adversary is able to access the parameters of the transferred model. In particular, we propose a transfer shadow training technique, where an adversary employs the parameters of the transferred model to construct shadow models, to significantly improve the performance of membership inference when a limited amount of shadow training data is available to the adversary. We evaluate our attacks using two real datasets, and show that our attacks outperform the state-of-the-art that does not use our transfer shadow training technique. We also compare four combinations of the learning-based/entropy-based approach and the fine-tuning/freezing approach, all of which employ our transfer shadow training technique. Then we examine the performance of these four approaches based on the distributions of confidence values, and discuss possible countermeasures against our attacks.
Locality Sensitive Hashing with Extended Differential Privacy
Nov 01, 2020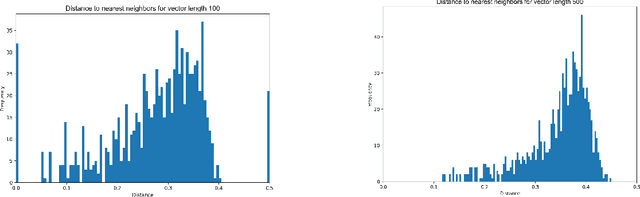
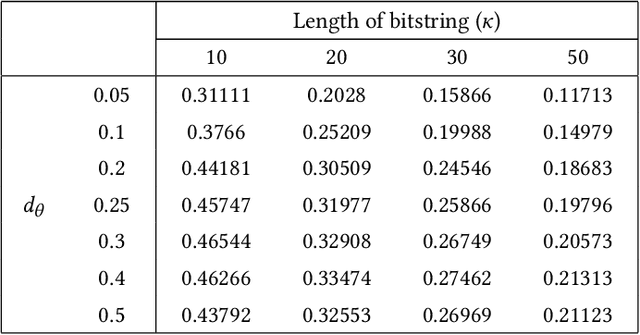
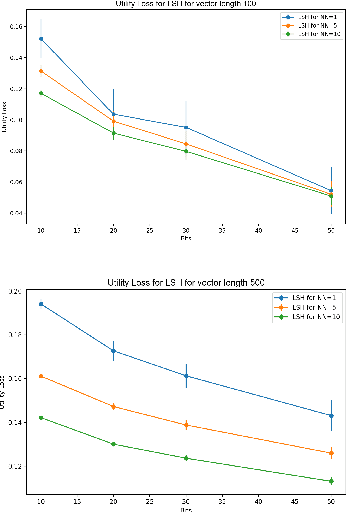
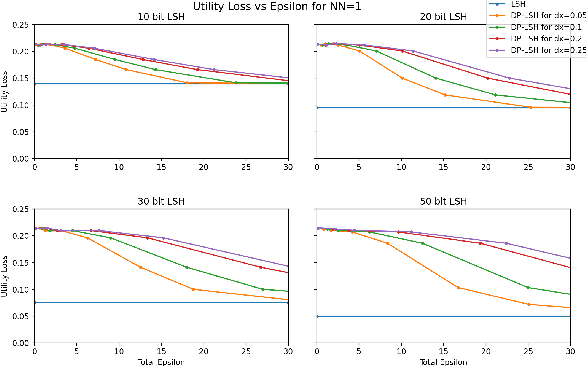
Extended differential privacy, a generalization of standard differential privacy (DP) using a general metric rather than the Hamming metric, has been widely studied to provide rigorous privacy guarantees while keeping high utility. However, existing works on extended DP focus on a specific metric such as the Euclidean metric, the $l_1$ metric, and the Earth Mover's metric, and cannot be applied to other metrics. Consequently, existing extended DP mechanisms are limited to a small number of applications such as location-based services and document processing. In this paper, we propose a mechanism providing extended DP with a wide range of metrics. Our mechanism is based on locality sensitive hashing (LSH) and randomized response, and can be applied to a wide variety of metrics including the angular distance (or cosine) metric, Jaccard metric, Earth Mover's metric, and $l_p$ metric. Moreover, our mechanism works well for personal data in a high-dimensional space. We theoretically analyze the privacy properties of our mechanism, introducing new versions of concentrated and probabilistic extended DP to explain the guarantees provided. Finally, we apply our mechanism to friend matching based on high-dimensional personal data with an angular distance metric in the local model. We show that existing local DP mechanisms such as the RAPPOR do not work in this application. We also show through experiments that our mechanism makes possible friend matching with rigorous privacy guarantees and high utility.
An Epistemic Approach to the Formal Specification of Statistical Machine Learning
Apr 27, 2020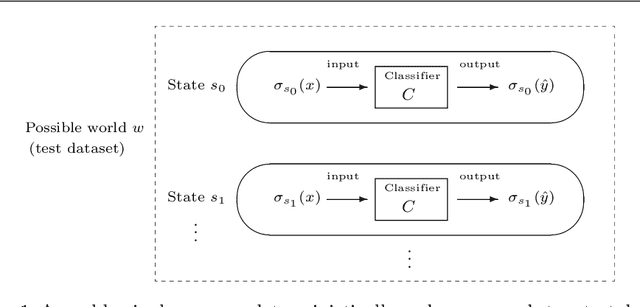
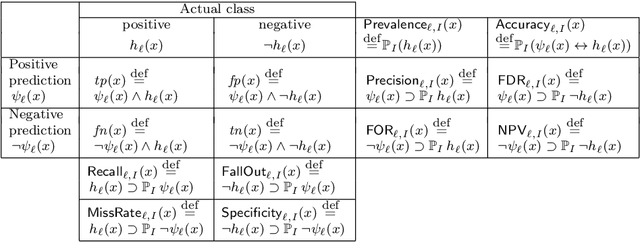
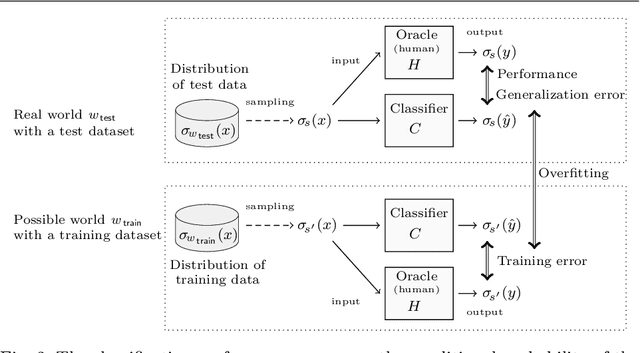

We propose an epistemic approach to formalizing statistical properties of machine learning. Specifically, we introduce a formal model for supervised learning based on a Kripke model where each possible world corresponds to a possible dataset and modal operators are interpreted as transformation and testing on datasets. Then we formalize various notions of the classification performance, robustness, and fairness of statistical classifiers by using our extension of statistical epistemic logic (StatEL). In this formalization, we show relationships among properties of classifiers, and relevance between classification performance and robustness. As far as we know, this is the first work that uses epistemic models and logical formulas to express statistical properties of machine learning, and would be a starting point to develop theories of formal specification of machine learning.
Privacy-Preserving Multiple Tensor Factorization for Synthesizing Large-Scale Location Traces
Dec 21, 2019
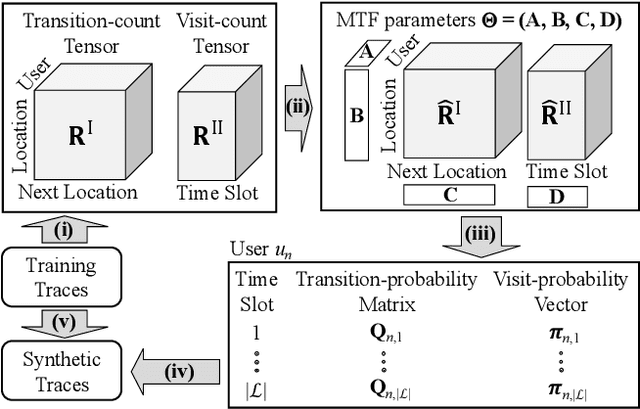


With the widespread use of LBSs (Location-based Services), synthesizing location traces plays an increasingly important role in analyzing spatial big data while protecting users' privacy. Although location synthesizers have been widely studied, existing synthesizers do not provide utility, privacy, or scalability sufficiently, hence are not practical for large-scale location traces. To overcome this issue, we propose a novel location synthesizer called PPMTF (Privacy-Preserving Multiple Tensor Factorization). We model various statistical features of the original traces by a transition-count tensor and a visit-count tensor. We simultaneously factorize these two tensors via multiple tensor factorization, and train factor matrices via posterior sampling. Then we synthesize traces from reconstructed tensors using the MH (Metropolis-Hastings) algorithm. We comprehensively evaluate the proposed method using two datasets. Our experimental results show that the proposed method preserves various statistical features, provides plausible deniability, and synthesizes large-scale location traces in practical time. The proposed method also significantly outperforms the state-of-the-art with regard to the utility, privacy, and scalability.
Towards Logical Specification of Statistical Machine Learning
Jul 24, 2019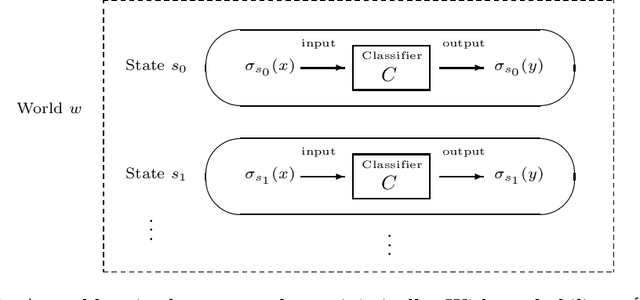

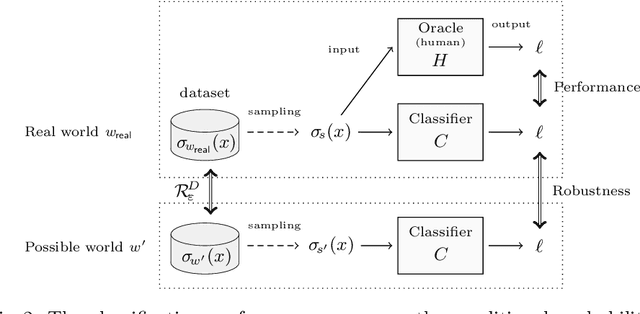
We introduce a logical approach to formalizing statistical properties of machine learning. Specifically, we propose a formal model for statistical classification based on a Kripke model, and formalize various notions of classification performance, robustness, and fairness of classifiers by using epistemic logic. Then we show some relationships among properties of classifiers and those between classification performance and robustness, which suggests robustness-related properties that have not been formalized in the literature as far as we know. To formalize fairness properties, we define a notion of counterfactual knowledge and show techniques to formalize conditional indistinguishability by using counterfactual epistemic operators. As far as we know, this is the first work that uses logical formulas to express statistical properties of machine learning, and that provides epistemic (resp. counterfactually epistemic) views on robustness (resp. fairness) of classifiers.