 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Optimization of Conformal Predictors via Incremental and Decremental Learning
Feb 05, 2021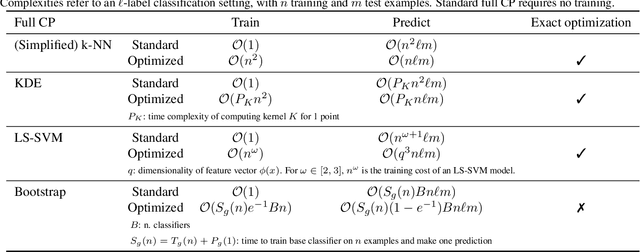
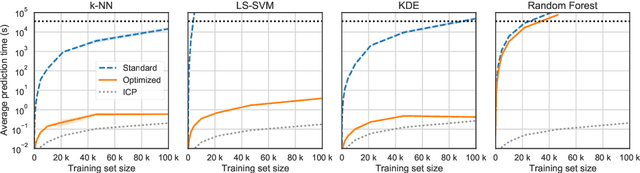
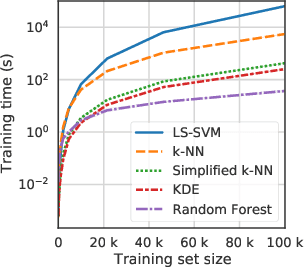
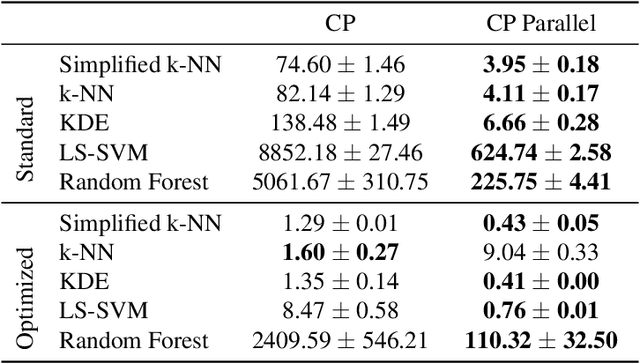
Conformal Predictors (CP) are wrappers around ML methods, providing error guarantees under weak assumptions on the data distribution. They are suitable for a wide range of problems, from classification and regression to anomaly detection. Unfortunately, their high computational complexity limits their applicability to large datasets. In this work, we show that it is possible to speed up a CP classifier considerably, by studying it in conjunction with the underlying ML method, and by exploiting incremental&decremental learning. For methods such as k-NN, KDE, and kernel LS-SVM, our approach reduces the running time by one order of magnitude, whilst producing exact solutions. With similar ideas, we also achieve a linear speed up for the harder case of bootstrapping. Finally, we extend these techniques to improve upon an optimization of k-NN CP for regression. We evaluate our findings empirically, and discuss when methods are suitable for CP optimization.
Information Leakage Games: Exploring Information as a Utility Function
Dec 22, 2020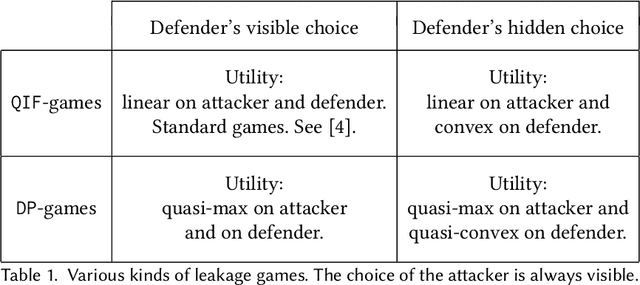
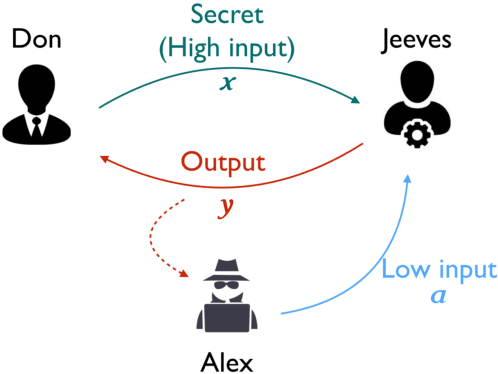

A common goal in the areas of secure information flow and privacy is to build effective defenses against unwanted leakage of information. To this end, one must be able to reason about potential attacks and their interplay with possible defenses. In this paper we propose a game-theoretic framework to formalize strategies of attacker and defender in the context of information leakage, and provide a basis for developing optimal defense methods. A crucial novelty of our games is that their utility is given by information leakage, which in some cases may behave in a non-linear way. This causes a significant deviation from classic game theory, in which utility functions are linear with respect to players' strategies. Hence, a key contribution of this paper is the establishment of the foundations of information leakage games. We consider two main categories of games, depending on the particular notion of information leakage being captured. The first category, which we call QIF-games, is tailored for the theory of quantitative information flow (QIF). The second one, which we call DP-games, corresponds to differential privacy (DP).
Estimating g-Leakage via Machine Learning
May 09, 2020
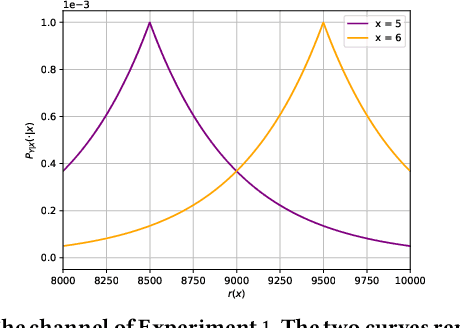
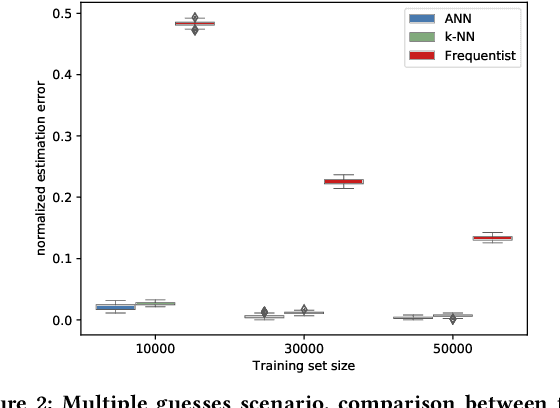
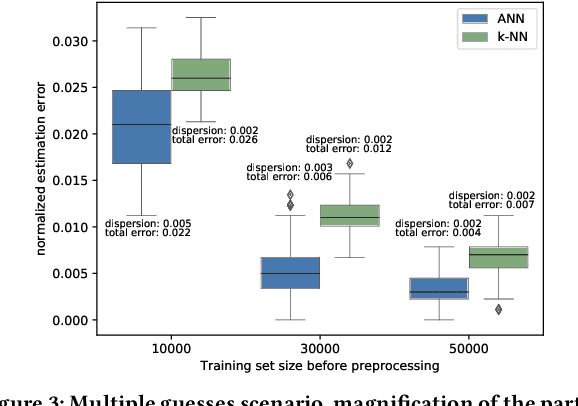
This paper considers the problem of estimating the information leakage of a system in the black-box scenario. It is assumed that the system's internals are unknown to the learner, or anyway too complicated to analyze, and the only available information are pairs of input-output data samples, possibly obtained by submitting queries to the system or provided by a third party. Previous research has mainly focused on counting the frequencies to estimate the input-output conditional probabilities (referred to as frequentist approach), however this method is not accurate when the domain of possible outputs is large. To overcome this difficulty, the estimation of the Bayes error of the ideal classifier was recently investigated using Machine Learning (ML) models and it has been shown to be more accurate thanks to the ability of those models to learn the input-output correspondence. However, the Bayes vulnerability is only suitable to describe one-try attacks. A more general and flexible measure of leakage is the g-vulnerability, which encompasses several different types of adversaries, with different goals and capabilities. In this paper, we propose a novel approach to perform black-box estimation of the g-vulnerability using ML. A feature of our approach is that it does not require to estimate the conditional probabilities, and that it is suitable for a large class of ML algorithms. First, we formally show the learnability for all data distributions. Then, we evaluate the performance via various experiments using k-Nearest Neighbors and Neural Networks. Our results outperform the frequentist approach when the observables domain is large.
Generating Optimal Privacy-Protection Mechanisms via Machine Learning
Apr 01, 2019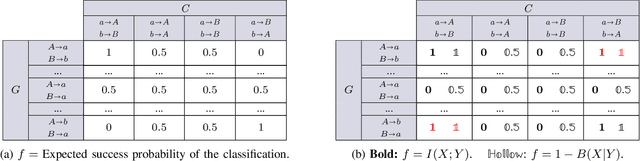
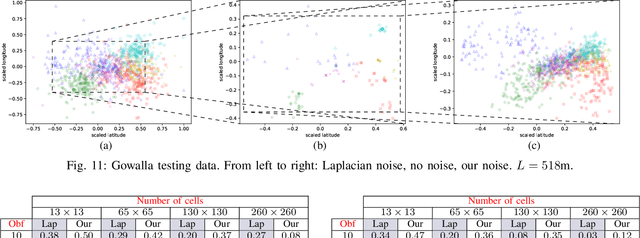

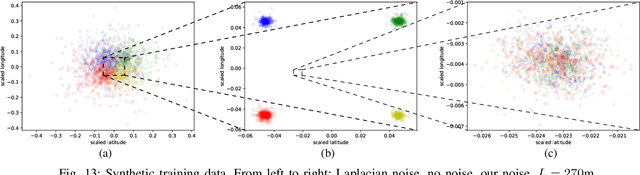
We consider the problem of obfuscating sensitive information while preserving utility. Given that an analytical solution is often not feasible because of un-scalability and because the background knowledge may be too complicated to determine, we propose an approach based on machine learning, inspired by the GANs (Generative Adversarial Networks) paradigm. The idea is to set up two nets: the generator, that tries to produce an optimal obfuscation mechanism to protect the data, and the classifier, that tries to de-obfuscate the data. By letting the two nets compete against each other, the mechanism improves its degree of protection, until an equilibrium is reached. We apply our method to the case of location privacy, and we perform experiments on synthetic data and on real data from the Gowalla dataset. We evaluate the privacy of the mechanism not only by its capacity to defeat the classificator, but also in terms of the Bayes error, which represents the strongest possible adversary. We compare the privacy-utility tradeoff of our method with that of the planar Laplace mechanism used in geo-indistinguishability, showing favorable results.