 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDegree-Preserving Randomized Response for Graph Neural Networks under Local Differential Privacy
Feb 21, 2022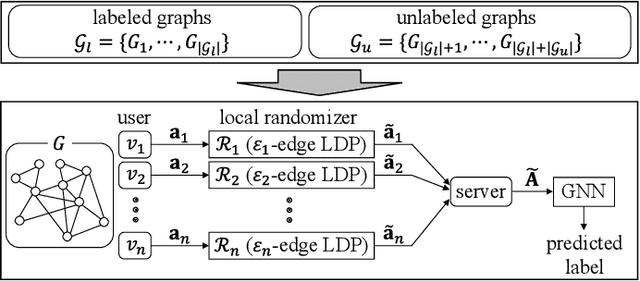
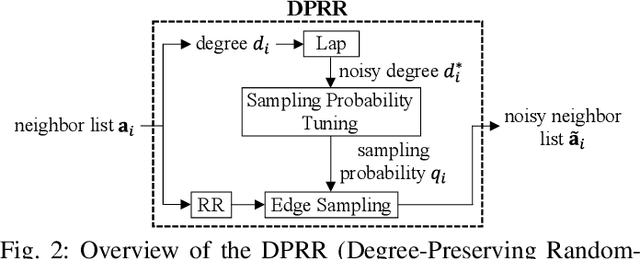
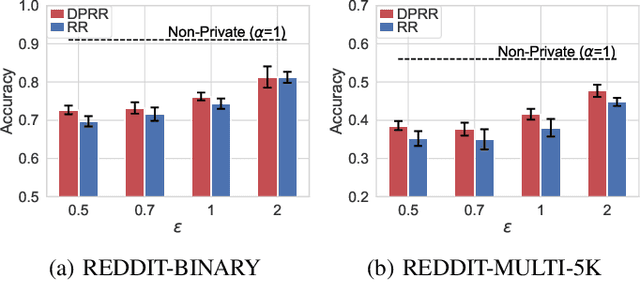
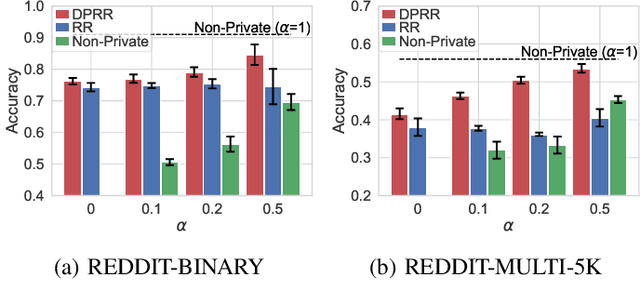
Differentially private GNNs (Graph Neural Networks) have been recently studied to provide high accuracy in various tasks on graph data while strongly protecting user privacy. In particular, a recent study proposes an algorithm to protect each user's feature vector in an attributed graph with LDP (Local Differential Privacy), a strong privacy notion without a trusted third party. However, this algorithm does not protect edges (friendships) in a social graph or protect user privacy in unattributed graphs. It remains open how to strongly protect edges with LDP while keeping high accuracy in GNNs. In this paper, we propose a novel LDP algorithm called the DPRR (Degree-Preserving Randomized Response) to provide LDP for edges in GNNs. Our DPRR preserves each user's degree hence a graph structure while providing edge LDP. Technically, we use Warner's RR (Randomized Response) and strategic edge sampling, where each user's sampling probability is automatically tuned to preserve the degree information. We prove that the DPRR approximately preserves the degree information under edge LDP. We focus on graph classification as a task of GNNs and evaluate the DPRR using two social graph datasets. Our experimental results show that the DPRR significantly outperforms Warner's RR and provides accuracy close to a non-private algorithm with a reasonable privacy budget, e.g., epsilon=1.
TransMIA: Membership Inference Attacks Using Transfer Shadow Training
Nov 30, 2020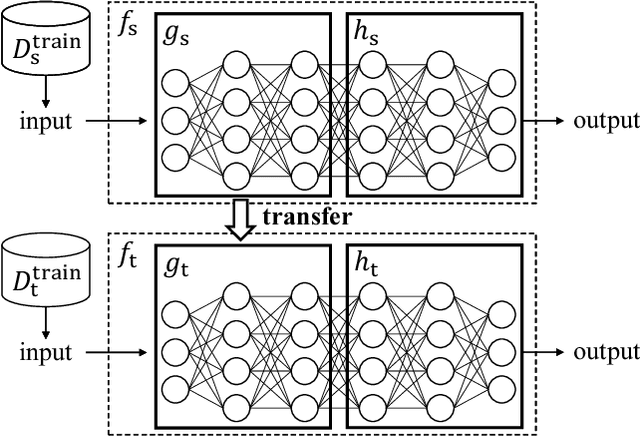
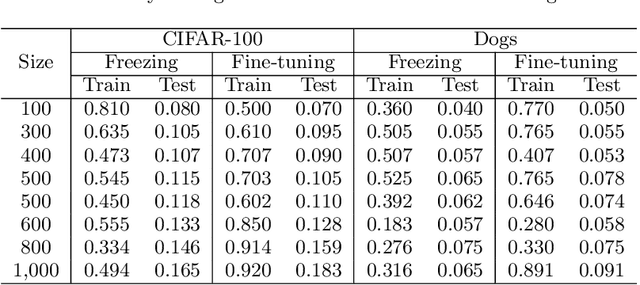
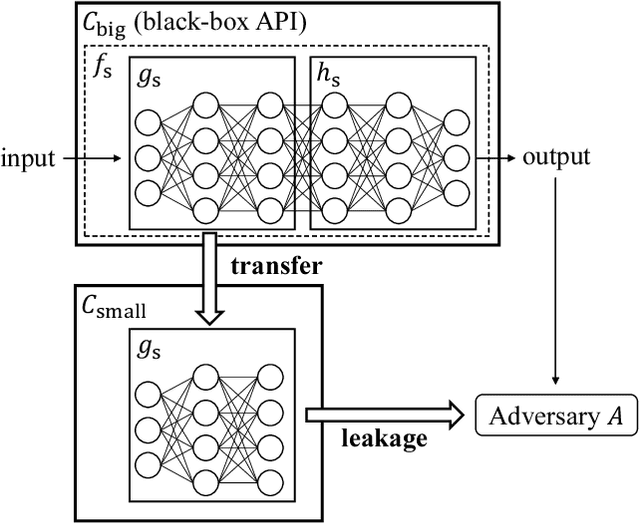
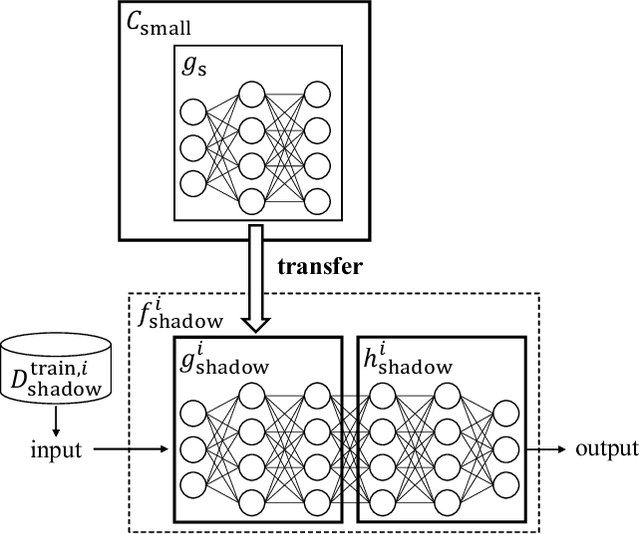
Transfer learning has been widely studied and gained increasing popularity to improve the accuracy of machine learning models by transferring some knowledge acquired in different training. However, no prior work has pointed out that transfer learning can strengthen privacy attacks on machine learning models. In this paper, we propose TransMIA (Transfer Learning-based Membership Inference Attacks), which use transfer learning to perform membership inference attacks on the source model when the adversary is able to access the parameters of the transferred model. In particular, we propose a transfer shadow training technique, where an adversary employs the parameters of the transferred model to construct shadow models, to significantly improve the performance of membership inference when a limited amount of shadow training data is available to the adversary. We evaluate our attacks using two real datasets, and show that our attacks outperform the state-of-the-art that does not use our transfer shadow training technique. We also compare four combinations of the learning-based/entropy-based approach and the fine-tuning/freezing approach, all of which employ our transfer shadow training technique. Then we examine the performance of these four approaches based on the distributions of confidence values, and discuss possible countermeasures against our attacks.
Locality Sensitive Hashing with Extended Differential Privacy
Nov 01, 2020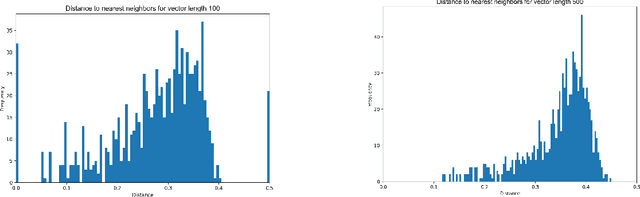
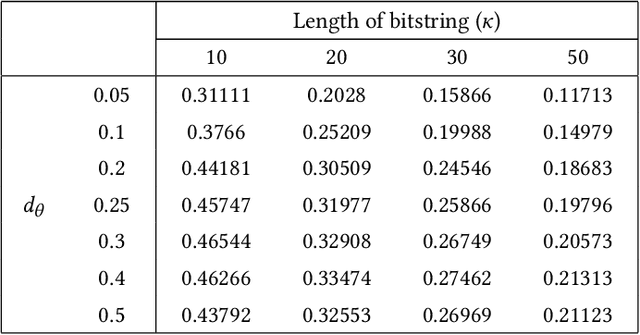
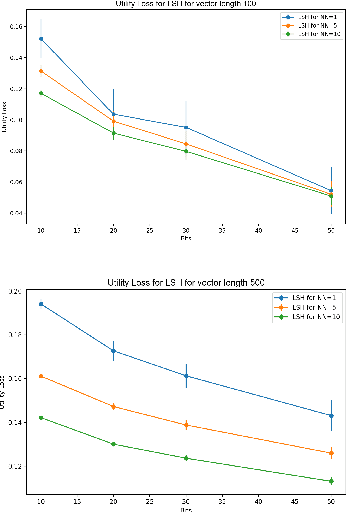
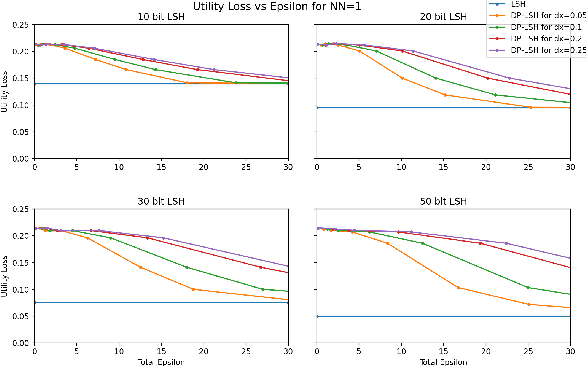
Extended differential privacy, a generalization of standard differential privacy (DP) using a general metric rather than the Hamming metric, has been widely studied to provide rigorous privacy guarantees while keeping high utility. However, existing works on extended DP focus on a specific metric such as the Euclidean metric, the $l_1$ metric, and the Earth Mover's metric, and cannot be applied to other metrics. Consequently, existing extended DP mechanisms are limited to a small number of applications such as location-based services and document processing. In this paper, we propose a mechanism providing extended DP with a wide range of metrics. Our mechanism is based on locality sensitive hashing (LSH) and randomized response, and can be applied to a wide variety of metrics including the angular distance (or cosine) metric, Jaccard metric, Earth Mover's metric, and $l_p$ metric. Moreover, our mechanism works well for personal data in a high-dimensional space. We theoretically analyze the privacy properties of our mechanism, introducing new versions of concentrated and probabilistic extended DP to explain the guarantees provided. Finally, we apply our mechanism to friend matching based on high-dimensional personal data with an angular distance metric in the local model. We show that existing local DP mechanisms such as the RAPPOR do not work in this application. We also show through experiments that our mechanism makes possible friend matching with rigorous privacy guarantees and high utility.
Privacy-Preserving Multiple Tensor Factorization for Synthesizing Large-Scale Location Traces
Dec 21, 2019
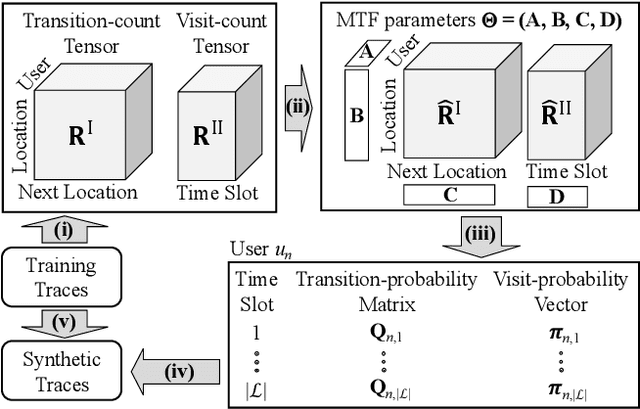


With the widespread use of LBSs (Location-based Services), synthesizing location traces plays an increasingly important role in analyzing spatial big data while protecting users' privacy. Although location synthesizers have been widely studied, existing synthesizers do not provide utility, privacy, or scalability sufficiently, hence are not practical for large-scale location traces. To overcome this issue, we propose a novel location synthesizer called PPMTF (Privacy-Preserving Multiple Tensor Factorization). We model various statistical features of the original traces by a transition-count tensor and a visit-count tensor. We simultaneously factorize these two tensors via multiple tensor factorization, and train factor matrices via posterior sampling. Then we synthesize traces from reconstructed tensors using the MH (Metropolis-Hastings) algorithm. We comprehensively evaluate the proposed method using two datasets. Our experimental results show that the proposed method preserves various statistical features, provides plausible deniability, and synthesizes large-scale location traces in practical time. The proposed method also significantly outperforms the state-of-the-art with regard to the utility, privacy, and scalability.
Local Distribution Obfuscation via Probability Coupling
Jul 13, 2019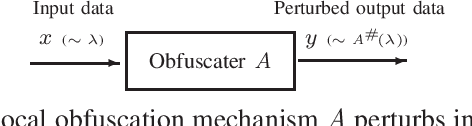


We introduce a general model for the local obfuscation of probability distributions and investigate its theoretical properties. Specifically, we relax a notion of distribution privacy by generalizing it to divergence, and investigate local obfuscation mechanisms that provide the divergence distribution privacy. To provide f-divergence distribution privacy, we prove that the perturbation noise should be added proportionally to the Earth mover's distance between the probability distributions that we want to make indistinguishable. Furthermore, we introduce a local obfuscation mechanism, which we call a coupling mechanism, that provides divergence distribution privacy while optimizing the utility of obfuscated data by using exact/approximate auxiliary information on the input distributions we want to protect.
Cancelable Indexing Based on Low-rank Approximation of Correlation-invariant Random Filtering for Fast and Secure Biometric Identification
Apr 05, 2018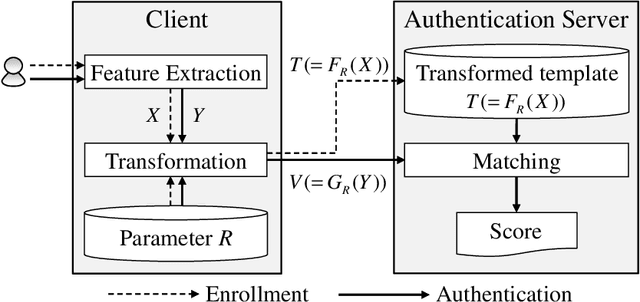



A cancelable biometric scheme called correlation-invariant random filtering (CIRF) is known as a promising template protection scheme. This scheme transforms a biometric feature represented as an image via the 2D number theoretic transform (NTT) and random filtering. CIRF has perfect secrecy in that the transformed feature leaks no information about the original feature. However, CIRF cannot be applied to large-scale biometric identification, since the 2D inverse NTT in the matching phase requires high computational time. Furthermore, existing biometric indexing schemes cannot be used in conjunction with template protection schemes to speed up biometric identification, since a biometric index leaks some information about the original feature. In this paper, we propose a novel indexing scheme called "cancelable indexing" to speed up CIRF without losing its security properties. The proposed scheme is based on fast computation of CIRF via low-rank approximation of biometric images and via a minimum spanning tree representation of low-rank matrices in the Fourier domain. We prove that the transformed index leaks no information about the original index and the original biometric feature (i.e., perfect secrecy), and thoroughly discuss the security of the proposed scheme. We also demonstrate that it significantly reduces the one-to-many matching time using a finger-vein dataset that includes six fingers from 505 subjects.