 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Dictionary-based Decomposition Layer for Structured Representation Learning
Jun 11, 2024



Neuro-symbolic neural networks have been extensively studied to integrate symbolic operations with neural networks, thereby improving systematic generalization. Specifically, Tensor Product Representation (TPR) framework enables neural networks to perform differentiable symbolic operations by encoding the symbolic structure of data within vector spaces. However, TPR-based neural networks often struggle to decompose unseen data into structured TPR representations, undermining their symbolic operations. To address this decomposition problem, we propose a Discrete Dictionary-based Decomposition (D3) layer designed to enhance the decomposition capabilities of TPR-based models. D3 employs discrete, learnable key-value dictionaries trained to capture symbolic features essential for decomposition operations. It leverages the prior knowledge acquired during training to generate structured TPR representations by mapping input data to pre-learned symbolic features within these dictionaries. D3 is a straightforward drop-in layer that can be seamlessly integrated into any TPR-based model without modifications. Our experimental results demonstrate that D3 significantly improves the systematic generalization of various TPR-based models while requiring fewer additional parameters. Notably, D3 outperforms baseline models on the synthetic task that demands the systematic decomposition of unseen combinatorial data.
Attention-based Iterative Decomposition for Tensor Product Representation
Jun 03, 2024



In recent research, Tensor Product Representation (TPR) is applied for the systematic generalization task of deep neural networks by learning the compositional structure of data. However, such prior works show limited performance in discovering and representing the symbolic structure from unseen test data because their decomposition to the structural representations was incomplete. In this work, we propose an Attention-based Iterative Decomposition (AID) module designed to enhance the decomposition operations for the structured representations encoded from the sequential input data with TPR. Our AID can be easily adapted to any TPR-based model and provides enhanced systematic decomposition through a competitive attention mechanism between input features and structured representations. In our experiments, AID shows effectiveness by significantly improving the performance of TPR-based prior works on the series of systematic generalization tasks. Moreover, in the quantitative and qualitative evaluations, AID produces more compositional and well-bound structural representations than other works.
Experimentally realized in situ backpropagation for deep learning in nanophotonic neural networks
May 17, 2022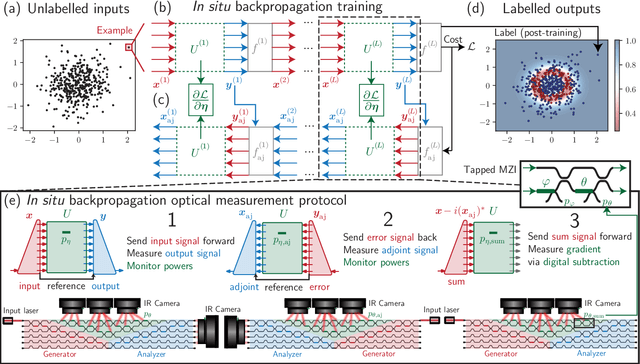
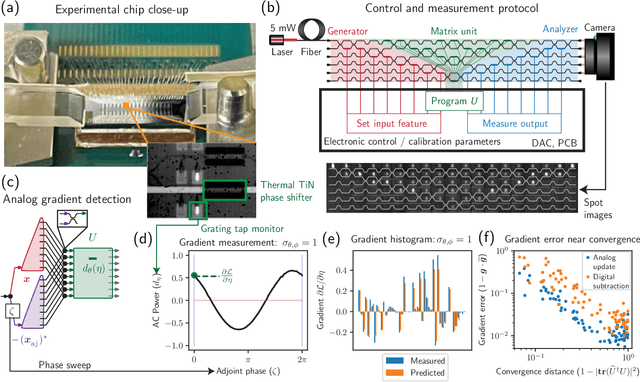
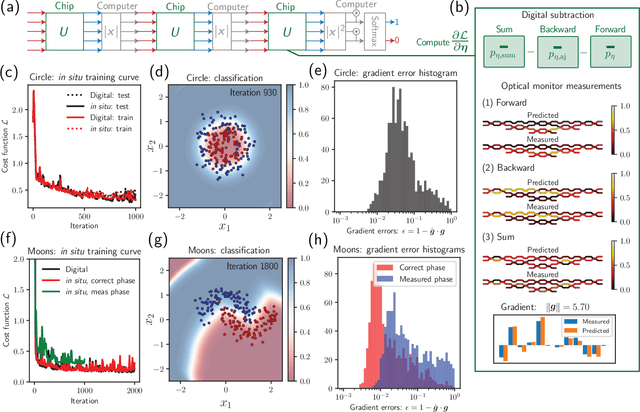
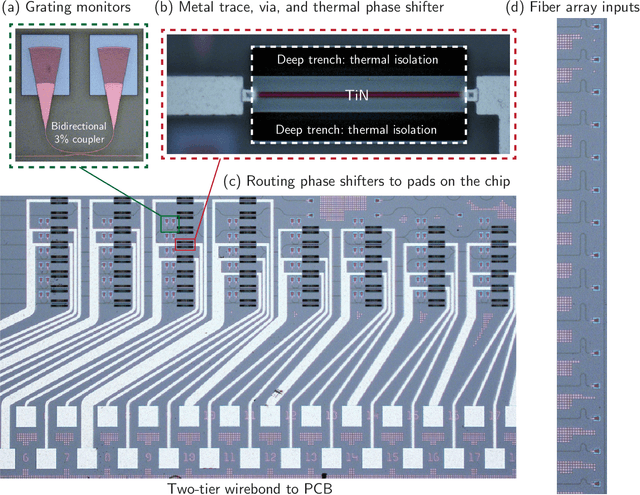
Neural networks are widely deployed models across many scientific disciplines and commercial endeavors ranging from edge computing and sensing to large-scale signal processing in data centers. The most efficient and well-entrenched method to train such networks is backpropagation, or reverse-mode automatic differentiation. To counter an exponentially increasing energy budget in the artificial intelligence sector, there has been recent interest in analog implementations of neural networks, specifically nanophotonic neural networks for which no analog backpropagation demonstration exists. We design mass-manufacturable silicon photonic neural networks that alternately cascade our custom designed "photonic mesh" accelerator with digitally implemented nonlinearities. These reconfigurable photonic meshes program computationally intensive arbitrary matrix multiplication by setting physical voltages that tune the interference of optically encoded input data propagating through integrated Mach-Zehnder interferometer networks. Here, using our packaged photonic chip, we demonstrate in situ backpropagation for the first time to solve classification tasks and evaluate a new protocol to keep the entire gradient measurement and update of physical device voltages in the analog domain, improving on past theoretical proposals. Our method is made possible by introducing three changes to typical photonic meshes: (1) measurements at optical "grating tap" monitors, (2) bidirectional optical signal propagation automated by fiber switch, and (3) universal generation and readout of optical amplitude and phase. After training, our classification achieves accuracies similar to digital equivalents even in presence of systematic error. Our findings suggest a new training paradigm for photonics-accelerated artificial intelligence based entirely on a physical analog of the popular backpropagation technique.
Distributed Memory based Self-Supervised Differentiable Neural Computer
Jul 21, 2020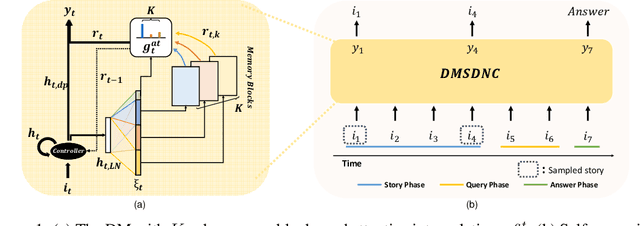

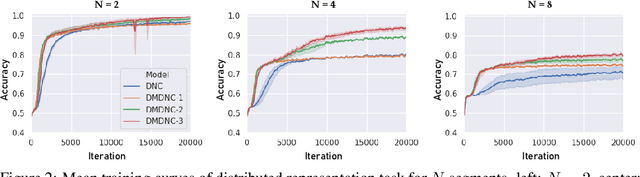

A differentiable neural computer (DNC) is a memory augmented neural network devised to solve a wide range of algorithmic and question answering tasks and it showed promising performance in a variety of domains. However, its single memory-based operations are not enough to store and retrieve diverse informative representations existing in many tasks. Furthermore, DNC does not explicitly consider the memorization itself as a target objective, which inevitably leads to a very slow learning speed of the model. To address those issues, we propose a novel distributed memory-based self-supervised DNC architecture for enhanced memory augmented neural network performance. We introduce (i) a multiple distributed memory block mechanism that stores information independently to each memory block and uses stored information in a cooperative way for diverse representation and (ii) a self-supervised memory loss term which ensures how well a given input is written to the memory. Our experiments on algorithmic and question answering tasks show that the proposed model outperforms all other variations of DNC in a large margin, and also matches the performance of other state-of-the-art memory-based network models.