 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Rank Adjustment for Accurate and Efficient Neural Network Training
Aug 13, 2025Low-rank training methods reduce the number of trainable parameters by re-parameterizing the weights with matrix decompositions (e.g., singular value decomposition). However, enforcing a fixed low-rank structure caps the rank of the weight matrices and can hinder the model's ability to learn complex patterns. Furthermore, the effective rank of the model's weights tends to decline during training, and this drop is accelerated when the model is reparameterized into a low-rank structure. In this study, we argue that strategically interleaving full-rank training epochs within low-rank training epochs can effectively restore the rank of the model's weights. Based on our findings, we propose a general dynamic-rank training framework that is readily applicable to a wide range of neural-network tasks. We first describe how to adjust the rank of weight matrix to alleviate the inevitable rank collapse that arises during training, and then present extensive empirical results that validate our claims and demonstrate the efficacy of the proposed framework. Our empirical study shows that the proposed method achieves almost the same computational cost as SVD-based low-rank training while achieving a comparable accuracy to full-rank training across various benchmarks.
Task Vector Quantization for Memory-Efficient Model Merging
Mar 10, 2025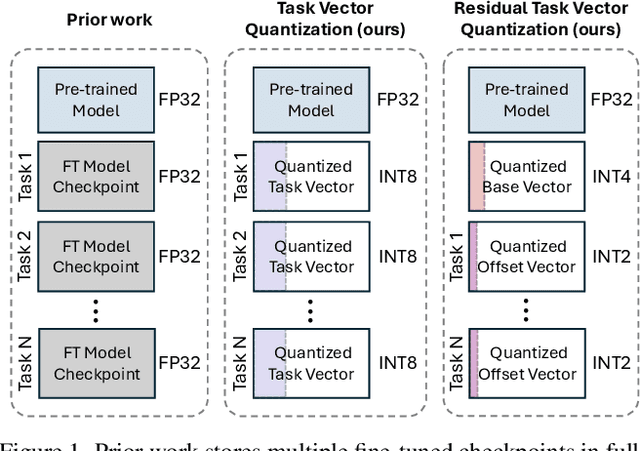
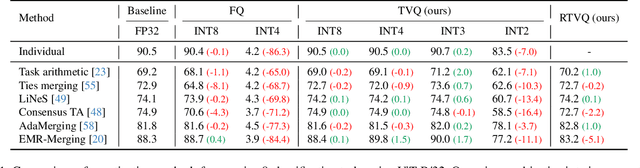
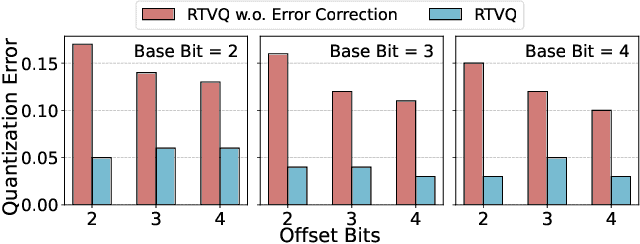
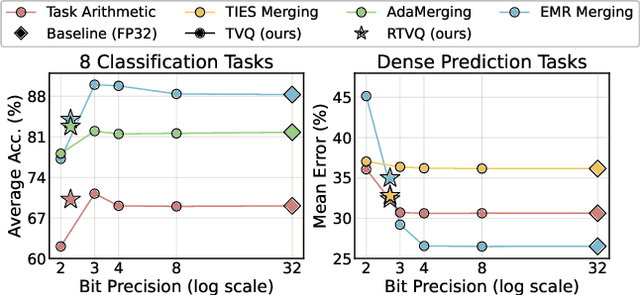
Model merging enables efficient multi-task models by combining task-specific fine-tuned checkpoints. However, storing multiple task-specific checkpoints requires significant memory, limiting scalability and restricting model merging to larger models and diverse tasks. In this paper, we propose quantizing task vectors (i.e., the difference between pre-trained and fine-tuned checkpoints) instead of quantizing fine-tuned checkpoints. We observe that task vectors exhibit a narrow weight range, enabling low precision quantization (up to 4 bit) within existing task vector merging frameworks. To further mitigate quantization errors within ultra-low bit precision (e.g., 2 bit), we introduce Residual Task Vector Quantization, which decomposes the task vector into a base vector and offset component. We allocate bits based on quantization sensitivity, ensuring precision while minimizing error within a memory budget. Experiments on image classification and dense prediction show our method maintains or improves model merging performance while using only 8% of the memory required for full-precision checkpoints.
IAM: Enhancing RGB-D Instance Segmentation with New Benchmarks
Jan 03, 2025



Image segmentation is a vital task for providing human assistance and enhancing autonomy in our daily lives. In particular, RGB-D segmentation-leveraging both visual and depth cues-has attracted increasing attention as it promises richer scene understanding than RGB-only methods. However, most existing efforts have primarily focused on semantic segmentation and thus leave a critical gap. There is a relative scarcity of instance-level RGB-D segmentation datasets, which restricts current methods to broad category distinctions rather than fully capturing the fine-grained details required for recognizing individual objects. To bridge this gap, we introduce three RGB-D instance segmentation benchmarks, distinguished at the instance level. These datasets are versatile, supporting a wide range of applications from indoor navigation to robotic manipulation. In addition, we present an extensive evaluation of various baseline models on these benchmarks. This comprehensive analysis identifies both their strengths and shortcomings, guiding future work toward more robust, generalizable solutions. Finally, we propose a simple yet effective method for RGB-D data integration. Extensive evaluations affirm the effectiveness of our approach, offering a robust framework for advancing toward more nuanced scene understanding.
Tint Your Models Task-wise for Improved Multi-task Model Merging
Dec 26, 2024



Traditional model merging methods for multi-task learning (MTL) address task conflicts with straightforward strategies such as weight averaging, sign consensus, or minimal test-time adjustments. This presumably counts on the assumption that a merged encoder still retains abundant task knowledge from individual encoders, implying that its shared representation is sufficiently general across tasks. However, our insight is that adding just a single trainable task-specific layer further can bring striking performance gains, as demonstrated by our pilot study. Motivated by this finding, we propose Model Tinting, a new test-time approach that introduces a single task-specific layer for each task as trainable adjustments. Our method jointly trains merging coefficients and task-specific layers, which effectively reduces task conflicts with minimal additional costs. Additionally, we propose a sampling method that utilizes the difference in confidence levels of both merged and individual encoders. Extensive experiments demonstrate our method's effectiveness, which achieves state-of-the-art performance across both computer vision and natural language processing tasks and significantly surpasses prior works. Our code is available at https://github.com/AIM-SKKU/ModelTinting.