 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIAM: Enhancing RGB-D Instance Segmentation with New Benchmarks
Jan 03, 2025



Image segmentation is a vital task for providing human assistance and enhancing autonomy in our daily lives. In particular, RGB-D segmentation-leveraging both visual and depth cues-has attracted increasing attention as it promises richer scene understanding than RGB-only methods. However, most existing efforts have primarily focused on semantic segmentation and thus leave a critical gap. There is a relative scarcity of instance-level RGB-D segmentation datasets, which restricts current methods to broad category distinctions rather than fully capturing the fine-grained details required for recognizing individual objects. To bridge this gap, we introduce three RGB-D instance segmentation benchmarks, distinguished at the instance level. These datasets are versatile, supporting a wide range of applications from indoor navigation to robotic manipulation. In addition, we present an extensive evaluation of various baseline models on these benchmarks. This comprehensive analysis identifies both their strengths and shortcomings, guiding future work toward more robust, generalizable solutions. Finally, we propose a simple yet effective method for RGB-D data integration. Extensive evaluations affirm the effectiveness of our approach, offering a robust framework for advancing toward more nuanced scene understanding.
Spatio-channel Attention Blocks for Cross-modal Crowd Counting
Oct 19, 2022
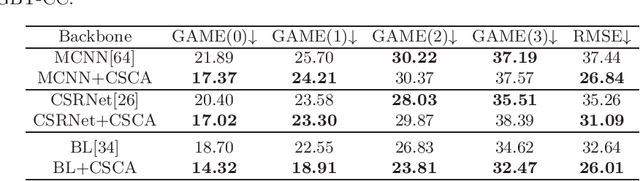
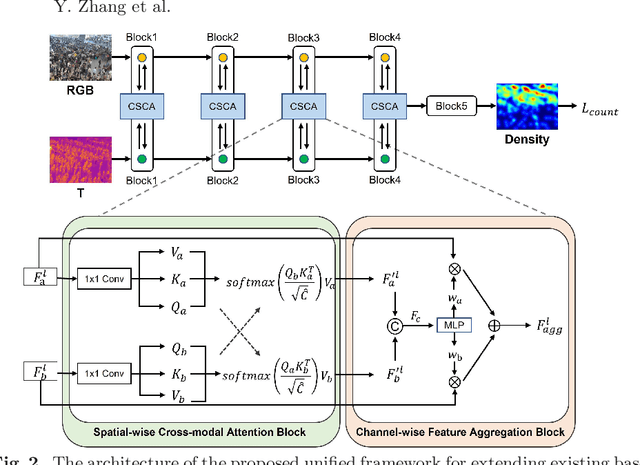
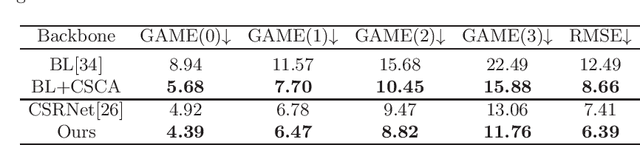
Crowd counting research has made significant advancements in real-world applications, but it remains a formidable challenge in cross-modal settings. Most existing methods rely solely on the optical features of RGB images, ignoring the feasibility of other modalities such as thermal and depth images. The inherently significant differences between the different modalities and the diversity of design choices for model architectures make cross-modal crowd counting more challenging. In this paper, we propose Cross-modal Spatio-Channel Attention (CSCA) blocks, which can be easily integrated into any modality-specific architecture. The CSCA blocks first spatially capture global functional correlations among multi-modality with less overhead through spatial-wise cross-modal attention. Cross-modal features with spatial attention are subsequently refined through adaptive channel-wise feature aggregation. In our experiments, the proposed block consistently shows significant performance improvement across various backbone networks, resulting in state-of-the-art results in RGB-T and RGB-D crowd counting.