 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-channel Attention Blocks for Cross-modal Crowd Counting
Paper and Code

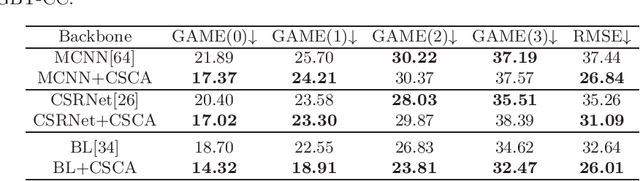
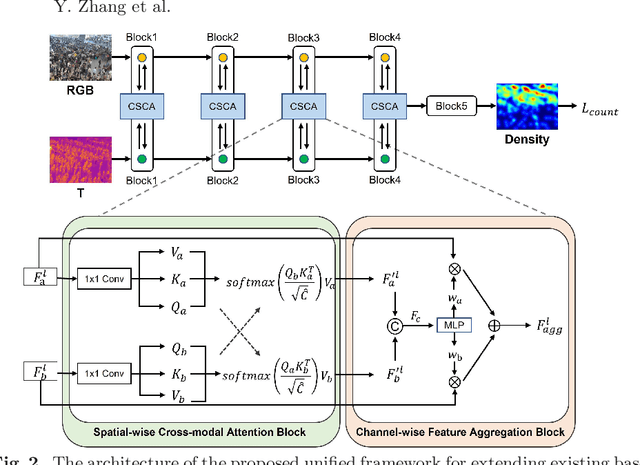
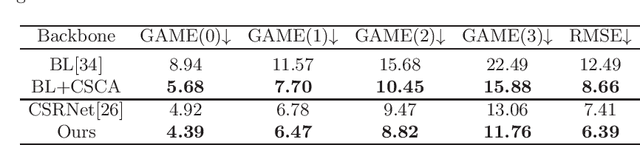
Crowd counting research has made significant advancements in real-world applications, but it remains a formidable challenge in cross-modal settings. Most existing methods rely solely on the optical features of RGB images, ignoring the feasibility of other modalities such as thermal and depth images. The inherently significant differences between the different modalities and the diversity of design choices for model architectures make cross-modal crowd counting more challenging. In this paper, we propose Cross-modal Spatio-Channel Attention (CSCA) blocks, which can be easily integrated into any modality-specific architecture. The CSCA blocks first spatially capture global functional correlations among multi-modality with less overhead through spatial-wise cross-modal attention. Cross-modal features with spatial attention are subsequently refined through adaptive channel-wise feature aggregation. In our experiments, the proposed block consistently shows significant performance improvement across various backbone networks, resulting in state-of-the-art results in RGB-T and RGB-D crowd counting.