 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeMoF: Level-guided Multimodal Fusion for Heterogeneous Clinical Data
Jan 15, 2026Multimodal clinical prediction is widely used to integrate heterogeneous data such as Electronic Health Records (EHR) and biosignals. However, existing methods tend to rely on static modality integration schemes and simple fusion strategies. As a result, they fail to fully exploit modality-specific representations. In this paper, we propose Level-guided Modal Fusion (LeMoF), a novel framework that selectively integrates level-guided representations within each modality. Each level refers to a representation extracted from a different layer of the encoder. LeMoF explicitly separates and learns global modality-level predictions from level-specific discriminative representations. This design enables LeMoF to achieve a balanced performance between prediction stability and discriminative capability even in heterogeneous clinical environments. Experiments on length of stay prediction using Intensive Care Unit (ICU) data demonstrate that LeMoF consistently outperforms existing state-of-the-art multimodal fusion techniques across various encoder configurations. We also confirmed that level-wise integration is a key factor in achieving robust predictive performance across various clinical conditions.
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
Cycled Compositional Learning between Images and Text
Jul 24, 2021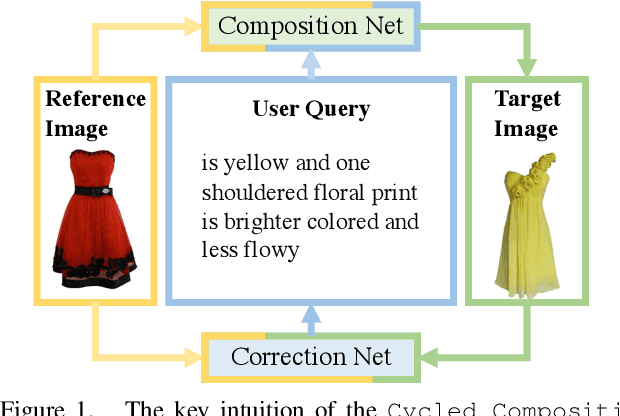
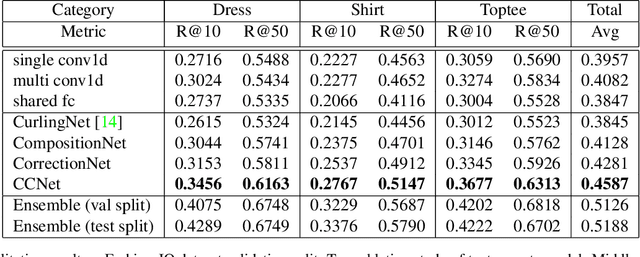
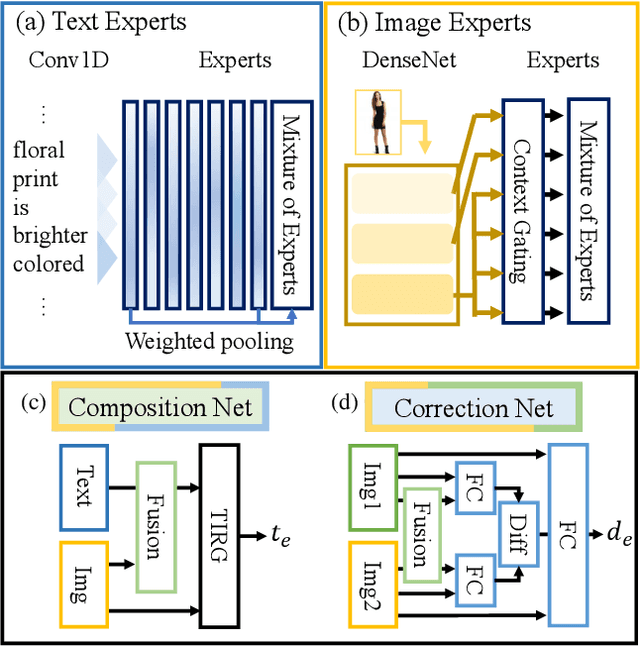
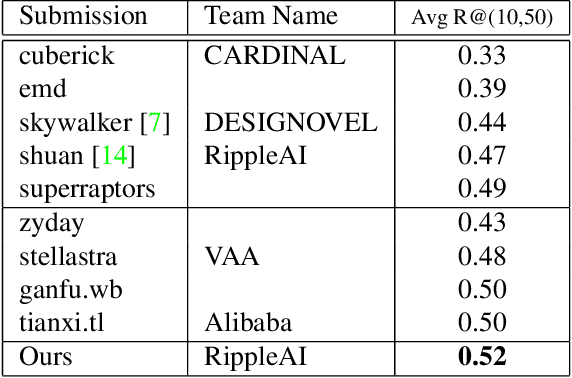
We present an approach named the Cycled Composition Network that can measure the semantic distance of the composition of image-text embedding. First, the Composition Network transit a reference image to target image in an embedding space using relative caption. Second, the Correction Network calculates a difference between reference and retrieved target images in the embedding space and match it with a relative caption. Our goal is to learn a Composition mapping with the Composition Network. Since this one-way mapping is highly under-constrained, we couple it with an inverse relation learning with the Correction Network and introduce a cycled relation for given Image We participate in Fashion IQ 2020 challenge and have won the first place with the ensemble of our model.
A Joint Sequence Fusion Model for Video Question Answering and Retrieval
Aug 07, 2018

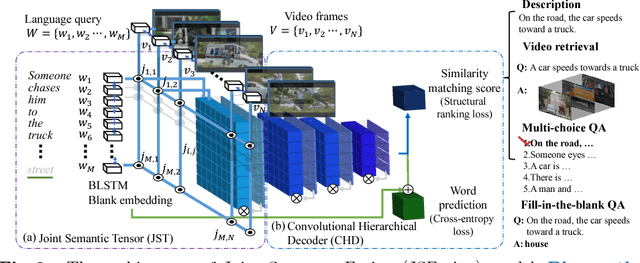
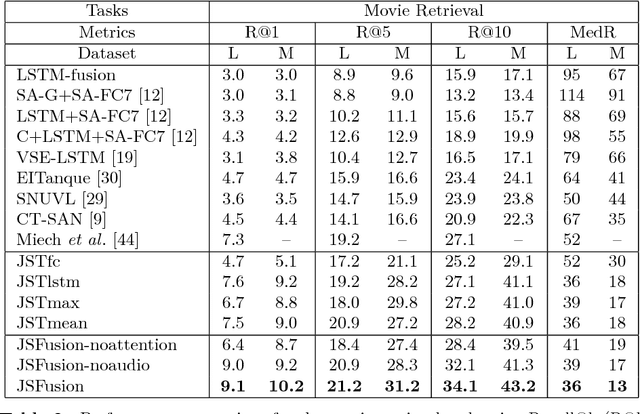
We present an approach named JSFusion (Joint Sequence Fusion) that can measure semantic similarity between any pairs of multimodal sequence data (e.g. a video clip and a language sentence). Our multimodal matching network consists of two key components. First, the Joint Semantic Tensor composes a dense pairwise representation of two sequence data into a 3D tensor. Then, the Convolutional Hierarchical Decoder computes their similarity score by discovering hidden hierarchical matches between the two sequence modalities. Both modules leverage hierarchical attention mechanisms that learn to promote well-matched representation patterns while prune out misaligned ones in a bottom-up manner. Although the JSFusion is a universal model to be applicable to any multimodal sequence data, this work focuses on video-language tasks including multimodal retrieval and video QA. We evaluate the JSFusion model in three retrieval and VQA tasks in LSMDC, for which our model achieves the best performance reported so far. We also perform multiple-choice and movie retrieval tasks for the MSR-VTT dataset, on which our approach outperforms many state-of-the-art methods.