 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasping Deformable Objects via Reinforcement Learning with Cross-Modal Attention to Visuo-Tactile Inputs
Paper and Code
Apr 22, 2025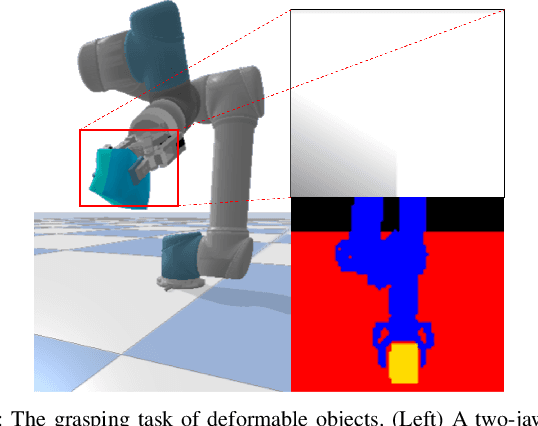
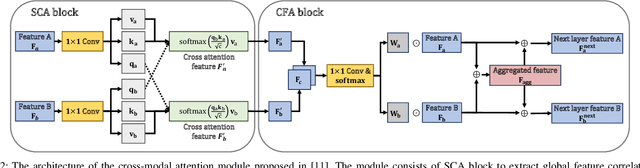
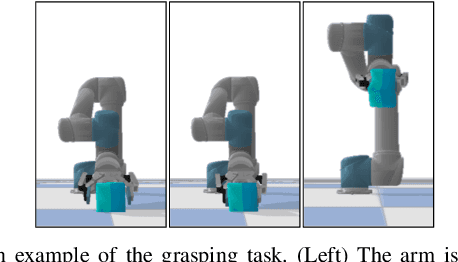
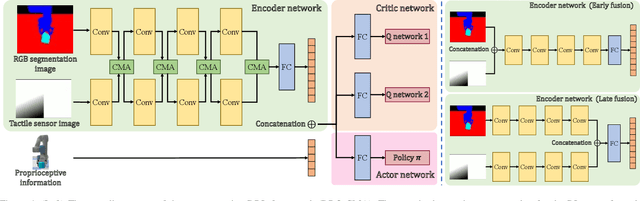
We consider the problem of grasping deformable objects with soft shells using a robotic gripper. Such objects have a center-of-mass that changes dynamically and are fragile so prone to burst. Thus, it is difficult for robots to generate appropriate control inputs not to drop or break the object while performing manipulation tasks. Multi-modal sensing data could help understand the grasping state through global information (e.g., shapes, pose) from visual data and local information around the contact (e.g., pressure) from tactile data. Although they have complementary information that can be beneficial to use together, fusing them is difficult owing to their different properties. We propose a method based on deep reinforcement learning (DRL) that generates control inputs of a simple gripper from visuo-tactile sensing information. Our method employs a cross-modal attention module in the encoder network and trains it in a self-supervised manner using the loss function of the RL agent. With the multi-modal fusion, the proposed method can learn the representation for the DRL agent from the visuo-tactile sensory data. The experimental result shows that cross-modal attention is effective to outperform other early and late data fusion methods across different environments including unseen robot motions and objects.