 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss-based Sequential Learning for Active Domain Adaptation
Paper and Code
Apr 25, 2022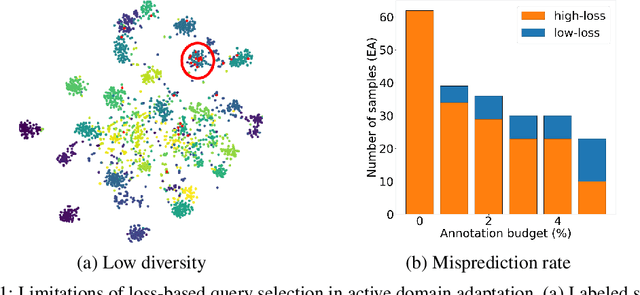

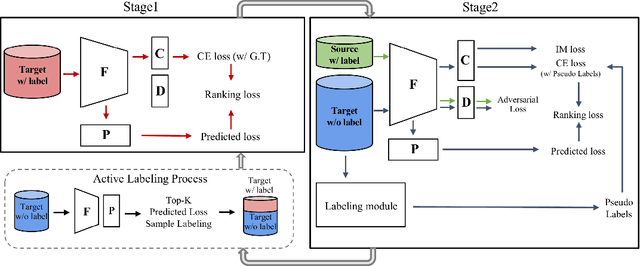
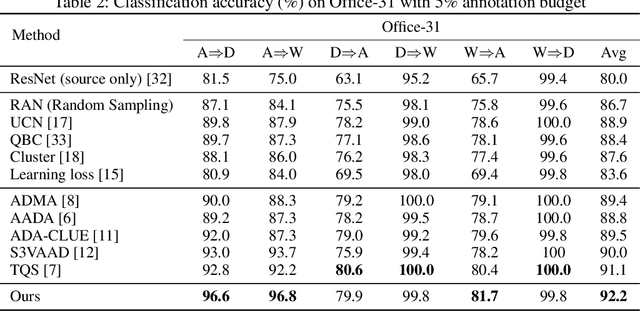
Active domain adaptation (ADA) studies have mainly addressed query selection while following existing domain adaptation strategies. However, we argue that it is critical to consider not only query selection criteria but also domain adaptation strategies designed for ADA scenarios. This paper introduces sequential learning considering both domain type (source/target) or labelness (labeled/unlabeled). We first train our model only on labeled target samples obtained by loss-based query selection. When loss-based query selection is applied under domain shift, unuseful high-loss samples gradually increase, and the labeled-sample diversity becomes low. To solve these, we fully utilize pseudo labels of the unlabeled target domain by leveraging loss prediction. We further encourage pseudo labels to have low self-entropy and diverse class distributions. Our model significantly outperforms previous methods as well as baseline models in various benchmark datasets.