 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeightLane: BEV Heightmap guided 3D Lane Detection
Paper and Code
Aug 15, 2024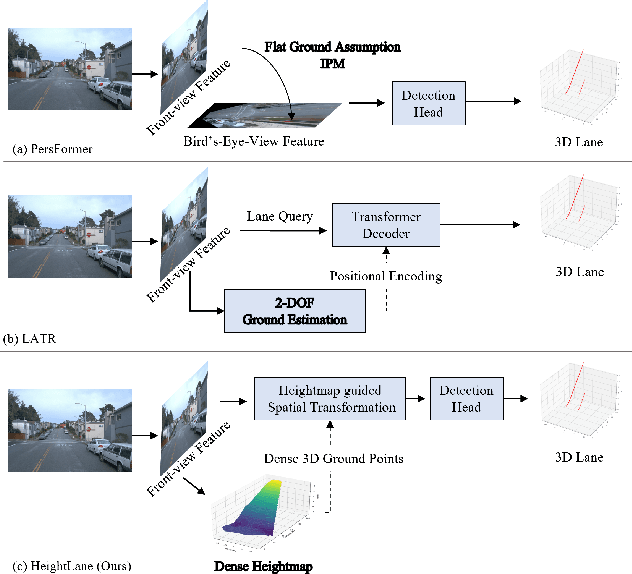
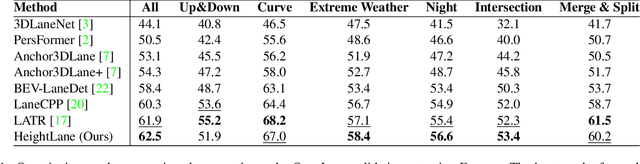
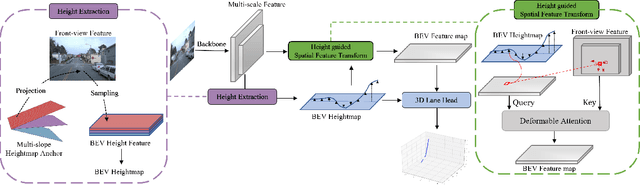
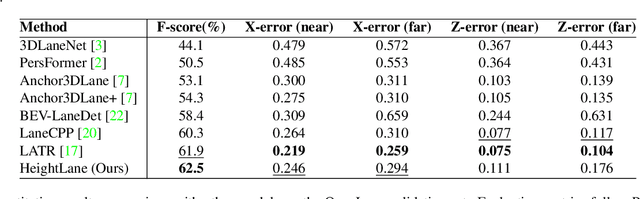
Accurate 3D lane detection from monocular images presents significant challenges due to depth ambiguity and imperfect ground modeling. Previous attempts to model the ground have often used a planar ground assumption with limited degrees of freedom, making them unsuitable for complex road environments with varying slopes. Our study introduces HeightLane, an innovative method that predicts a height map from monocular images by creating anchors based on a multi-slope assumption. This approach provides a detailed and accurate representation of the ground. HeightLane employs the predicted heightmap along with a deformable attention-based spatial feature transform framework to efficiently convert 2D image features into 3D bird's eye view (BEV) features, enhancing spatial understanding and lane structure recognition. Additionally, the heightmap is used for the positional encoding of BEV features, further improving their spatial accuracy. This explicit view transformation bridges the gap between front-view perceptions and spatially accurate BEV representations, significantly improving detection performance. To address the lack of the necessary ground truth (GT) height map in the original OpenLane dataset, we leverage the Waymo dataset and accumulate its LiDAR data to generate a height map for the drivable area of each scene. The GT heightmaps are used to train the heightmap extraction module from monocular images. Extensive experiments on the OpenLane validation set show that HeightLane achieves state-of-the-art performance in terms of F-score, highlighting its potential in real-world applications.