 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC-Lane: Slope-aware and Consistent Road Height Estimation Framework for 3D Lane Detection
Aug 14, 2025In this paper, we introduce SC-Lane, a novel slope-aware and temporally consistent heightmap estimation framework for 3D lane detection. Unlike previous approaches that rely on fixed slope anchors, SC-Lane adaptively determines the fusion of slope-specific height features, improving robustness to diverse road geometries. To achieve this, we propose a Slope-Aware Adaptive Feature module that dynamically predicts the appropriate weights from image cues for integrating multi-slope representations into a unified heightmap. Additionally, a Height Consistency Module enforces temporal coherence, ensuring stable and accurate height estimation across consecutive frames, which is crucial for real-world driving scenarios. To evaluate the effectiveness of SC-Lane, we employ three standardized metrics-Mean Absolute Error(MAE), Root Mean Squared Error (RMSE), and threshold-based accuracy-which, although common in surface and depth estimation, have been underutilized for road height assessment. Using the LiDAR-derived heightmap dataset introduced in prior work [20], we benchmark our method under these metrics, thereby establishing a rigorous standard for future comparisons. Extensive experiments on the OpenLane benchmark demonstrate that SC-Lane significantly improves both height estimation and 3D lane detection, achieving state-of-the-art performance with an F-score of 64.3%, outperforming existing methods by a notable margin. For detailed results and a demonstration video, please refer to our project page:https://parkchaesong.github.io/sclane/
HeightLane: BEV Heightmap guided 3D Lane Detection
Aug 15, 2024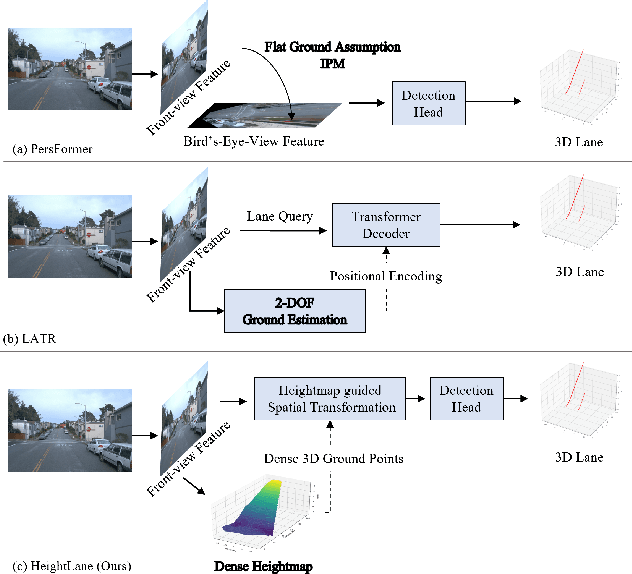
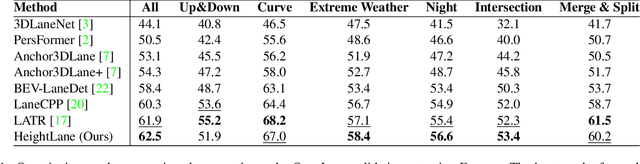
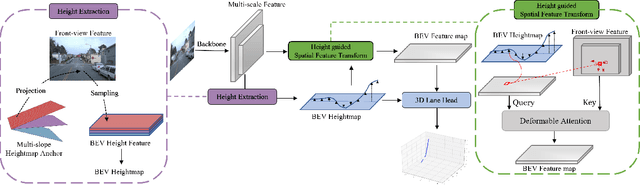
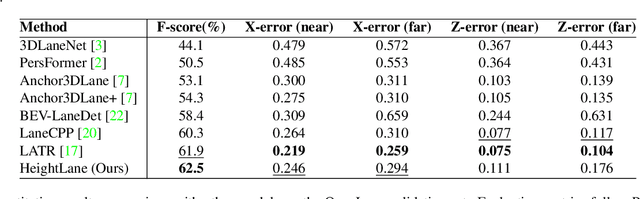
Accurate 3D lane detection from monocular images presents significant challenges due to depth ambiguity and imperfect ground modeling. Previous attempts to model the ground have often used a planar ground assumption with limited degrees of freedom, making them unsuitable for complex road environments with varying slopes. Our study introduces HeightLane, an innovative method that predicts a height map from monocular images by creating anchors based on a multi-slope assumption. This approach provides a detailed and accurate representation of the ground. HeightLane employs the predicted heightmap along with a deformable attention-based spatial feature transform framework to efficiently convert 2D image features into 3D bird's eye view (BEV) features, enhancing spatial understanding and lane structure recognition. Additionally, the heightmap is used for the positional encoding of BEV features, further improving their spatial accuracy. This explicit view transformation bridges the gap between front-view perceptions and spatially accurate BEV representations, significantly improving detection performance. To address the lack of the necessary ground truth (GT) height map in the original OpenLane dataset, we leverage the Waymo dataset and accumulate its LiDAR data to generate a height map for the drivable area of each scene. The GT heightmaps are used to train the heightmap extraction module from monocular images. Extensive experiments on the OpenLane validation set show that HeightLane achieves state-of-the-art performance in terms of F-score, highlighting its potential in real-world applications.