 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFieldscale: Locality-Aware Field-based Adaptive Rescaling for Thermal Infrared Image
May 24, 2024



Thermal infrared (TIR) cameras are emerging as promising sensors in safety-related fields due to their robustness against external illumination. However, RAW TIR image has 14 bits of pixel depth and needs to be rescaled into 8 bits for general applications. Previous works utilize a global 1D look-up table to compute pixel-wise gain solely based on its intensity, which degrades image quality by failing to consider the local nature of the heat. We propose Fieldscale, a rescaling based on locality-aware 2D fields where both the intensity value and spatial context of each pixel within an image are embedded. It can adaptively determine the pixel gain for each region and produce spatially consistent 8-bit rescaled images with minimal information loss and high visibility. Consistent performance improvement on image quality assessment and two other downstream tasks support the effectiveness and usability of Fieldscale. All the codes are publicly opened to facilitate research advancements in this field. https://github.com/hyeonjaegil/fieldscale
Imaging radar and LiDAR image translation for 3-DOF extrinsic calibration
Mar 27, 2024The integration of sensor data is crucial in the field of robotics to take full advantage of the various sensors employed. One critical aspect of this integration is determining the extrinsic calibration parameters, such as the relative transformation, between each sensor. The use of data fusion between complementary sensors, such as radar and LiDAR, can provide significant benefits, particularly in harsh environments where accurate depth data is required. However, noise included in radar sensor data can make the estimation of extrinsic calibration challenging. To address this issue, we present a novel framework for the extrinsic calibration of radar and LiDAR sensors, utilizing CycleGAN as amethod of image-to-image translation. Our proposed method employs translating radar bird-eye-view images into LiDAR-style images to estimate the 3-DOF extrinsic parameters. The use of image registration techniques, as well as deskewing based on sensor odometry and B-spline interpolation, is employed to address the rolling shutter effect commonly present in spinning sensors. Our method demonstrates a notable improvement in extrinsic calibration compared to filter-based methods using the MulRan dataset.
Unbiased Estimator for Distorted Conics in Camera Calibration
Mar 10, 2024In the literature, points and conics have been major features for camera geometric calibration. Although conics are more informative features than points, the loss of the conic property under distortion has critically limited the utility of conic features in camera calibration. Many existing approaches addressed conic-based calibration by ignoring distortion or introducing 3D spherical targets to circumvent this limitation. In this paper, we present a novel formulation for conic-based calibration using moments. Our derivation is based on the mathematical finding that the first moment can be estimated without bias even under distortion. This allows us to track moment changes during projection and distortion, ensuring the preservation of the first moment of the distorted conic. With an unbiased estimator, the circular patterns can be accurately detected at the sub-pixel level and can now be fully exploited for an entire calibration pipeline, resulting in significantly improved calibration. The entire code is readily available from https://github.com/ChaehyeonSong/discocal.
LodeStar: Maritime Radar Descriptor for Semi-Direct Radar Odometry
Mar 05, 2024



Maritime radars are prevalently adopted to capture the vessel's omnidirectional data as imagery. Nevertheless, inherent challenges persist with marine radars, including limited frequency, suboptimal resolution, and indeterminate detections. Additionally, the scarcity of discernible landmarks in the vast marine expanses remains a challenge, resulting in consecutive scenes that often lack matching feature points. In this context, we introduce a resilient maritime radar scan representation LodeStar, and an enhanced feature extraction technique tailored for marine radar applications. Moreover, we embark on estimating marine radar odometry utilizing a semi-direct approach. LodeStar-based approach markedly attenuates the errors in odometry estimation, and our assertion is corroborated through meticulous experimental validation.
* IEEE Robotics and Automation Letter
TRansPose: Large-Scale Multispectral Dataset for Transparent Object
Jul 11, 2023



Transparent objects are encountered frequently in our daily lives, yet recognizing them poses challenges for conventional vision sensors due to their unique material properties, not being well perceived from RGB or depth cameras. Overcoming this limitation, thermal infrared cameras have emerged as a solution, offering improved visibility and shape information for transparent objects. In this paper, we present TRansPose, the first large-scale multispectral dataset that combines stereo RGB-D, thermal infrared (TIR) images, and object poses to promote transparent object research. The dataset includes 99 transparent objects, encompassing 43 household items, 27 recyclable trashes, 29 chemical laboratory equivalents, and 12 non-transparent objects. It comprises a vast collection of 333,819 images and 4,000,056 annotations, providing instance-level segmentation masks, ground-truth poses, and completed depth information. The data was acquired using a FLIR A65 thermal infrared (TIR) camera, two Intel RealSense L515 RGB-D cameras, and a Franka Emika Panda robot manipulator. Spanning 87 sequences, TRansPose covers various challenging real-life scenarios, including objects filled with water, diverse lighting conditions, heavy clutter, non-transparent or translucent containers, objects in plastic bags, and multi-stacked objects. TRansPose dataset can be accessed from the following link: https://sites.google.com/view/transpose-dataset
Edge-guided Multi-domain RGB-to-TIR image Translation for Training Vision Tasks with Challenging Labels
Jan 30, 2023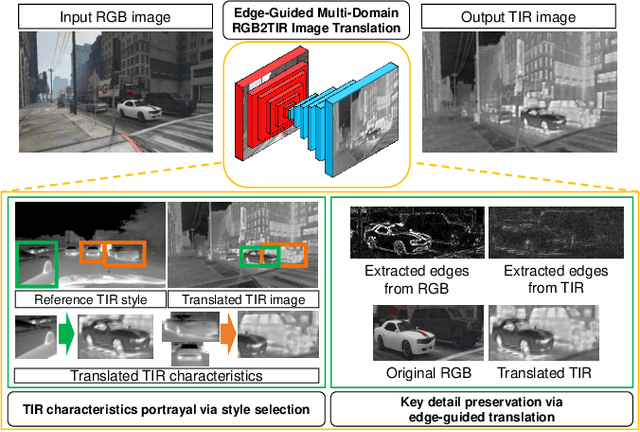
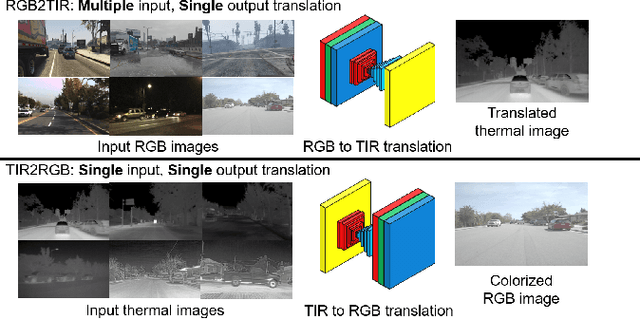


The insufficient number of annotated thermal infrared (TIR) image datasets not only hinders TIR image-based deep learning networks to have comparable performances to that of RGB but it also limits the supervised learning of TIR image-based tasks with challenging labels. As a remedy, we propose a modified multidomain RGB to TIR image translation model focused on edge preservation to employ annotated RGB images with challenging labels. Our proposed method not only preserves key details in the original image but also leverages the optimal TIR style code to portray accurate TIR characteristics in the translated image, when applied on both synthetic and real world RGB images. Using our translation model, we have enabled the supervised learning of deep TIR image-based optical flow estimation and object detection that ameliorated in deep TIR optical flow estimation by reduction in end point error by 56.5\% on average and the best object detection mAP of 23.9\% respectively. Our code and supplementary materials are available at https://github.com/rpmsnu/sRGB-TIR.
Ambiguity-Aware Multi-Object Pose Optimization for Visually-Assisted Robot Manipulation
Nov 02, 20226D object pose estimation aims to infer the relative pose between the object and the camera using a single image or multiple images. Most works have focused on predicting the object pose without associated uncertainty under occlusion and structural ambiguity (symmetricity). However, these works demand prior information about shape attributes, and this condition is hardly satisfied in reality; even asymmetric objects may be symmetric under the viewpoint change. In addition, acquiring and fusing diverse sensor data is challenging when extending them to robotics applications. Tackling these limitations, we present an ambiguity-aware 6D object pose estimation network, PrimA6D++, as a generic uncertainty prediction method. The major challenges in pose estimation, such as occlusion and symmetry, can be handled in a generic manner based on the measured ambiguity of the prediction. Specifically, we devise a network to reconstruct the three rotation axis primitive images of a target object and predict the underlying uncertainty along each primitive axis. Leveraging the estimated uncertainty, we then optimize multi-object poses using visual measurements and camera poses by treating it as an object SLAM problem. The proposed method shows a significant performance improvement in T-LESS and YCB-Video datasets. We further demonstrate real-time scene recognition capability for visually-assisted robot manipulation. Our code and supplementary materials are available at https://github.com/rpmsnu/PrimA6D.
PrimA6D: Rotational Primitive Reconstruction for Enhanced and Robust 6D Pose Estimation
Jul 03, 2020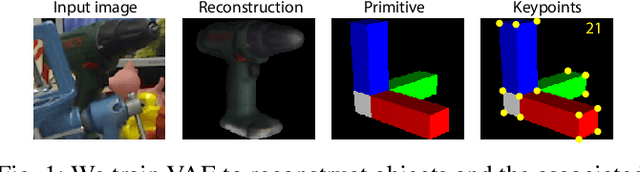
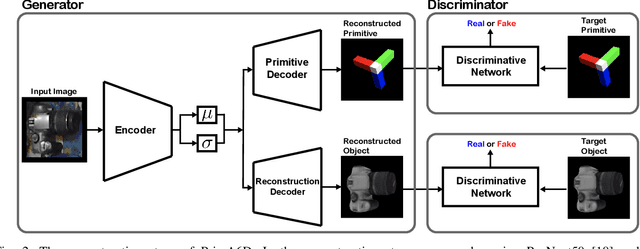
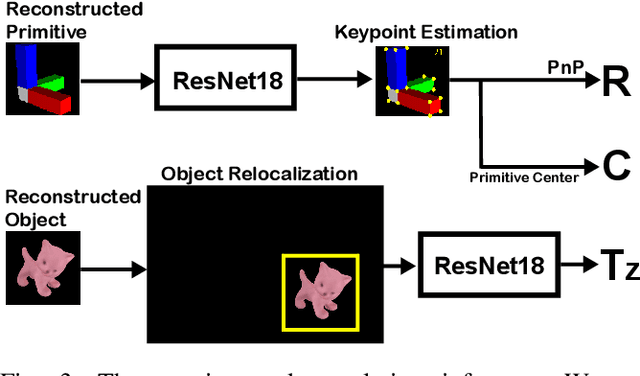

In this paper, we introduce a rotational primitive prediction based 6D object pose estimation using a single image as an input. We solve for the 6D object pose of a known object relative to the camera using a single image with occlusion. Many recent state-of-the-art (SOTA) two-step approaches have exploited image keypoints extraction followed by PnP regression for pose estimation. Instead of relying on bounding box or keypoints on the object, we propose to learn orientation-induced primitive so as to achieve the pose estimation accuracy regardless of the object size. We leverage a Variational AutoEncoder (VAE) to learn this underlying primitive and its associated keypoints. The keypoints inferred from the reconstructed primitive image are then used to regress the rotation using PnP. Lastly, we compute the translation in a separate localization module to complete the entire 6D pose estimation. When evaluated over public datasets, the proposed method yields a notable improvement over the LINEMOD, the Occlusion LINEMOD, and the YCB-Video dataset. We further provide a synthetic-only trained case presenting comparable performance to the existing methods which require real images in the training phase.