 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClutt3R-Seg: Sparse-view 3D Instance Segmentation for Language-grounded Grasping in Cluttered Scenes
Feb 12, 2026Reliable 3D instance segmentation is fundamental to language-grounded robotic manipulation. Its critical application lies in cluttered environments, where occlusions, limited viewpoints, and noisy masks degrade perception. To address these challenges, we present Clutt3R-Seg, a zero-shot pipeline for robust 3D instance segmentation for language-grounded grasping in cluttered scenes. Our key idea is to introduce a hierarchical instance tree of semantic cues. Unlike prior approaches that attempt to refine noisy masks, our method leverages them as informative cues: through cross-view grouping and conditional substitution, the tree suppresses over- and under-segmentation, yielding view-consistent masks and robust 3D instances. Each instance is enriched with open-vocabulary semantic embeddings, enabling accurate target selection from natural language instructions. To handle scene changes during multi-stage tasks, we further introduce a consistency-aware update that preserves instance correspondences from only a single post-interaction image, allowing efficient adaptation without rescanning. Clutt3R-Seg is evaluated on both synthetic and real-world datasets, and validated on a real robot. Across all settings, it consistently outperforms state-of-the-art baselines in cluttered and sparse-view scenarios. Even on the most challenging heavy-clutter sequences, Clutt3R-Seg achieves an AP@25 of 61.66, over 2.2x higher than baselines, and with only four input views it surpasses MaskClustering with eight views by more than 2x. The code is available at: https://github.com/jeonghonoh/clutt3r-seg.
Informative Object-centric Next Best View for Object-aware 3D Gaussian Splatting in Cluttered Scenes
Feb 09, 2026In cluttered scenes with inevitable occlusions and incomplete observations, selecting informative viewpoints is essential for building a reliable representation. In this context, 3D Gaussian Splatting (3DGS) offers a distinct advantage, as it can explicitly guide the selection of subsequent viewpoints and then refine the representation with new observations. However, existing approaches rely solely on geometric cues, neglect manipulation-relevant semantics, and tend to prioritize exploitation over exploration. To tackle these limitations, we introduce an instance-aware Next Best View (NBV) policy that prioritizes underexplored regions by leveraging object features. Specifically, our object-aware 3DGS distills instancelevel information into one-hot object vectors, which are used to compute confidence-weighted information gain that guides the identification of regions associated with erroneous and uncertain Gaussians. Furthermore, our method can be easily adapted to an object-centric NBV, which focuses view selection on a target object, thereby improving reconstruction robustness to object placement. Experiments demonstrate that our NBV policy reduces depth error by up to 77.14% on the synthetic dataset and 34.10% on the real-world GraspNet dataset compared to baselines. Moreover, compared to targeting the entire scene, performing NBV on a specific object yields an additional reduction of 25.60% in depth error for that object. We further validate the effectiveness of our approach through real-world robotic manipulation tasks.
TranSplat: Surface Embedding-guided 3D Gaussian Splatting for Transparent Object Manipulation
Feb 11, 2025



Transparent object manipulation remains a sig- nificant challenge in robotics due to the difficulty of acquiring accurate and dense depth measurements. Conventional depth sensors often fail with transparent objects, resulting in in- complete or erroneous depth data. Existing depth completion methods struggle with interframe consistency and incorrectly model transparent objects as Lambertian surfaces, leading to poor depth reconstruction. To address these challenges, we propose TranSplat, a surface embedding-guided 3D Gaussian Splatting method tailored for transparent objects. TranSplat uses a latent diffusion model to generate surface embeddings that provide consistent and continuous representations, making it robust to changes in viewpoint and lighting. By integrating these surface embeddings with input RGB images, TranSplat effectively captures the complexities of transparent surfaces, enhancing the splatting of 3D Gaussians and improving depth completion. Evaluations on synthetic and real-world transpar- ent object benchmarks, as well as robot grasping tasks, show that TranSplat achieves accurate and dense depth completion, demonstrating its effectiveness in practical applications. We open-source synthetic dataset and model: https://github. com/jeongyun0609/TranSplat
Thermal Chameleon: Task-Adaptive Tone-mapping for Radiometric Thermal-Infrared images
Oct 24, 2024



Thermal Infrared (TIR) imaging provides robust perception for navigating in challenging outdoor environments but faces issues with poor texture and low image contrast due to its 14/16-bit format. Conventional methods utilize various tone-mapping methods to enhance contrast and photometric consistency of TIR images, however, the choice of tone-mapping is largely dependent on knowing the task and temperature dependent priors to work well. In this paper, we present Thermal Chameleon Network (TCNet), a task-adaptive tone-mapping approach for RAW 14-bit TIR images. Given the same image, TCNet tone-maps different representations of TIR images tailored for each specific task, eliminating the heuristic image rescaling preprocessing and reliance on the extensive prior knowledge of the scene temperature or task-specific characteristics. TCNet exhibits improved generalization performance across object detection and monocular depth estimation, with minimal computational overhead and modular integration to existing architectures for various tasks. Project Page: https://github.com/donkeymouse/ThermalChameleon
TRansPose: Large-Scale Multispectral Dataset for Transparent Object
Jul 11, 2023



Transparent objects are encountered frequently in our daily lives, yet recognizing them poses challenges for conventional vision sensors due to their unique material properties, not being well perceived from RGB or depth cameras. Overcoming this limitation, thermal infrared cameras have emerged as a solution, offering improved visibility and shape information for transparent objects. In this paper, we present TRansPose, the first large-scale multispectral dataset that combines stereo RGB-D, thermal infrared (TIR) images, and object poses to promote transparent object research. The dataset includes 99 transparent objects, encompassing 43 household items, 27 recyclable trashes, 29 chemical laboratory equivalents, and 12 non-transparent objects. It comprises a vast collection of 333,819 images and 4,000,056 annotations, providing instance-level segmentation masks, ground-truth poses, and completed depth information. The data was acquired using a FLIR A65 thermal infrared (TIR) camera, two Intel RealSense L515 RGB-D cameras, and a Franka Emika Panda robot manipulator. Spanning 87 sequences, TRansPose covers various challenging real-life scenarios, including objects filled with water, diverse lighting conditions, heavy clutter, non-transparent or translucent containers, objects in plastic bags, and multi-stacked objects. TRansPose dataset can be accessed from the following link: https://sites.google.com/view/transpose-dataset
Ambiguity-Aware Multi-Object Pose Optimization for Visually-Assisted Robot Manipulation
Nov 02, 20226D object pose estimation aims to infer the relative pose between the object and the camera using a single image or multiple images. Most works have focused on predicting the object pose without associated uncertainty under occlusion and structural ambiguity (symmetricity). However, these works demand prior information about shape attributes, and this condition is hardly satisfied in reality; even asymmetric objects may be symmetric under the viewpoint change. In addition, acquiring and fusing diverse sensor data is challenging when extending them to robotics applications. Tackling these limitations, we present an ambiguity-aware 6D object pose estimation network, PrimA6D++, as a generic uncertainty prediction method. The major challenges in pose estimation, such as occlusion and symmetry, can be handled in a generic manner based on the measured ambiguity of the prediction. Specifically, we devise a network to reconstruct the three rotation axis primitive images of a target object and predict the underlying uncertainty along each primitive axis. Leveraging the estimated uncertainty, we then optimize multi-object poses using visual measurements and camera poses by treating it as an object SLAM problem. The proposed method shows a significant performance improvement in T-LESS and YCB-Video datasets. We further demonstrate real-time scene recognition capability for visually-assisted robot manipulation. Our code and supplementary materials are available at https://github.com/rpmsnu/PrimA6D.
SC-LiDAR-SLAM: a Front-end Agnostic Versatile LiDAR SLAM System
Jan 17, 2022
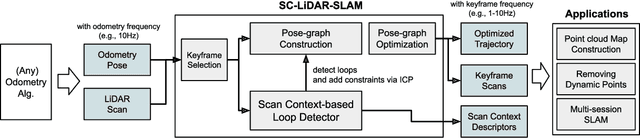

Accurate 3D point cloud map generation is a core task for various robot missions or even for data-driven urban analysis. To do so, light detection and ranging (LiDAR) sensor-based simultaneous localization and mapping (SLAM) technology have been elaborated. To compose a full SLAM system, many odometry and place recognition methods have independently been proposed in academia. However, they have hardly been integrated or too tightly combined so that exchanging (upgrading) either single odometry or place recognition module is very effort demanding. Recently, the performance of each module has been improved a lot, so it is necessary to build a SLAM system that can effectively integrate them and easily replace them with the latest one. In this paper, we release such a front-end agnostic LiDAR SLAM system, named SC-LiDAR-SLAM. We built a complete SLAM system by designing it modular, and successfully integrating it with Scan Context++ and diverse existing opensource LiDAR odometry methods to generate an accurate point cloud map