 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

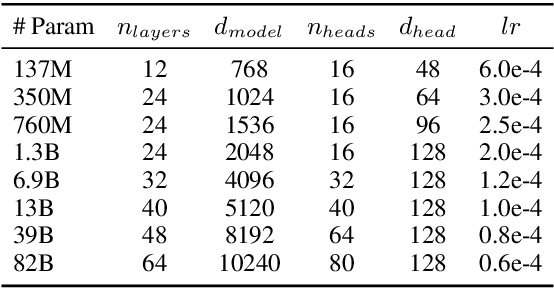
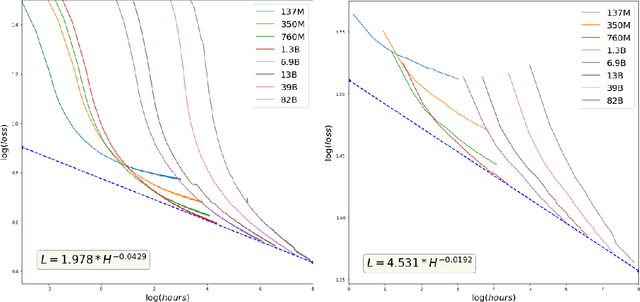
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.
torchgpipe: On-the-fly Pipeline Parallelism for Training Giant Models
Apr 21, 2020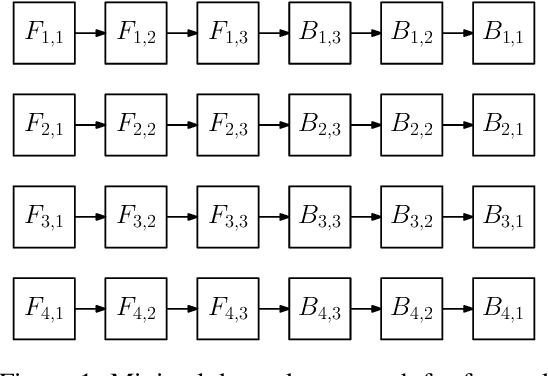

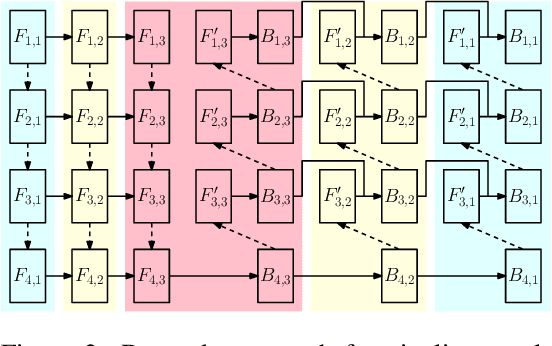
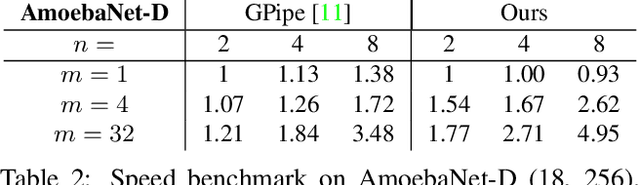
We design and implement a ready-to-use library in PyTorch for performing micro-batch pipeline parallelism with checkpointing proposed by GPipe (Huang et al., 2019). In particular, we develop a set of design components to enable pipeline-parallel gradient computation in PyTorch's define-by-run and eager execution environment. We show that each component is necessary to fully benefit from pipeline parallelism in such environment, and demonstrate the efficiency of the library by applying it to various network architectures including AmoebaNet-D and U-Net. Our library is available at https://github.com/kakaobrain/torchgpipe .