 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially Attentive Output Layer for Image Classification
Paper and Code
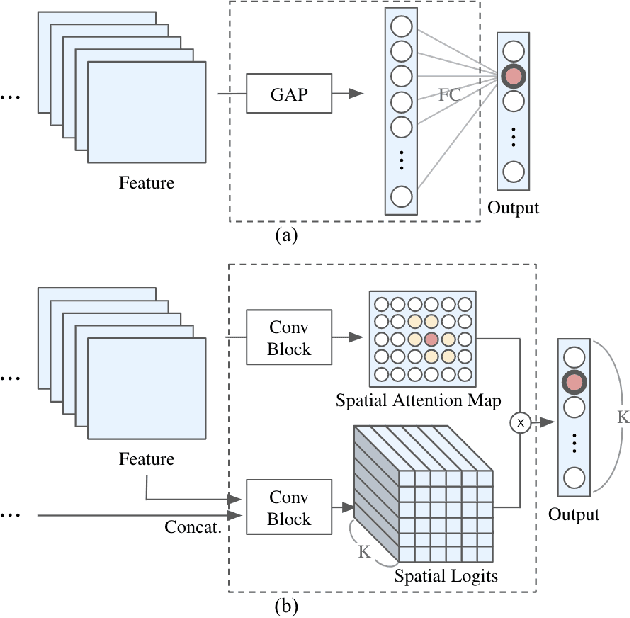
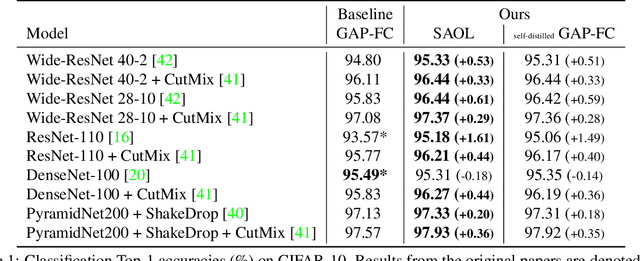
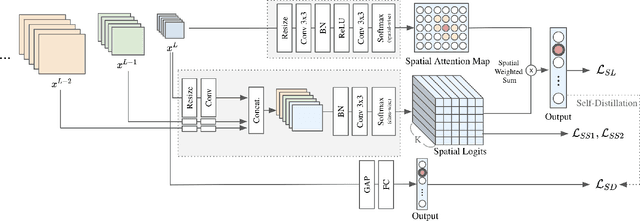
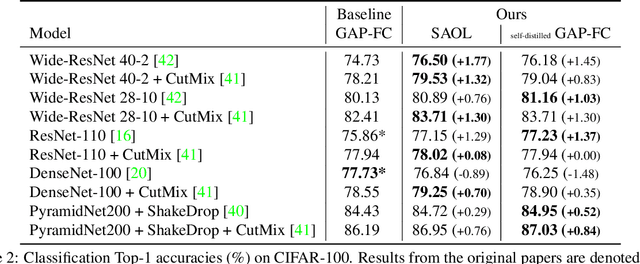
Most convolutional neural networks (CNNs) for image classification use a global average pooling (GAP) followed by a fully-connected (FC) layer for output logits. However, this spatial aggregation procedure inherently restricts the utilization of location-specific information at the output layer, although this spatial information can be beneficial for classification. In this paper, we propose a novel spatial output layer on top of the existing convolutional feature maps to explicitly exploit the location-specific output information. In specific, given the spatial feature maps, we replace the previous GAP-FC layer with a spatially attentive output layer (SAOL) by employing a attention mask on spatial logits. The proposed location-specific attention selectively aggregates spatial logits within a target region, which leads to not only the performance improvement but also spatially interpretable outputs. Moreover, the proposed SAOL also permits to fully exploit location-specific self-supervision as well as self-distillation to enhance the generalization ability during training. The proposed SAOL with self-supervision and self-distillation can be easily plugged into existing CNNs. Experimental results on various classification tasks with representative architectures show consistent performance improvements by SAOL at almost the same computational cost.