 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Quantization Errors Due to Activation Spikes in GLU-Based LLMs
Paper and Code
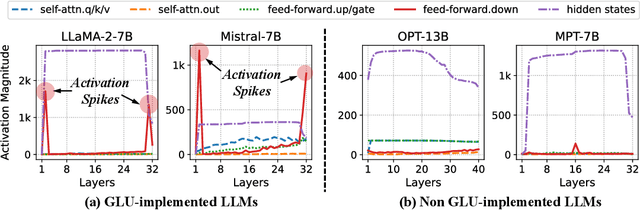
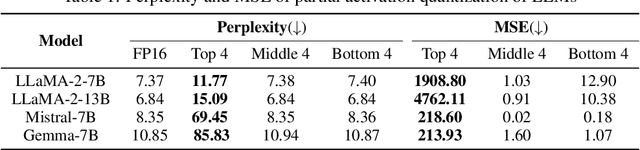
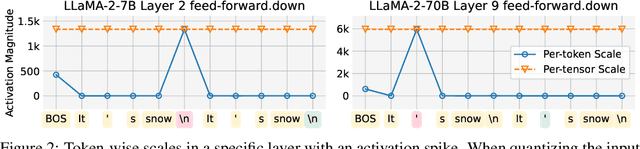
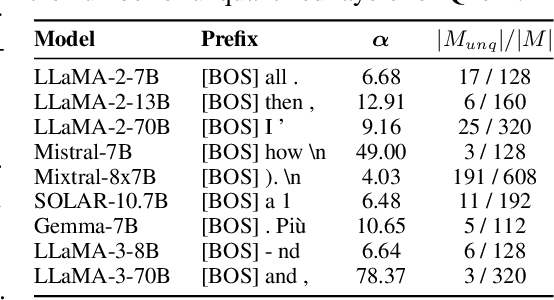
Modern large language models (LLMs) have established state-of-the-art performance through architectural improvements, but still require significant computational cost for inference. In an effort to reduce the inference cost, post-training quantization (PTQ) has become a popular approach, quantizing weights and activations to lower precision, such as INT8. In this paper, we reveal the challenges of activation quantization in GLU variants, which are widely used in feed-forward network (FFN) of modern LLMs, such as LLaMA family. The problem is that severe local quantization errors, caused by excessive magnitudes of activation in GLU variants, significantly degrade the performance of the quantized LLM. We denote these activations as activation spikes. Our further observations provide a systematic pattern of activation spikes: 1) The activation spikes occur in the FFN of specific layers, particularly in the early and late layers, 2) The activation spikes are dedicated to a couple of tokens, rather than being shared across a sequence. Based on our observations, we propose two empirical methods, Quantization-free Module (QFeM) and Quantization-free Prefix (QFeP), to isolate the activation spikes during quantization. Our extensive experiments validate the effectiveness of the proposed methods for the activation quantization, especially with coarse-grained scheme, of latest LLMs with GLU variants, including LLaMA-2/3, Mistral, Mixtral, SOLAR, and Gemma. In particular, our methods enhance the current alleviation techniques (e.g., SmoothQuant) that fail to control the activation spikes. Code is available at https://github.com/onnoo/activation-spikes.