 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Hallucination for Video Captioning
Paper and Code
Sep 28, 2022
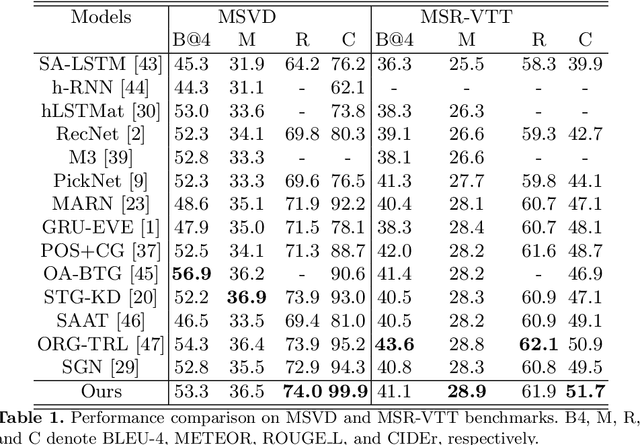
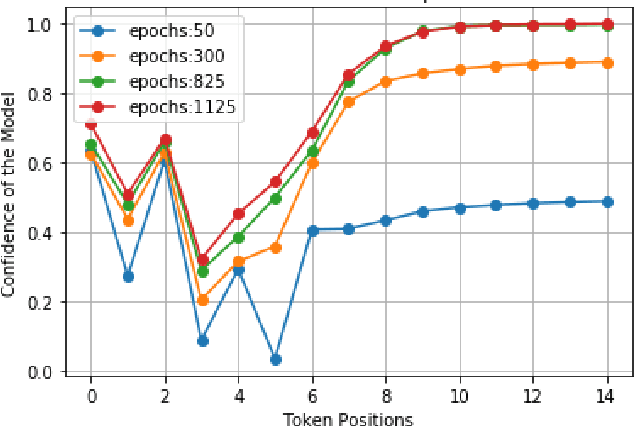
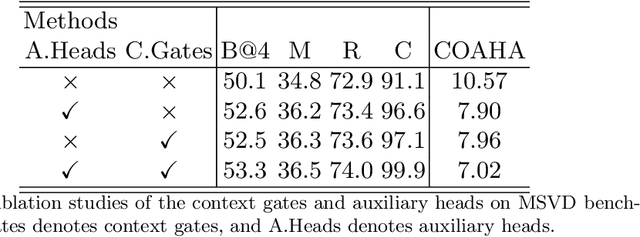
With the advent of rich visual representations and pre-trained language models, video captioning has seen continuous improvement over time. Despite the performance improvement, video captioning models are prone to hallucination. Hallucination refers to the generation of highly pathological descriptions that are detached from the source material. In video captioning, there are two kinds of hallucination: object and action hallucination. Instead of endeavoring to learn better representations of a video, in this work, we investigate the fundamental sources of the hallucination problem. We identify three main factors: (i) inadequate visual features extracted from pre-trained models, (ii) improper influences of source and target contexts during multi-modal fusion, and (iii) exposure bias in the training strategy. To alleviate these problems, we propose two robust solutions: (a) the introduction of auxiliary heads trained in multi-label settings on top of the extracted visual features and (b) the addition of context gates, which dynamically select the features during fusion. The standard evaluation metrics for video captioning measures similarity with ground truth captions and do not adequately capture object and action relevance. To this end, we propose a new metric, COAHA (caption object and action hallucination assessment), which assesses the degree of hallucination. Our method achieves state-of-the-art performance on the MSR-Video to Text (MSR-VTT) and the Microsoft Research Video Description Corpus (MSVD) datasets, especially by a massive margin in CIDEr score.