 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDEC : Unified Dual Encoder and Classifier Training for Extreme Multi-Label Classification
May 04, 2024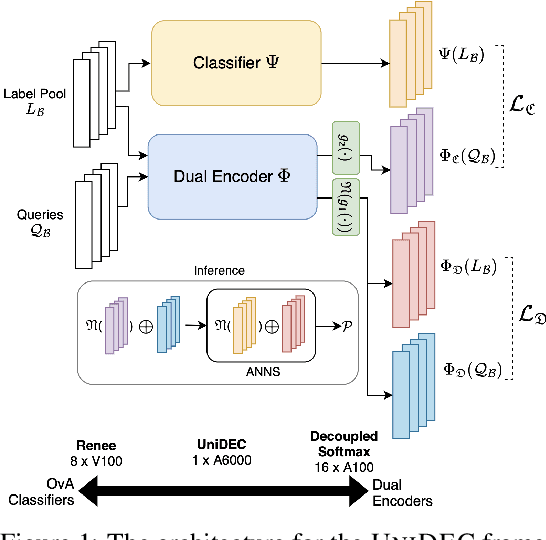
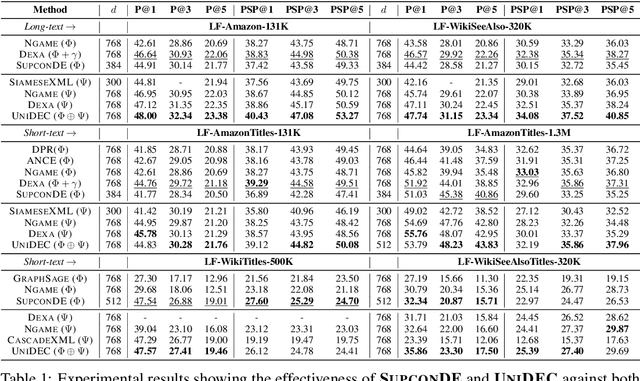
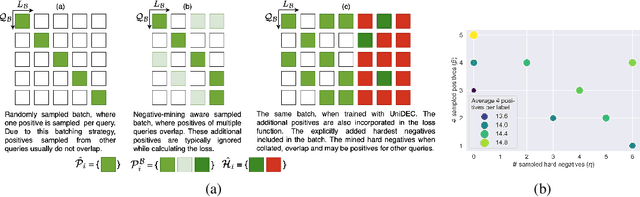
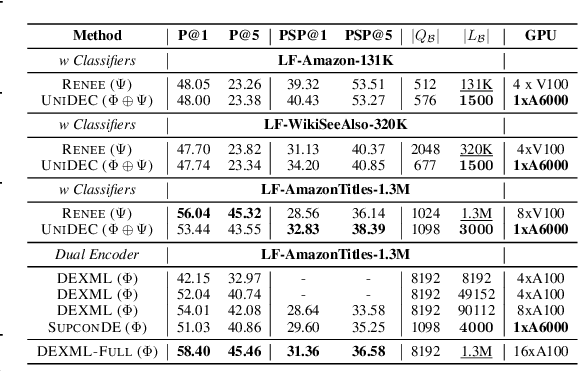
Extreme Multi-label Classification (XMC) involves predicting a subset of relevant labels from an extremely large label space, given an input query and labels with textual features. Models developed for this problem have conventionally used modular approach with (i) a Dual Encoder (DE) to embed the queries and label texts, (ii) a One-vs-All classifier to rerank the shortlisted labels mined through meta-classifier training. While such methods have shown empirical success, we observe two key uncharted aspects, (i) DE training typically uses only a single positive relation even for datasets which offer more, (ii) existing approaches fixate on using only OvA reduction of the multi-label problem. This work aims to explore these aspects by proposing UniDEC, a novel end-to-end trainable framework which trains the dual encoder and classifier in together in a unified fashion using a multi-class loss. For the choice of multi-class loss, the work proposes a novel pick-some-label (PSL) reduction of the multi-label problem with leverages multiple (in come cases, all) positives. The proposed framework achieves state-of-the-art results on a single GPU, while achieving on par results with respect to multi-GPU SOTA methods on various XML benchmark datasets, all while using 4-16x lesser compute and being practically scalable even beyond million label scale datasets.
Learning label-label correlations in Extreme Multi-label Classification via Label Features
May 03, 2024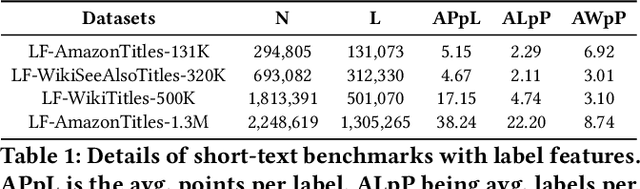
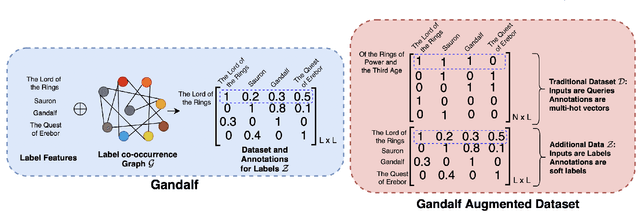
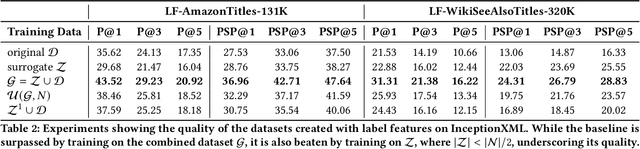
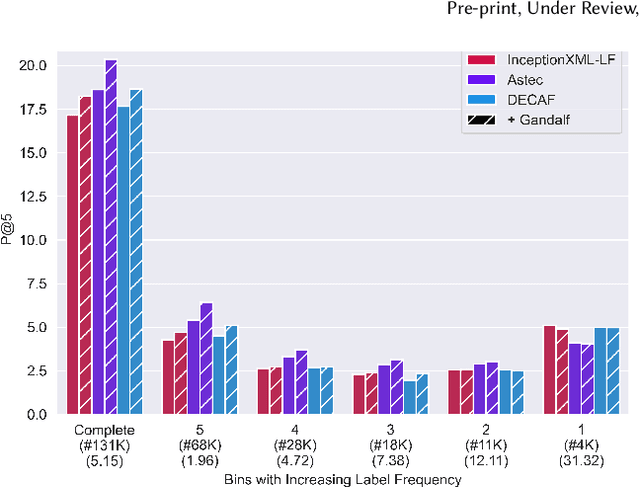
Extreme Multi-label Text Classification (XMC) involves learning a classifier that can assign an input with a subset of most relevant labels from millions of label choices. Recent works in this domain have increasingly focused on a symmetric problem setting where both input instances and label features are short-text in nature. Short-text XMC with label features has found numerous applications in areas such as query-to-ad-phrase matching in search ads, title-based product recommendation, prediction of related searches. In this paper, we propose Gandalf, a novel approach which makes use of a label co-occurrence graph to leverage label features as additional data points to supplement the training distribution. By exploiting the characteristics of the short-text XMC problem, it leverages the label features to construct valid training instances, and uses the label graph for generating the corresponding soft-label targets, hence effectively capturing the label-label correlations. Surprisingly, models trained on these new training instances, although being less than half of the original dataset, can outperform models trained on the original dataset, particularly on the PSP@k metric for tail labels. With this insight, we aim to train existing XMC algorithms on both, the original and new training instances, leading to an average 5% relative improvements for 6 state-of-the-art algorithms across 4 benchmark datasets consisting of up to 1.3M labels. Gandalf can be applied in a plug-and-play manner to various methods and thus forwards the state-of-the-art in the domain, without incurring any additional computational overheads.
CLIPTrans: Transferring Visual Knowledge with Pre-trained Models for Multimodal Machine Translation
Aug 29, 2023There has been a growing interest in developing multimodal machine translation (MMT) systems that enhance neural machine translation (NMT) with visual knowledge. This problem setup involves using images as auxiliary information during training, and more recently, eliminating their use during inference. Towards this end, previous works face a challenge in training powerful MMT models from scratch due to the scarcity of annotated multilingual vision-language data, especially for low-resource languages. Simultaneously, there has been an influx of multilingual pre-trained models for NMT and multimodal pre-trained models for vision-language tasks, primarily in English, which have shown exceptional generalisation ability. However, these are not directly applicable to MMT since they do not provide aligned multimodal multilingual features for generative tasks. To alleviate this issue, instead of designing complex modules for MMT, we propose CLIPTrans, which simply adapts the independently pre-trained multimodal M-CLIP and the multilingual mBART. In order to align their embedding spaces, mBART is conditioned on the M-CLIP features by a prefix sequence generated through a lightweight mapping network. We train this in a two-stage pipeline which warms up the model with image captioning before the actual translation task. Through experiments, we demonstrate the merits of this framework and consequently push forward the state-of-the-art across standard benchmarks by an average of +2.67 BLEU. The code can be found at www.github.com/devaansh100/CLIPTrans.
CascadeXML: Rethinking Transformers for End-to-end Multi-resolution Training in Extreme Multi-label Classification
Oct 29, 2022Extreme Multi-label Text Classification (XMC) involves learning a classifier that can assign an input with a subset of most relevant labels from millions of label choices. Recent approaches, such as XR-Transformer and LightXML, leverage a transformer instance to achieve state-of-the-art performance. However, in this process, these approaches need to make various trade-offs between performance and computational requirements. A major shortcoming, as compared to the Bi-LSTM based AttentionXML, is that they fail to keep separate feature representations for each resolution in a label tree. We thus propose CascadeXML, an end-to-end multi-resolution learning pipeline, which can harness the multi-layered architecture of a transformer model for attending to different label resolutions with separate feature representations. CascadeXML significantly outperforms all existing approaches with non-trivial gains obtained on benchmark datasets consisting of up to three million labels. Code for CascadeXML will be made publicly available at \url{https://github.com/xmc-aalto/cascadexml}.
Embedding Convolutions for Short Text Extreme Classification with Millions of Labels
Sep 13, 2021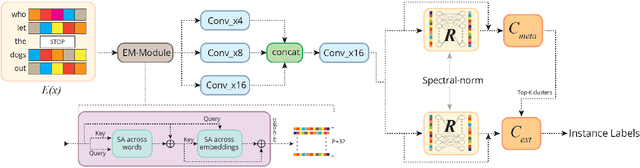

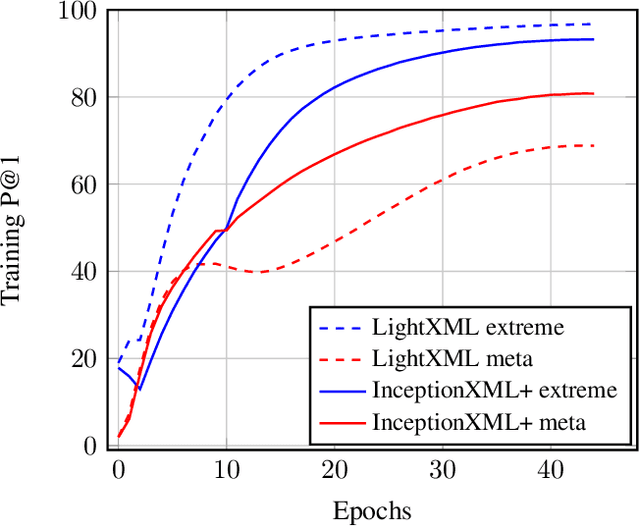
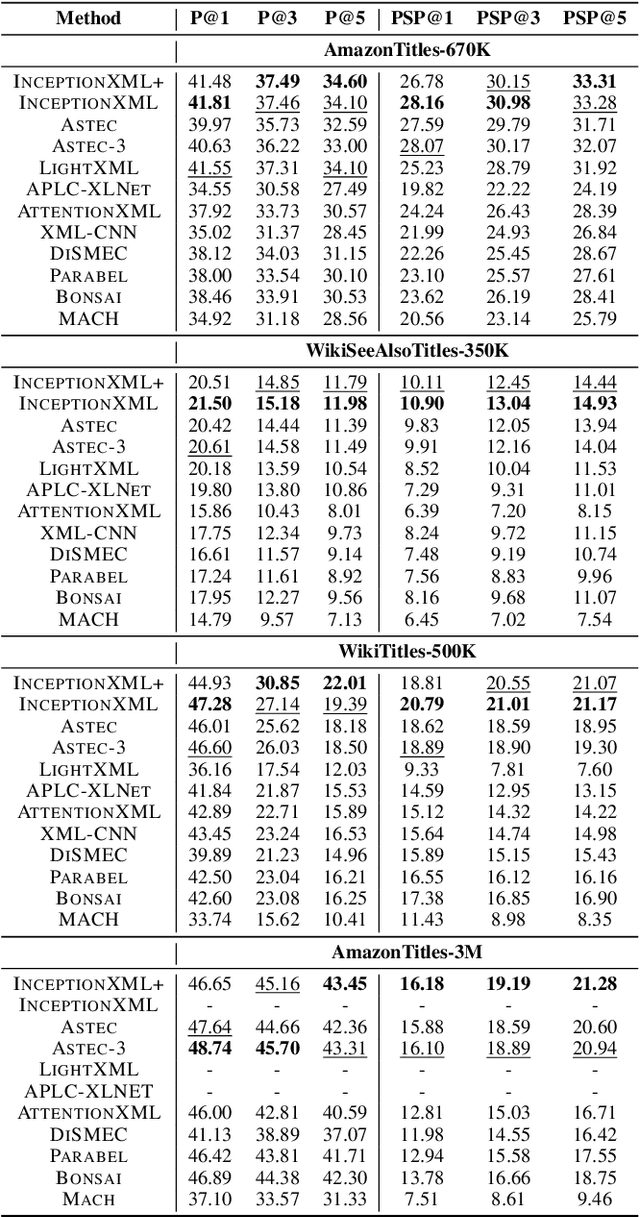
Automatic annotation of short-text data to a large number of target labels, referred to as Short Text Extreme Classification, has recently found numerous applications in prediction of related searches and product recommendation tasks. The conventional usage of Convolutional Neural Network (CNN) to capture n-grams in text-classification relies heavily on uniformity in word-ordering and the presence of long input sequences to convolve over. However, this is missing in short and unstructured text sequences encountered in search and recommendation. In order to tackle this, we propose an orthogonal approach by recasting the convolution operation to capture coupled semantics along the embedding dimensions, and develop a word-order agnostic embedding enhancement module to deal with the lack of structure in such queries. Benefitting from the computational efficiency of the convolution operation, Embedding Convolutions, when applied on the enriched word embeddings, result in a light-weight and yet powerful encoder (InceptionXML) that is robust to the inherent lack of structure in short-text extreme classification. Towards scaling our model to problems with millions of labels, we also propose InceptionXML+, which addresses the shortcomings of the dynamic hard-negative mining framework in the recently proposed LightXML by improving the alignment between the label-shortlister and extreme classifier. On popular benchmark datasets, we empirically demonstrate that the proposed method outperforms state-of-the-art deep extreme classifiers such as Astec by an average of 5% and 8% on the P@k and propensity-scored PSP@k metrics respectively.