 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDEC : Unified Dual Encoder and Classifier Training for Extreme Multi-Label Classification
Paper and Code
May 04, 2024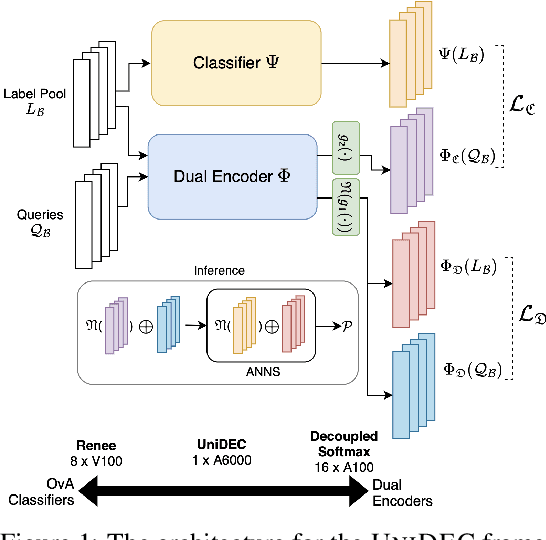
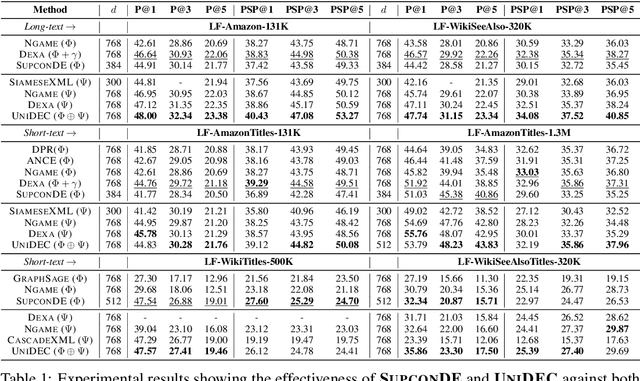
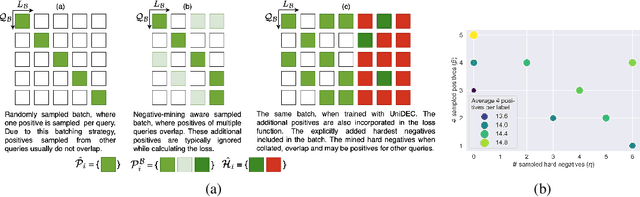
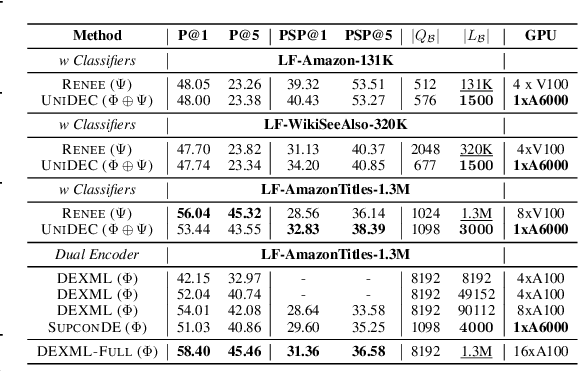
Extreme Multi-label Classification (XMC) involves predicting a subset of relevant labels from an extremely large label space, given an input query and labels with textual features. Models developed for this problem have conventionally used modular approach with (i) a Dual Encoder (DE) to embed the queries and label texts, (ii) a One-vs-All classifier to rerank the shortlisted labels mined through meta-classifier training. While such methods have shown empirical success, we observe two key uncharted aspects, (i) DE training typically uses only a single positive relation even for datasets which offer more, (ii) existing approaches fixate on using only OvA reduction of the multi-label problem. This work aims to explore these aspects by proposing UniDEC, a novel end-to-end trainable framework which trains the dual encoder and classifier in together in a unified fashion using a multi-class loss. For the choice of multi-class loss, the work proposes a novel pick-some-label (PSL) reduction of the multi-label problem with leverages multiple (in come cases, all) positives. The proposed framework achieves state-of-the-art results on a single GPU, while achieving on par results with respect to multi-GPU SOTA methods on various XML benchmark datasets, all while using 4-16x lesser compute and being practically scalable even beyond million label scale datasets.