 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Convolutions for Short Text Extreme Classification with Millions of Labels
Sep 13, 2021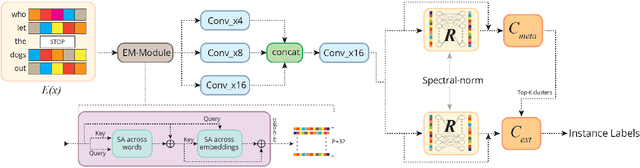

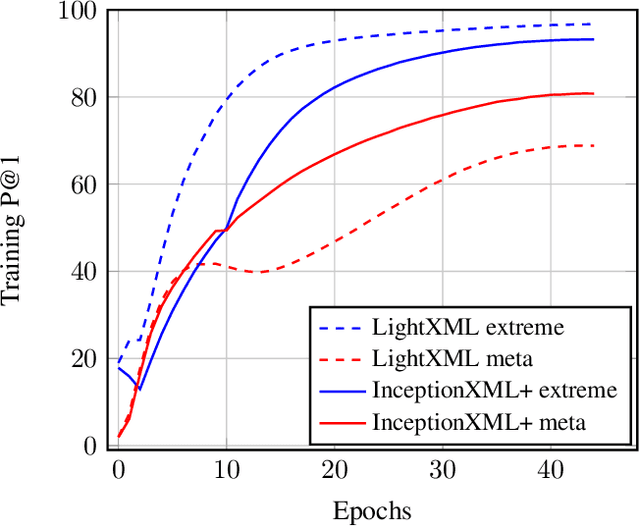
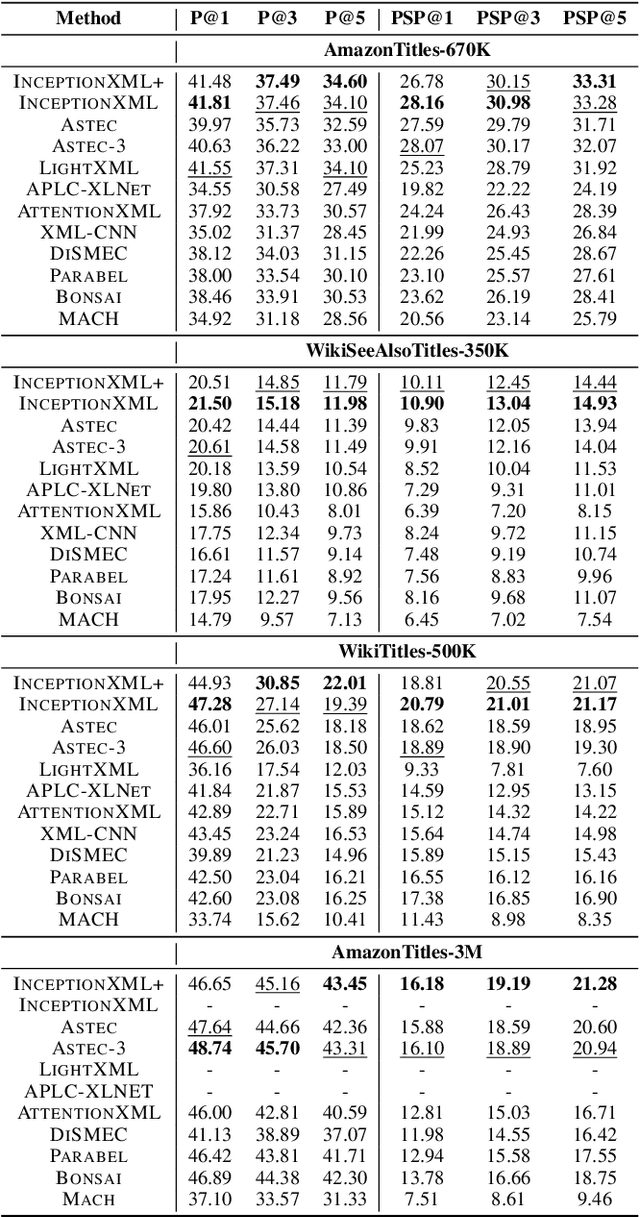
Automatic annotation of short-text data to a large number of target labels, referred to as Short Text Extreme Classification, has recently found numerous applications in prediction of related searches and product recommendation tasks. The conventional usage of Convolutional Neural Network (CNN) to capture n-grams in text-classification relies heavily on uniformity in word-ordering and the presence of long input sequences to convolve over. However, this is missing in short and unstructured text sequences encountered in search and recommendation. In order to tackle this, we propose an orthogonal approach by recasting the convolution operation to capture coupled semantics along the embedding dimensions, and develop a word-order agnostic embedding enhancement module to deal with the lack of structure in such queries. Benefitting from the computational efficiency of the convolution operation, Embedding Convolutions, when applied on the enriched word embeddings, result in a light-weight and yet powerful encoder (InceptionXML) that is robust to the inherent lack of structure in short-text extreme classification. Towards scaling our model to problems with millions of labels, we also propose InceptionXML+, which addresses the shortcomings of the dynamic hard-negative mining framework in the recently proposed LightXML by improving the alignment between the label-shortlister and extreme classifier. On popular benchmark datasets, we empirically demonstrate that the proposed method outperforms state-of-the-art deep extreme classifiers such as Astec by an average of 5% and 8% on the P@k and propensity-scored PSP@k metrics respectively.
MXR-U-Nets for Real Time Hyperspectral Reconstruction
Apr 15, 2020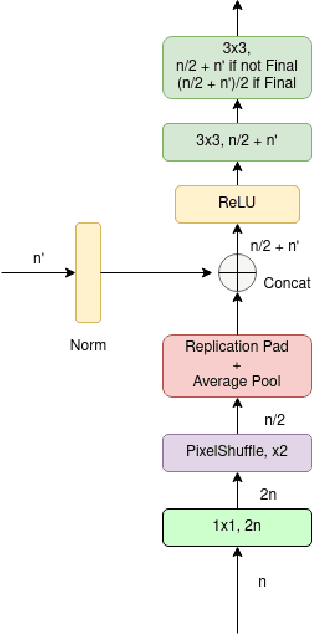
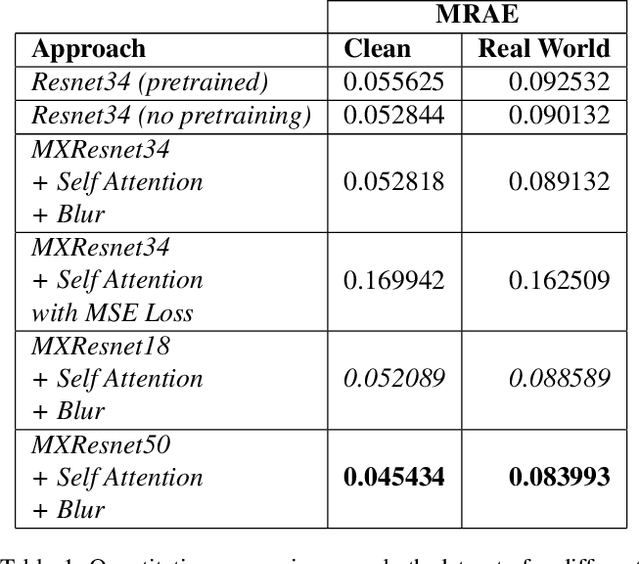
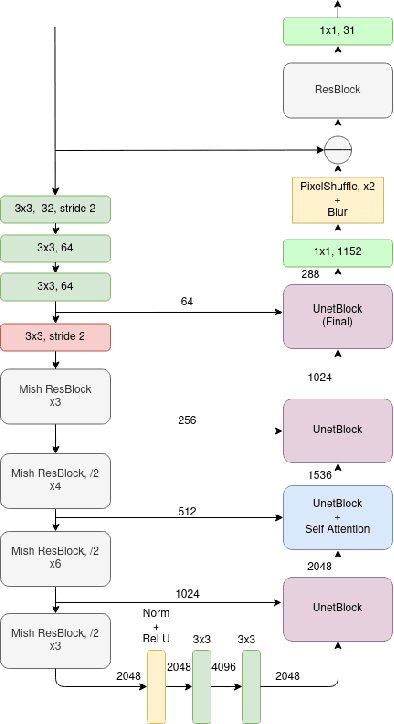

In recent times, CNNs have made significant contributions to applications in image generation, super-resolution and style transfer. In this paper, we build upon the work of Howard and Gugger, He et al. and Misra, D. and propose a CNN architecture that accurately reconstructs hyperspectral images from their RGB counterparts. We also propose a much shallower version of our best model with a 10% relative memory footprint and 3x faster inference, thus enabling real-time video applications while still experiencing only about a 0.5% decrease in performance.