 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Benchmarks for Scientific Research in Explainable Machine Learning
Paper and Code
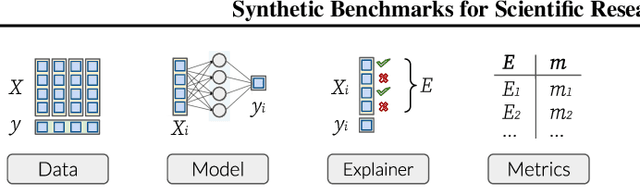
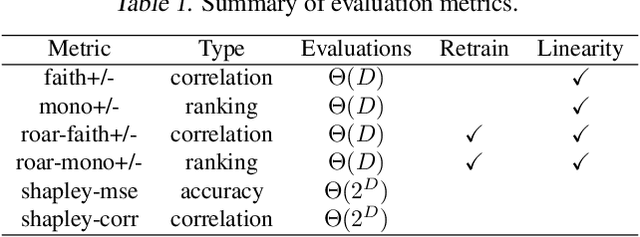
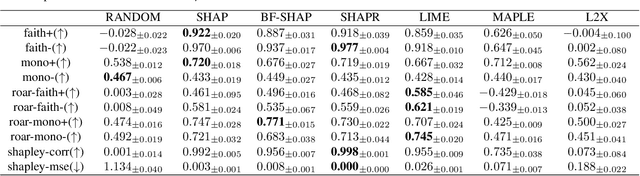
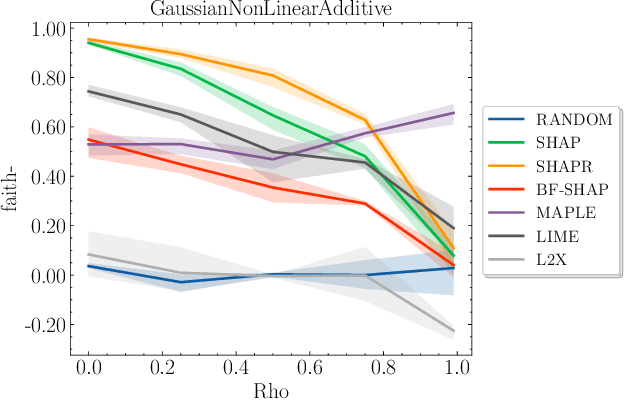
As machine learning models grow more complex and their applications become more high-stakes, tools for explaining model predictions have become increasingly important. Despite the widespread use of explainability techniques, evaluating and comparing different feature attribution methods remains challenging: evaluations ideally require human studies, and empirical evaluation metrics are often computationally prohibitive on real-world datasets. In this work, we address this issue by releasing XAI-Bench: a suite of synthetic datasets along with a library for benchmarking feature attribution algorithms. Unlike real-world datasets, synthetic datasets allow the efficient computation of conditional expected values that are needed to evaluate ground-truth Shapley values and other metrics. The synthetic datasets we release offer a wide variety of parameters that can be configured to simulate real-world data. We demonstrate the power of our library by benchmarking popular explainability techniques across several evaluation metrics and identifying failure modes for popular explainers. The efficiency of our library will help bring new explainability methods from development to deployment.