 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Engine Optimization: A VLM and Agent Framework for Pinterest Acquisition Growth
Feb 03, 2026Large Language Models are fundamentally reshaping content discovery through AI-native search systems such as ChatGPT, Gemini, and Claude. Unlike traditional search engines that match keywords to documents, these systems infer user intent, synthesize multimodal evidence, and generate contextual answers directly on the search page, introducing a paradigm shift from Search Engine Optimization (SEO) to Generative Engine Optimization (GEO). For visual content platforms hosting billions of assets, this poses an acute challenge: individual images lack the semantic depth and authority signals that generative search prioritizes, risking disintermediation as user needs are satisfied in-place without site visits. We present Pinterest GEO, a production-scale framework that pioneers reverse search design: rather than generating generic image captions describing what content is, we fine-tune Vision-Language Models (VLMs) to predict what users would actually search for, augmented this with AI agents that mine real-time internet trends to capture emerging search demand. These VLM-generated queries then drive construction of semantically coherent Collection Pages via multimodal embeddings, creating indexable aggregations optimized for generative retrieval. Finally, we employ hybrid VLM and two-tower ANN architectures to build authority-aware interlinking structures that propagate signals across billions of visual assets. Deployed at scale across billions of images and tens of millions of collections, GEO delivers 20\% organic traffic growth contributing to multi-million monthly active user (MAU) growth, demonstrating a principled pathway for visual platforms to thrive in the generative search era.
RecoMind: A Reinforcement Learning Framework for Optimizing In-Session User Satisfaction in Recommendation Systems
Jul 31, 2025Existing web-scale recommendation systems commonly use supervised learning methods that prioritize immediate user feedback. Although reinforcement learning (RL) offers a solution to optimize longer-term goals, such as in-session engagement, applying it at web scale is challenging due to the extremely large action space and engineering complexity. In this paper, we introduce RecoMind, a simulator-based RL framework designed for the effective optimization of session-based goals at web-scale. RecoMind leverages existing recommendation models to establish a simulation environment and to bootstrap the RL policy to optimize immediate user interactions from the outset. This method integrates well with existing industry pipelines, simplifying the training and deployment of RL policies. Additionally, RecoMind introduces a custom exploration strategy to efficiently explore web-scale action spaces with hundreds of millions of items. We evaluated RecoMind through extensive offline simulations and online A/B testing on a video streaming platform. Both methods showed that the RL policy trained using RecoMind significantly outperforms traditional supervised learning recommendation approaches in in-session user satisfaction. In online A/B tests, the RL policy increased videos watched for more than 10 seconds by 15.81\% and improved session depth by 4.71\% for sessions with at least 10 interactions. As a result, RecoMind presents a systematic and scalable approach for embedding RL into web-scale recommendation systems, showing great promise for optimizing session-based user satisfaction.
Modeling User Behavior With Interaction Networks for Spam Detection
Jul 21, 2022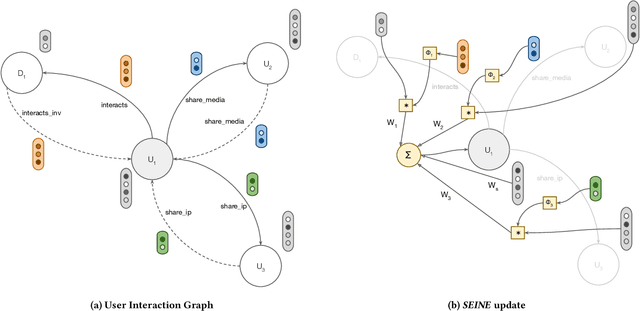
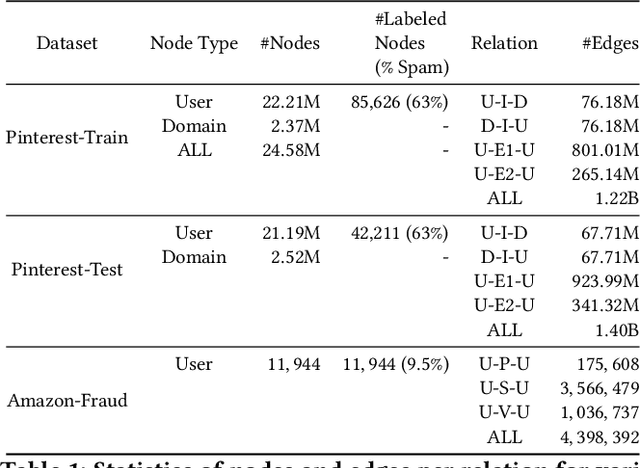
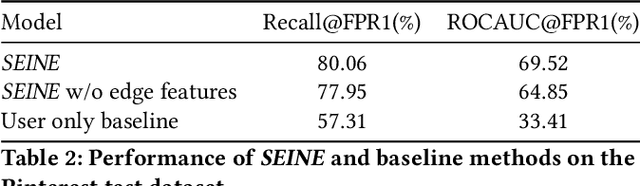
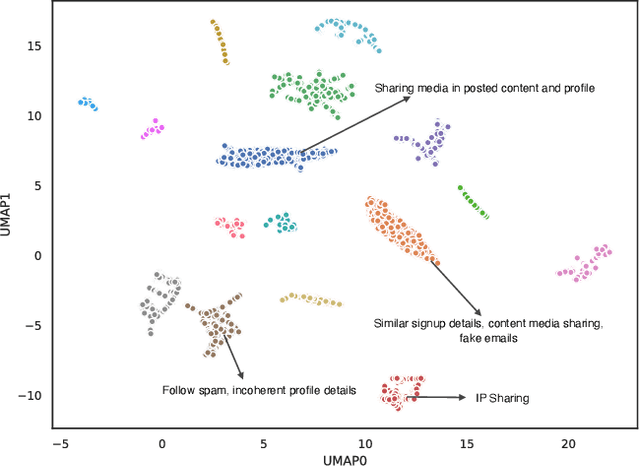
Spam is a serious problem plaguing web-scale digital platforms which facilitate user content creation and distribution. It compromises platform's integrity, performance of services like recommendation and search, and overall business. Spammers engage in a variety of abusive and evasive behavior which are distinct from non-spammers. Users' complex behavior can be well represented by a heterogeneous graph rich with node and edge attributes. Learning to identify spammers in such a graph for a web-scale platform is challenging because of its structural complexity and size. In this paper, we propose SEINE (Spam DEtection using Interaction NEtworks), a spam detection model over a novel graph framework. Our graph simultaneously captures rich users' details and behavior and enables learning on a billion-scale graph. Our model considers neighborhood along with edge types and attributes, allowing it to capture a wide range of spammers. SEINE, trained on a real dataset of tens of millions of nodes and billions of edges, achieves a high performance of 80% recall with 1% false positive rate. SEINE achieves comparable performance to the state-of-the-art techniques on a public dataset while being pragmatic to be used in a large-scale production system.
* 6 pages, 2 figures, accepted to SIGIR 2022
Profile Based Sub-Image Search in Image Databases
Oct 07, 2010
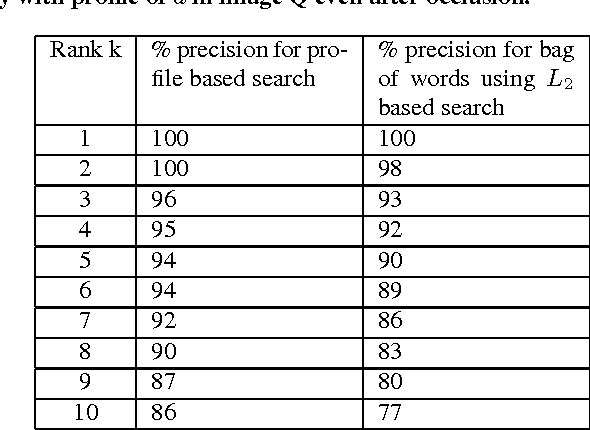

Sub-image search with high accuracy in natural images still remains a challenging problem. This paper proposes a new feature vector called profile for a keypoint in a bag of visual words model of an image. The profile of a keypoint captures the spatial geometry of all the other keypoints in an image with respect to itself, and is very effective in discriminating true matches from false matches. Sub-image search using profiles is a single-phase process requiring no geometric validation, yields high precision on natural images, and works well on small visual codebook. The proposed search technique differs from traditional methods that first generate a set of candidates disregarding spatial information and then verify them geometrically. Conventional methods also use large codebooks. We achieve a precision of 81% on a combined data set of synthetic and real natural images using a codebook size of 500 for top-10 queries; that is 31% higher than the conventional candidate generation approach.
Finding Significant Subregions in Large Image Databases
Jun 19, 2009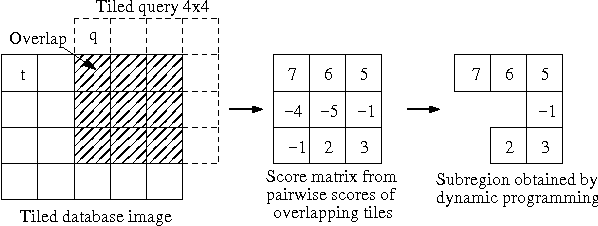

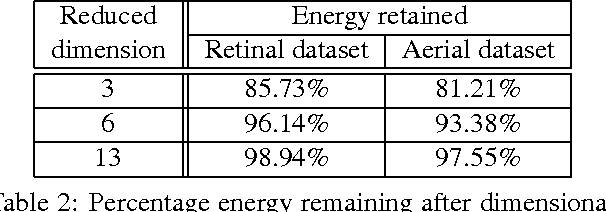
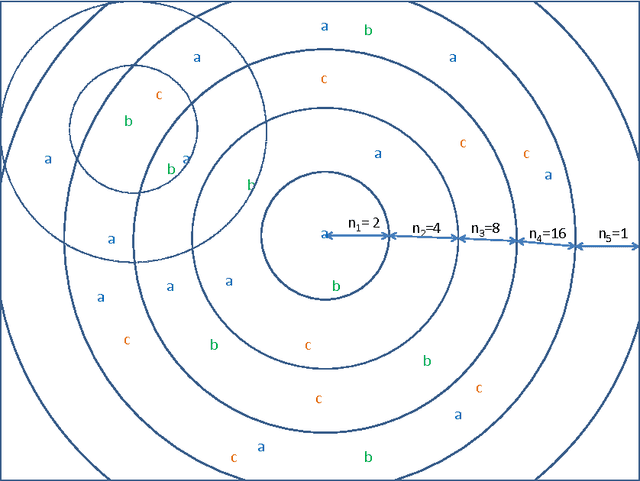
Images have become an important data source in many scientific and commercial domains. Analysis and exploration of image collections often requires the retrieval of the best subregions matching a given query. The support of such content-based retrieval requires not only the formulation of an appropriate scoring function for defining relevant subregions but also the design of new access methods that can scale to large databases. In this paper, we propose a solution to this problem of querying significant image subregions. We design a scoring scheme to measure the similarity of subregions. Our similarity measure extends to any image descriptor. All the images are tiled and each alignment of the query and a database image produces a tile score matrix. We show that the problem of finding the best connected subregion from this matrix is NP-hard and develop a dynamic programming heuristic. With this heuristic, we develop two index based scalable search strategies, TARS and SPARS, to query patterns in a large image repository. These strategies are general enough to work with other scoring schemes and heuristics. Experimental results on real image datasets show that TARS saves more than 87% query time on small queries, and SPARS saves up to 52% query time on large queries as compared to linear search. Qualitative tests on synthetic and real datasets achieve precision of more than 80%.
* 16 pages, 48 figures