 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVartani Spellcheck -- Automatic Context-Sensitive Spelling Correction of OCR-generated Hindi Text Using BERT and Levenshtein Distance
Paper and Code
Dec 14, 2020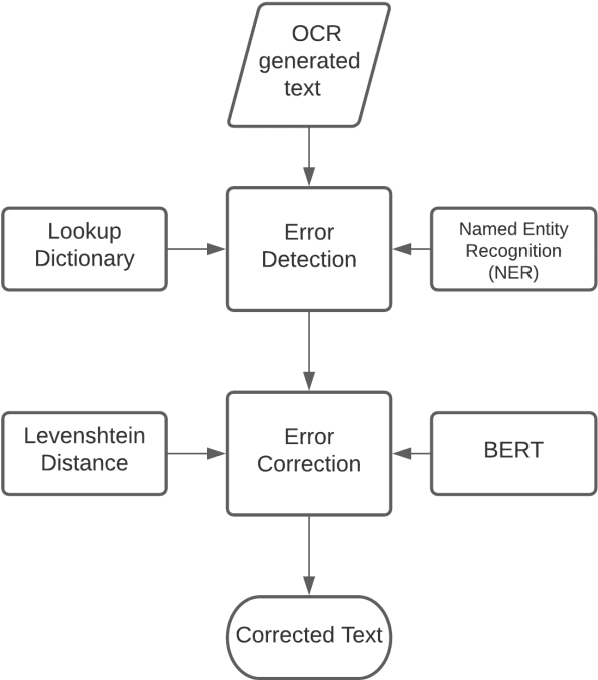
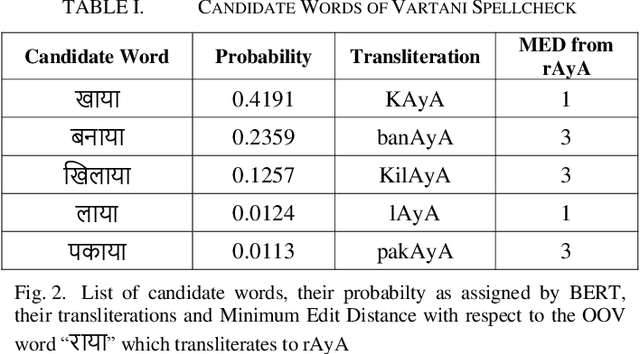
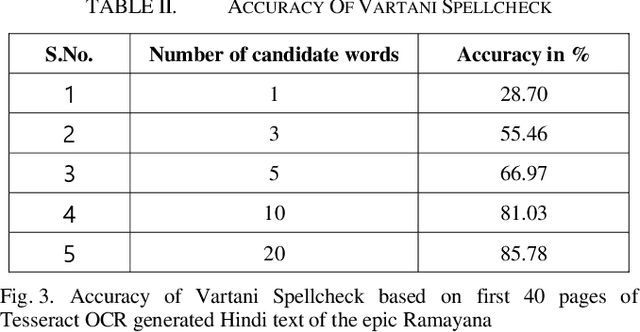
Traditional Optical Character Recognition (OCR) systems that generate text of highly inflectional Indic languages like Hindi tend to suffer from poor accuracy due to a wide alphabet set, compound characters and difficulty in segmenting characters in a word. Automatic spelling error detection and context-sensitive error correction can be used to improve accuracy by post-processing the text generated by these OCR systems. A majority of previously developed language models for error correction of Hindi spelling have been context-free. In this paper, we present Vartani Spellcheck - a context-sensitive approach for spelling correction of Hindi text using a state-of-the-art transformer - BERT in conjunction with the Levenshtein distance algorithm, popularly known as Edit Distance. We use a lookup dictionary and context-based named entity recognition (NER) for detection of possible spelling errors in the text. Our proposed technique has been tested on a large corpus of text generated by the widely used Tesseract OCR on the Hindi epic Ramayana. With an accuracy of 81%, the results show a significant improvement over some of the previously established context-sensitive error correction mechanisms for Hindi. We also explain how Vartani Spellcheck may be used for on-the-fly autocorrect suggestion during continuous typing in a text editor environment.