 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentInstruct: Toward Generative Teaching with Agentic Flows
Jul 03, 2024



Synthetic data is becoming increasingly important for accelerating the development of language models, both large and small. Despite several successful use cases, researchers also raised concerns around model collapse and drawbacks of imitating other models. This discrepancy can be attributed to the fact that synthetic data varies in quality and diversity. Effective use of synthetic data usually requires significant human effort in curating the data. We focus on using synthetic data for post-training, specifically creating data by powerful models to teach a new skill or behavior to another model, we refer to this setting as Generative Teaching. We introduce AgentInstruct, an extensible agentic framework for automatically creating large amounts of diverse and high-quality synthetic data. AgentInstruct can create both the prompts and responses, using only raw data sources like text documents and code files as seeds. We demonstrate the utility of AgentInstruct by creating a post training dataset of 25M pairs to teach language models different skills, such as text editing, creative writing, tool usage, coding, reading comprehension, etc. The dataset can be used for instruction tuning of any base model. We post-train Mistral-7b with the data. When comparing the resulting model Orca-3 to Mistral-7b-Instruct (which uses the same base model), we observe significant improvements across many benchmarks. For example, 40% improvement on AGIEval, 19% improvement on MMLU, 54% improvement on GSM8K, 38% improvement on BBH and 45% improvement on AlpacaEval. Additionally, it consistently outperforms other models such as LLAMA-8B-instruct and GPT-3.5-turbo.
Orca-Math: Unlocking the potential of SLMs in Grade School Math
Feb 16, 2024Mathematical word problem-solving has long been recognized as a complex task for small language models (SLMs). A recent study hypothesized that the smallest model size, needed to achieve over 80% accuracy on the GSM8K benchmark, is 34 billion parameters. To reach this level of performance with smaller models, researcher often train SLMs to generate Python code or use tools to help avoid calculation errors. Additionally, they employ ensembling, where outputs of up to 100 model runs are combined to arrive at a more accurate result. Result selection is done using consensus, majority vote or a separate a verifier model used in conjunction with the SLM. Ensembling provides a substantial boost in accuracy but at a significant cost increase with multiple calls to the model (e.g., Phi-GSM uses top-48 to boost the performance from 68.2 to 81.5). In this work, we present Orca-Math, a 7-billion-parameter SLM based on the Mistral-7B, which achieves 86.81% on GSM8k without the need for multiple model calls or the use of verifiers, code execution or any other external tools. Our approach has the following key elements: (1) A high quality synthetic dataset of 200K math problems created using a multi-agent setup where agents collaborate to create the data, (2) An iterative learning techniques that enables the SLM to practice solving problems, receive feedback on its solutions and learn from preference pairs incorporating the SLM solutions and the feedback. When trained with Supervised Fine-Tuning alone, Orca-Math achieves 81.50% on GSM8k pass@1 metric. With iterative preference learning, Orca-Math achieves 86.81% pass@1. Orca-Math surpasses the performance of significantly larger models such as LLAMA-2-70B, WizardMath-70B, Gemini-Pro, ChatGPT-3.5. It also significantly outperforms other smaller models while using much smaller data (hundreds of thousands vs. millions of problems).
Orca 2: Teaching Small Language Models How to Reason
Nov 21, 2023



Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs' reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at aka.ms/orca-lm to support research on the development, evaluation, and alignment of smaller LMs
Improving the Reusability of Pre-trained Language Models in Real-world Applications
Aug 08, 2023The reusability of state-of-the-art Pre-trained Language Models (PLMs) is often limited by their generalization problem, where their performance drastically decreases when evaluated on examples that differ from the training dataset, known as Out-of-Distribution (OOD)/unseen examples. This limitation arises from PLMs' reliance on spurious correlations, which work well for frequent example types but not for general examples. To address this issue, we propose a training approach called Mask-tuning, which integrates Masked Language Modeling (MLM) training objectives into the fine-tuning process to enhance PLMs' generalization. Comprehensive experiments demonstrate that Mask-tuning surpasses current state-of-the-art techniques and enhances PLMs' generalization on OOD datasets while improving their performance on in-distribution datasets. The findings suggest that Mask-tuning improves the reusability of PLMs on unseen data, making them more practical and effective for real-world applications.
Gender-tuning: Empowering Fine-tuning for Debiasing Pre-trained Language Models
Jul 20, 2023

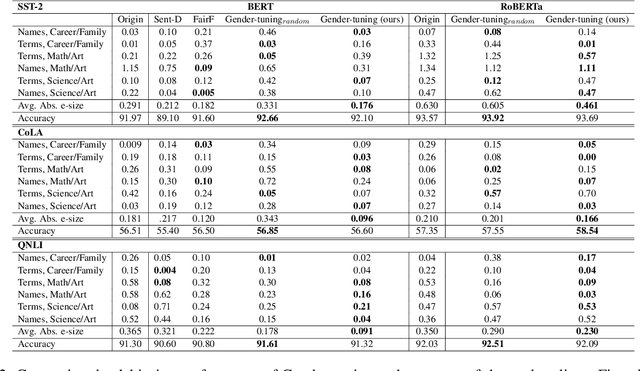

Recent studies have revealed that the widely-used Pre-trained Language Models (PLMs) propagate societal biases from the large unmoderated pre-training corpora. Existing solutions require debiasing training processes and datasets for debiasing, which are resource-intensive and costly. Furthermore, these methods hurt the PLMs' performance on downstream tasks. In this study, we propose Gender-tuning, which debiases the PLMs through fine-tuning on downstream tasks' datasets. For this aim, Gender-tuning integrates Masked Language Modeling (MLM) training objectives into fine-tuning's training process. Comprehensive experiments show that Gender-tuning outperforms the state-of-the-art baselines in terms of average gender bias scores in PLMs while improving PLMs' performance on downstream tasks solely using the downstream tasks' dataset. Also, Gender-tuning is a deployable debiasing tool for any PLM that works with original fine-tuning.
Learning to Reverse DNNs from AI Programs Automatically
May 20, 2022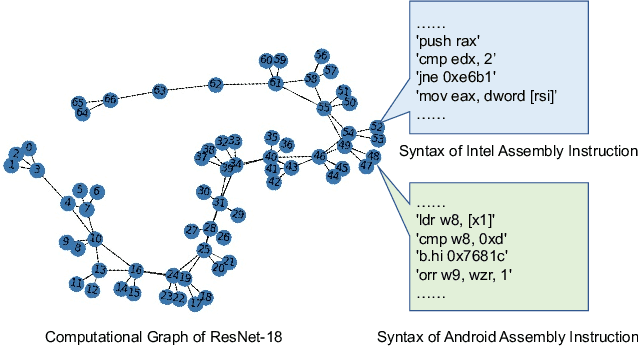
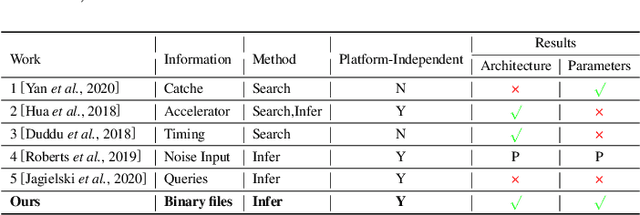
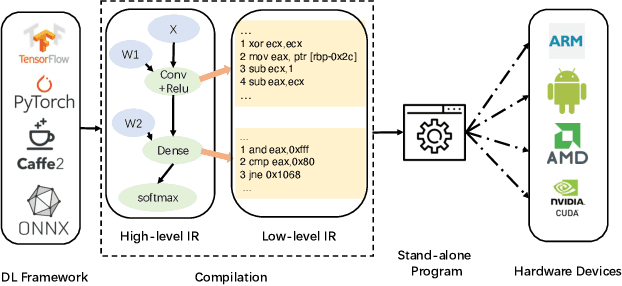
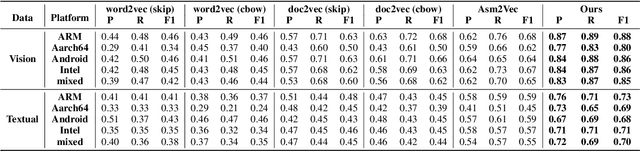
With the privatization deployment of DNNs on edge devices, the security of on-device DNNs has raised significant concern. To quantify the model leakage risk of on-device DNNs automatically, we propose NNReverse, the first learning-based method which can reverse DNNs from AI programs without domain knowledge. NNReverse trains a representation model to represent the semantics of binary code for DNN layers. By searching the most similar function in our database, NNReverse infers the layer type of a given function's binary code. To represent assembly instructions semantics precisely, NNReverse proposes a more fine-grained embedding model to represent the textual and structural-semantic of assembly functions.