 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Reusability of Pre-trained Language Models in Real-world Applications
Aug 08, 2023The reusability of state-of-the-art Pre-trained Language Models (PLMs) is often limited by their generalization problem, where their performance drastically decreases when evaluated on examples that differ from the training dataset, known as Out-of-Distribution (OOD)/unseen examples. This limitation arises from PLMs' reliance on spurious correlations, which work well for frequent example types but not for general examples. To address this issue, we propose a training approach called Mask-tuning, which integrates Masked Language Modeling (MLM) training objectives into the fine-tuning process to enhance PLMs' generalization. Comprehensive experiments demonstrate that Mask-tuning surpasses current state-of-the-art techniques and enhances PLMs' generalization on OOD datasets while improving their performance on in-distribution datasets. The findings suggest that Mask-tuning improves the reusability of PLMs on unseen data, making them more practical and effective for real-world applications.
Gender-tuning: Empowering Fine-tuning for Debiasing Pre-trained Language Models
Jul 20, 2023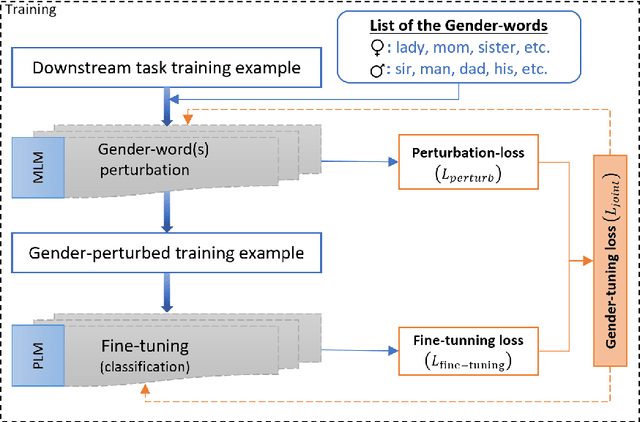

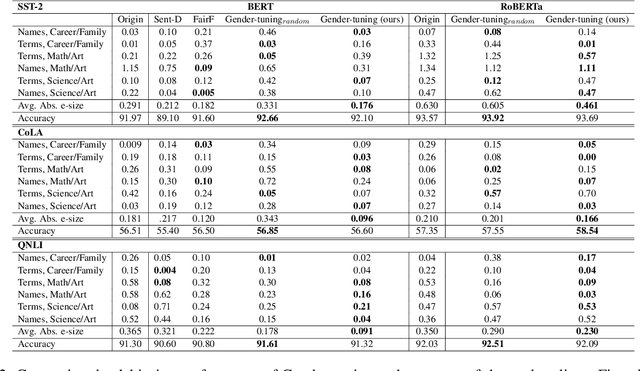

Recent studies have revealed that the widely-used Pre-trained Language Models (PLMs) propagate societal biases from the large unmoderated pre-training corpora. Existing solutions require debiasing training processes and datasets for debiasing, which are resource-intensive and costly. Furthermore, these methods hurt the PLMs' performance on downstream tasks. In this study, we propose Gender-tuning, which debiases the PLMs through fine-tuning on downstream tasks' datasets. For this aim, Gender-tuning integrates Masked Language Modeling (MLM) training objectives into fine-tuning's training process. Comprehensive experiments show that Gender-tuning outperforms the state-of-the-art baselines in terms of average gender bias scores in PLMs while improving PLMs' performance on downstream tasks solely using the downstream tasks' dataset. Also, Gender-tuning is a deployable debiasing tool for any PLM that works with original fine-tuning.