 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCautious Weight Decay
Oct 14, 2025We introduce Cautious Weight Decay (CWD), a one-line, optimizer-agnostic modification that applies weight decay only to parameter coordinates whose signs align with the optimizer update. Unlike standard decoupled decay, which implicitly optimizes a regularized or constrained objective, CWD preserves the original loss and admits a bilevel interpretation: it induces sliding-mode behavior upon reaching the stationary manifold, allowing it to search for locally Pareto-optimal stationary points of the unmodified objective. In practice, CWD is a drop-in change for optimizers such as AdamW, Lion, and Muon, requiring no new hyperparameters or additional tuning. For language model pre-training and ImageNet classification, CWD consistently improves final loss and accuracy at million- to billion-parameter scales.
Aligning the Pretraining and Finetuning Objectives of Language Models
Feb 05, 2020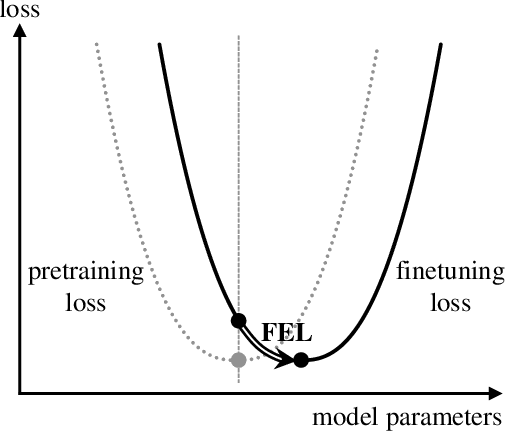
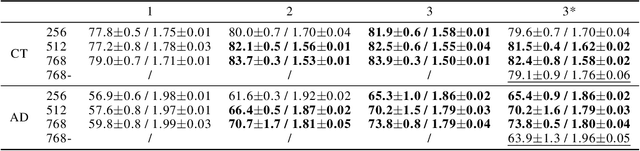
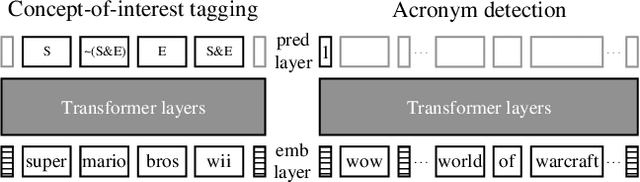
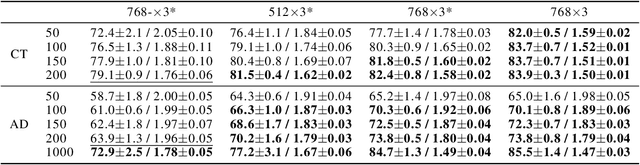
We demonstrate that explicitly aligning the pretraining objectives to the finetuning objectives in language model training significantly improves the finetuning task performance and reduces the minimum amount of finetuning examples required. The performance margin gained from objective alignment allows us to build language models with smaller sizes for tasks with less available training data. We provide empirical evidence of these claims by applying objective alignment to concept-of-interest tagging and acronym detection tasks. We found that, with objective alignment, our 768 by 3 and 512 by 3 transformer language models can reach accuracy of 83.9%/82.5% for concept-of-interest tagging and 73.8%/70.2% for acronym detection using only 200 finetuning examples per task, outperforming the 768 by 3 model pretrained without objective alignment by +4.8%/+3.4% and +9.9%/+6.3%. We name finetuning small language models in the presence of hundreds of training examples or less "Few Example learning". In practice, Few Example Learning enabled by objective alignment not only saves human labeling costs, but also makes it possible to leverage language models in more real-time applications.