 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuTa-VC: A Duration-aware Typical-to-atypical Voice Conversion Approach with Diffusion Probabilistic Model
Paper and Code
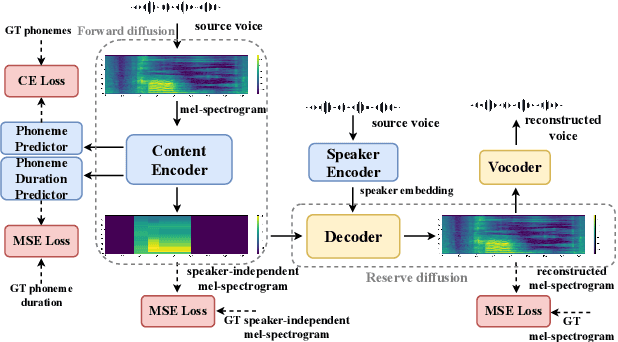
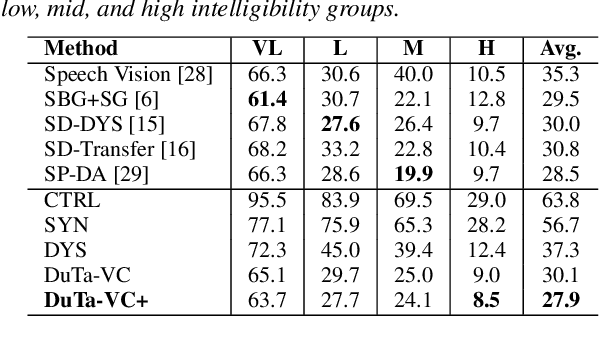
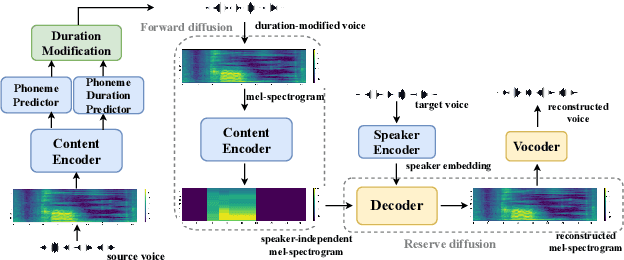
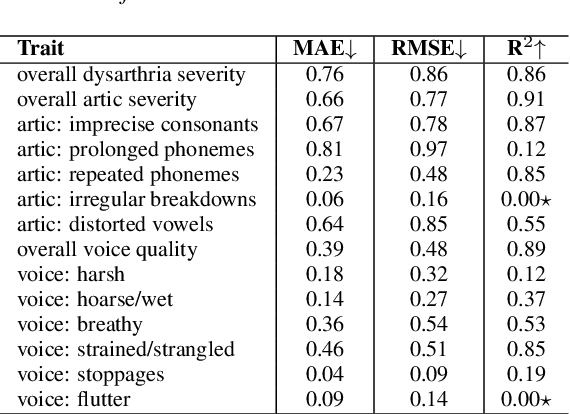
We present a novel typical-to-atypical voice conversion approach (DuTa-VC), which (i) can be trained with nonparallel data (ii) first introduces diffusion probabilistic model (iii) preserves the target speaker identity (iv) is aware of the phoneme duration of the target speaker. DuTa-VC consists of three parts: an encoder transforms the source mel-spectrogram into a duration-modified speaker-independent mel-spectrogram, a decoder performs the reverse diffusion to generate the target mel-spectrogram, and a vocoder is applied to reconstruct the waveform. Objective evaluations conducted on the UASpeech show that DuTa-VC is able to capture severity characteristics of dysarthric speech, reserves speaker identity, and significantly improves dysarthric speech recognition as a data augmentation. Subjective evaluations by two expert speech pathologists validate that DuTa-VC can preserve the severity and type of dysarthria of the target speakers in the synthesized speech.