 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CAT SET on the MAT: Cross Attention for Set Matching in Bipartite Hypergraphs
Oct 30, 2021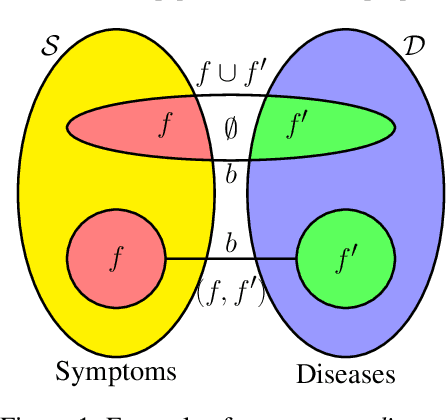

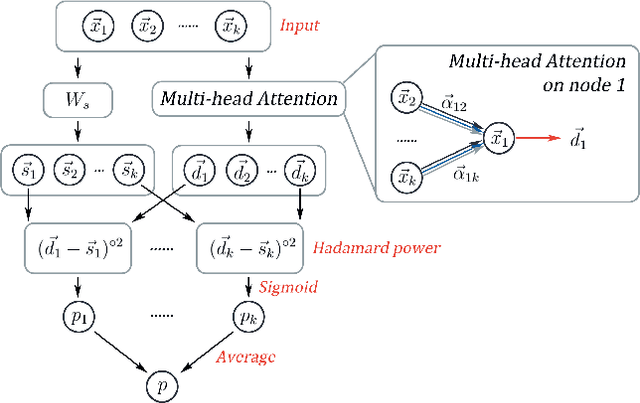
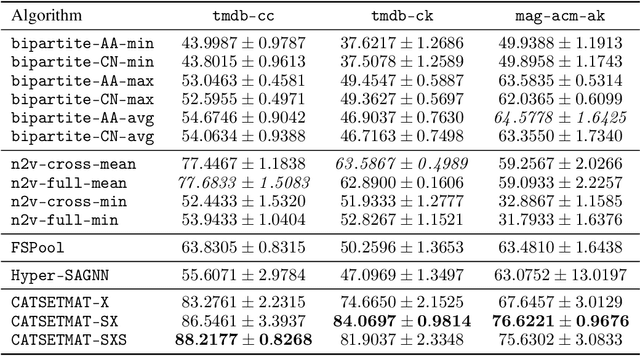
Usual relations between entities could be captured using graphs; but those of a higher-order -- more so between two different types of entities (which we term "left" and "right") -- calls for a "bipartite hypergraph". For example, given a left set of symptoms and right set of diseases, the relation between a set subset of symptoms (that a patient experiences at a given point of time) and a subset of diseases (that he/she might be diagnosed with) could be well-represented using a bipartite hyperedge. The state-of-the-art in embedding nodes of a hypergraph is based on learning the self-attention structure between node-pairs from a hyperedge. In the present work, given a bipartite hypergraph, we aim at capturing relations between node pairs from the cross-product between the left and right hyperedges, and term it a "cross-attention" (CAT) based model. More precisely, we pose "bipartite hyperedge link prediction" as a set-matching (SETMAT) problem and propose a novel neural network architecture called CATSETMAT for the same. We perform extensive experiments on multiple bipartite hypergraph datasets to show the superior performance of CATSETMAT, which we compare with multiple techniques from the state-of-the-art. Our results also elucidate information flow in self- and cross-attention scenarios.
Neural Machine Translation with Recurrent Highway Networks
Apr 28, 2019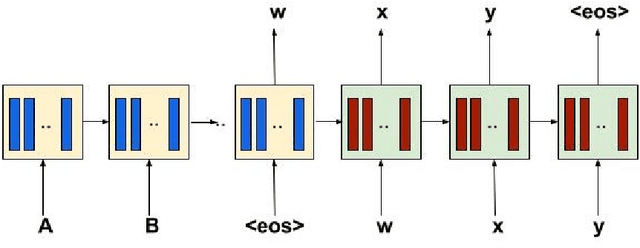
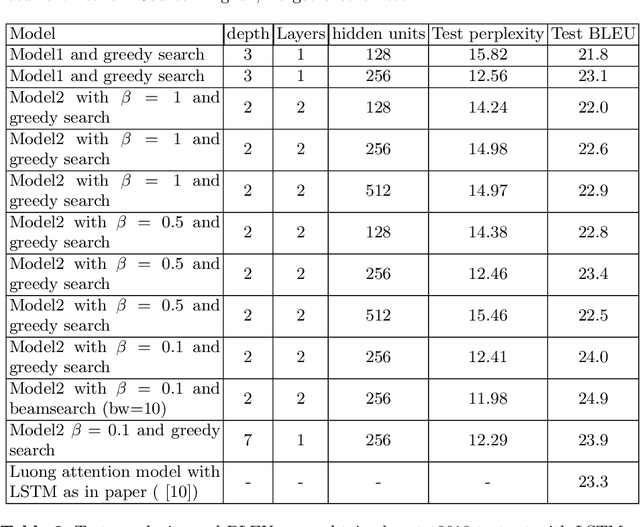
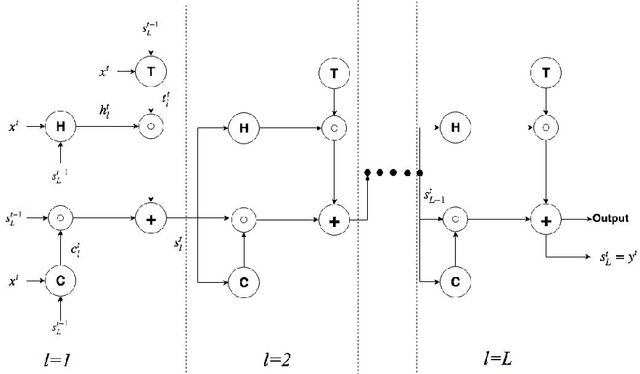
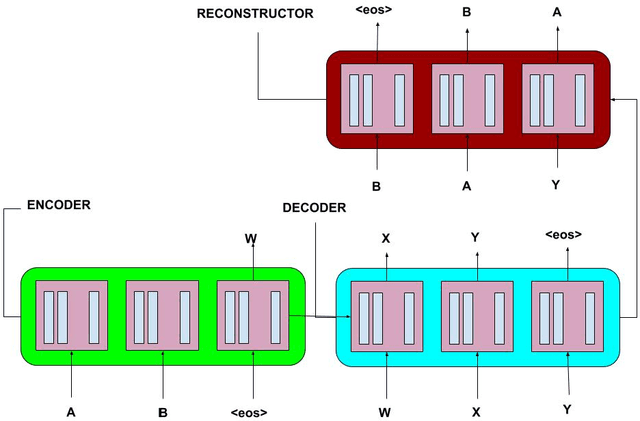
Recurrent Neural Networks have lately gained a lot of popularity in language modelling tasks, especially in neural machine translation(NMT). Very recent NMT models are based on Encoder-Decoder, where a deep LSTM based encoder is used to project the source sentence to a fixed dimensional vector and then another deep LSTM decodes the target sentence from the vector. However there has been very little work on exploring architectures that have more than one layer in space(i.e. in each time step). This paper examines the effectiveness of the simple Recurrent Highway Networks(RHN) in NMT tasks. The model uses Recurrent Highway Neural Network in encoder and decoder, with attention .We also explore the reconstructor model to improve adequacy. We demonstrate the effectiveness of all three approaches on the IWSLT English-Vietnamese dataset. We see that RHN performs on par with LSTM based models and even better in some cases.We see that deep RHN models are easy to train compared to deep LSTM based models because of highway connections. The paper also investigates the effects of increasing recurrent depth in each time step.
* International Conference on Mining Intelligence and Knowledge Exploration