 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeqAttCNN - Self Attention Mechanism for Video QoE Prediction in Encrypted Traffic
Jan 11, 2026The rapid growth of multimedia consumption, driven by major advances in mobile devices since the mid-2000s, has led to widespread use of video conferencing applications (VCAs) such as Zoom and Google Meet, as well as instant messaging applications (IMAs) like WhatsApp and Telegram, which increasingly support video conferencing as a core feature. Many of these systems rely on the Web Real-Time Communication (WebRTC) protocol, enabling direct peer-to-peer media streaming without requiring a third-party server to relay data, reducing the latency and facilitating a real-time communication. Despite WebRTC's potential, adverse network conditions can degrade streaming quality and consequently reduce users' Quality of Experience (QoE). Maintaining high QoE therefore requires continuous monitoring and timely intervention when QoE begins to deteriorate. While content providers can often estimate QoE by directly comparing transmitted and received media, this task is significantly more challenging for internet service providers (ISPs). End-to-end encryption, commonly used by modern VCAs and IMAs, prevent ISPs from accessing the original media stream, leaving only Quality of Service (QoS) and routing information available. To address this limitation, we propose the QoE Attention Convolutional Neural Network (qAttCNN), a model that leverages packet size parameter of the traffic to infer two no-reference QoE metrics viz. BRISQUE and frames per second (FPS). We evaluate qAttCNN on a custom dataset collected from WhatsApp video calls and compare it against existing QoE models. Using mean absolute error percentage (MAEP), our approach achieves 2.14% error for BRISQUE and 7.39% for FPS prediction.
Video QoE Metrics from Encrypted Traffic: Application-agnostic Methodology
Apr 20, 2025



Instant Messaging-Based Video Call Applications (IMVCAs) and Video Conferencing Applications (VCAs) have become integral to modern communication. Ensuring a high Quality of Experience (QoE) for users in this context is critical for network operators, as network conditions significantly impact user QoE. However, network operators lack access to end-device QoE metrics due to encrypted traffic. Existing solutions estimate QoE metrics from encrypted traffic traversing the network, with the most advanced approaches leveraging machine learning models. Subsequently, the need for ground truth QoE metrics for training and validation poses a challenge, as not all video applications provide these metrics. To address this challenge, we propose an application-agnostic approach for objective QoE estimation from encrypted traffic. Independent of the video application, we obtained key video QoE metrics, enabling broad applicability to various proprietary IMVCAs and VCAs. To validate our solution, we created a diverse dataset from WhatsApp video sessions under various network conditions, comprising 25,680 seconds of traffic data and QoE metrics. Our evaluation shows high performance across the entire dataset, with 85.2% accuracy for FPS predictions within an error margin of two FPS, and 90.2% accuracy for PIQE-based quality rating classification.
Don't Lag, RAG: Training-Free Adversarial Detection Using RAG
Apr 07, 2025Adversarial patch attacks pose a major threat to vision systems by embedding localized perturbations that mislead deep models. Traditional defense methods often require retraining or fine-tuning, making them impractical for real-world deployment. We propose a training-free Visual Retrieval-Augmented Generation (VRAG) framework that integrates Vision-Language Models (VLMs) for adversarial patch detection. By retrieving visually similar patches and images that resemble stored attacks in a continuously expanding database, VRAG performs generative reasoning to identify diverse attack types, all without additional training or fine-tuning. We extensively evaluate open-source large-scale VLMs, including Qwen-VL-Plus, Qwen2.5-VL-72B, and UI-TARS-72B-DPO, alongside Gemini-2.0, a closed-source model. Notably, the open-source UI-TARS-72B-DPO model achieves up to 95 percent classification accuracy, setting a new state-of-the-art for open-source adversarial patch detection. Gemini-2.0 attains the highest overall accuracy, 98 percent, but remains closed-source. Experimental results demonstrate VRAG's effectiveness in identifying a variety of adversarial patches with minimal human annotation, paving the way for robust, practical defenses against evolving adversarial patch attacks.
WARLearn: Weather-Adaptive Representation Learning
Nov 21, 2024



This paper introduces WARLearn, a novel framework designed for adaptive representation learning in challenging and adversarial weather conditions. Leveraging the in-variance principal used in Barlow Twins, we demonstrate the capability to port the existing models initially trained on clear weather data to effectively handle adverse weather conditions. With minimal additional training, our method exhibits remarkable performance gains in scenarios characterized by fog and low-light conditions. This adaptive framework extends its applicability beyond adverse weather settings, offering a versatile solution for domains exhibiting variations in data distributions. Furthermore, WARLearn is invaluable in scenarios where data distributions undergo significant shifts over time, enabling models to remain updated and accurate. Our experimental findings reveal a remarkable performance, with a mean average precision (mAP) of 52.6% on unseen real-world foggy dataset (RTTS). Similarly, in low light conditions, our framework achieves a mAP of 55.7% on unseen real-world low light dataset (ExDark). Notably, WARLearn surpasses the performance of state-of-the-art frameworks including FeatEnHancer, Image Adaptive YOLO, DENet, C2PNet, PairLIE and ZeroDCE, by a substantial margin in adverse weather, improving the baseline performance in both foggy and low light conditions. The WARLearn code is available at https://github.com/ShubhamAgarwal12/WARLearn
Real-Time Weather Image Classification with SVM
Sep 01, 2024
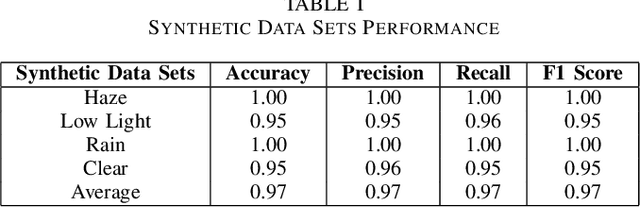
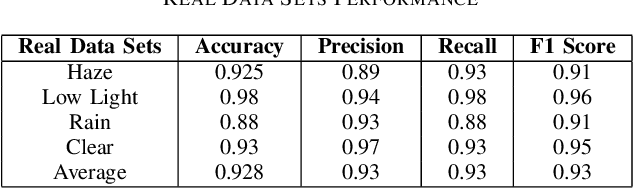
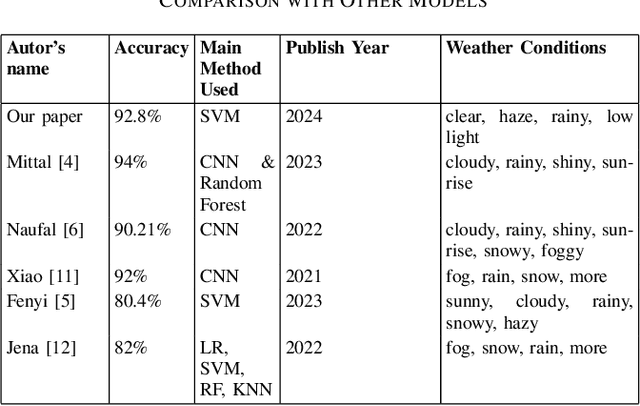
Accurate classification of weather conditions in images is essential for enhancing the performance of object detection and classification models under varying weather conditions. This paper presents a comprehensive study on classifying weather conditions in images into four categories: rainy, low light, haze, and clear. The motivation for this work stems from the need to improve the reliability and efficiency of automated systems, such as autonomous vehicles and surveillance, which must operate under diverse weather conditions. Misclassification of weather conditions can lead to significant performance degradation in these systems, making robust weather classification crucial. Utilizing the Support Vector Machine (SVM) algorithm, our approach leverages a robust set of features, including brightness, saturation, noise level, blur metric, edge strength, motion blur, Local Binary Patterns (LBP) mean and variance for radii 1, 2, and 3, edges mean and variance, and color histogram mean and variance for blue, green, and red channels. Our SVM-based method achieved a notable accuracy of 92.8%, surpassing typical benchmarks in the literature, which range from 80% to 90% for classical machine learning methods. While deep learning methods can achieve up to 94% accuracy, our approach offers a competitive advantage in terms of computational efficiency and real-time classification capabilities. Detailed analysis of each feature's contribution highlights the effectiveness of texture, color, and edge-related features in capturing the unique characteristics of different weather conditions. This research advances the state-of-the-art in weather image classification and provides insights into the critical features necessary for accurate weather condition differentiation, underscoring the potential of SVMs in practical applications where accuracy is paramount.
I Know What You Saw Last Minute - Encrypted HTTP Adaptive Video Streaming Title Classification
Jul 21, 2016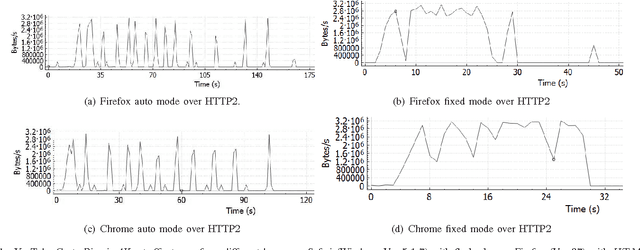

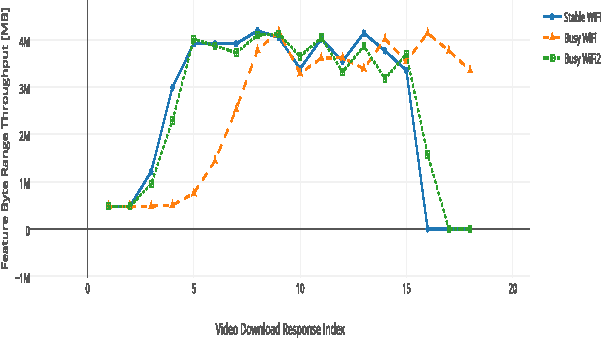
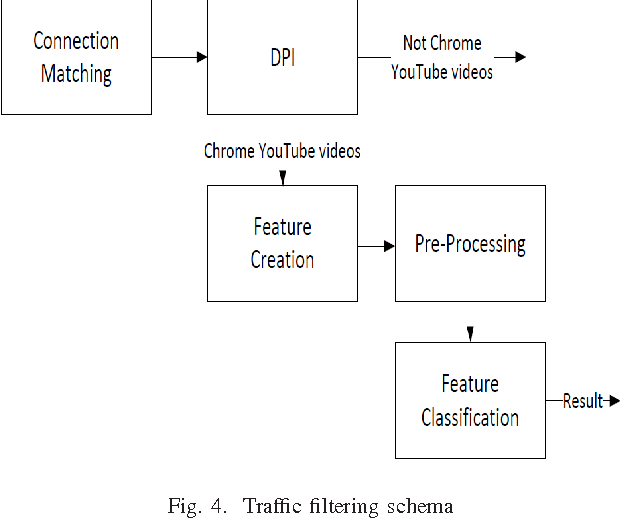
Desktops and laptops can be maliciously exploited to violate privacy. There are two main types of attack scenarios: active and passive. In this paper, we consider the passive scenario where the adversary does not interact actively with the device, but he is able to eavesdrop on the network traffic of the device from the network side. Most of the Internet traffic is encrypted and thus passive attacks are challenging. Previous research has shown that information can be extracted from encrypted multimedia streams. This includes video title classification of non HTTP adaptive streams (non-HAS). This paper presents an algorithm for encrypted HTTP adaptive video streaming title classification. We show that an external attacker can identify the video title from video HTTP adaptive streams (HAS) sites such as YouTube. To the best of our knowledge, this is the first work that shows this. We provide a large data set of 10000 YouTube video streams of 100 popular video titles (each title downloaded 100 times) as examples for this task. The dataset was collected under real-world network conditions. We present several machine algorithms for the task and run a through set of experiments, which shows that our classification accuracy is more than 95%. We also show that our algorithms are able to classify video titles that are not in the training set as unknown and some of the algorithms are also able to eliminate false prediction of video titles and instead report unknown. Finally, we evaluate our algorithms robustness to delays and packet losses at test time and show that a solution that uses SVM is the most robust against these changes given enough training data. We provide the dataset and the crawler for future research.
* 9 pages. arXiv admin note: text overlap with arXiv:1602.00489
Deep Learning for Saliency Prediction in Natural Video
Apr 27, 2016


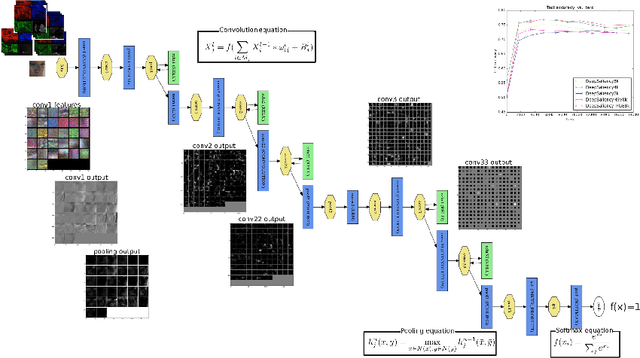
The purpose of this paper is the detection of salient areas in natural video by using the new deep learning techniques. Salient patches in video frames are predicted first. Then the predicted visual fixation maps are built upon them. We design the deep architecture on the basis of CaffeNet implemented with Caffe toolkit. We show that changing the way of data selection for optimisation of network parameters, we can save computation cost up to 12 times. We extend deep learning approaches for saliency prediction in still images with RGB values to specificity of video using the sensitivity of the human visual system to residual motion. Furthermore, we complete primary colour pixel values by contrast features proposed in classical visual attention prediction models. The experiments are conducted on two publicly available datasets. The first is IRCCYN video database containing 31 videos with an overall amount of 7300 frames and eye fixations of 37 subjects. The second one is HOLLYWOOD2 provided 2517 movie clips with the eye fixations of 19 subjects. On IRCYYN dataset, the accuracy obtained is of 89.51%. On HOLLYWOOD2 dataset, results in prediction of saliency of patches show the improvement up to 2% with regard to RGB use only. The resulting accuracy of 76, 6% is obtained. The AUC metric in comparison of predicted saliency maps with visual fixation maps shows the increase up to 16% on a sample of video clips from this dataset.
Real Time Video Quality Representation Classification of Encrypted HTTP Adaptive Video Streaming - the Case of Safari
Feb 19, 2016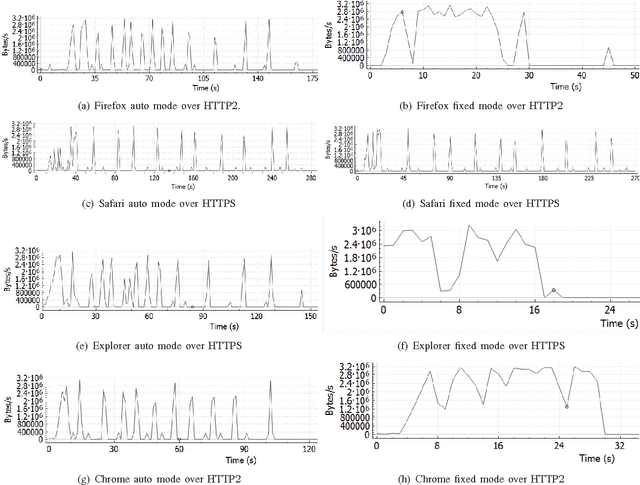
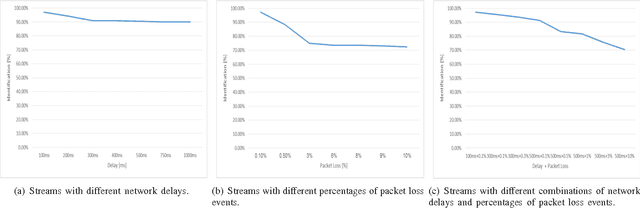
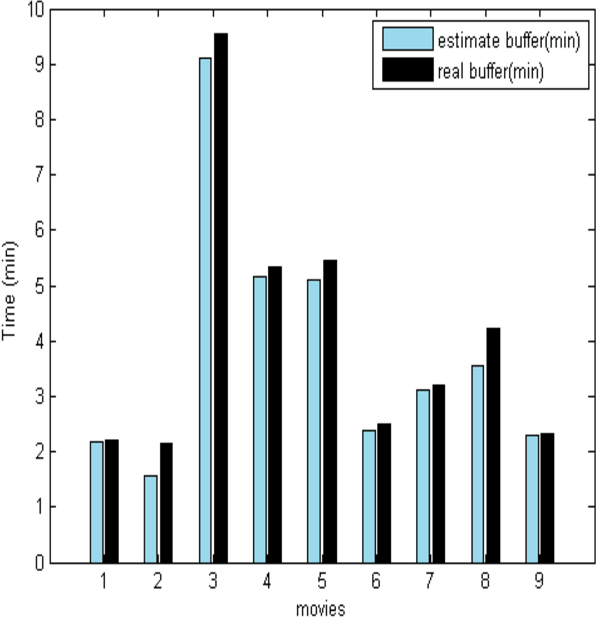

The increasing popularity of HTTP adaptive video streaming services has dramatically increased bandwidth requirements on operator networks, which attempt to shape their traffic through Deep Packet Inspection (DPI). However, Google and certain content providers have started to encrypt their video services. As a result, operators often encounter difficulties in shaping their encrypted video traffic via DPI. This highlights the need for new traffic classification methods for encrypted HTTP adaptive video streaming to enable smart traffic shaping. These new methods will have to effectively estimate the quality representation layer and playout buffer. We present a new method and show for the first time that video quality representation classification for (YouTube) encrypted HTTP adaptive streaming is possible. We analyze the performance of this classification method with Safari over HTTPS. Based on a large number of offline and online traffic classification experiments, we demonstrate that it can independently classify, in real time, every video segment into one of the quality representation layers with 97.18% average accuracy.