 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirage Probes: How Vision Models Fake Visual Understanding
Jun 11, 2026Vision-language models (VLMs) can answer image-based questions confidently, and often correctly, even when no image is provided. This mirage behavior inflates benchmark scores without reflecting visual grounding. Prior work treats this as a single failure mode. We argue it is two. Using Mirage Probes, a contrastive probing framework that pairs paraphrased question variants with matched mirage and non-mirage labels on the same image, we show that mirage behavior is linearly decodable from internal activations across residual stream, MLP, post-attention, and attention-head sites in two open-source VLMs. We demonstrate that a Naive Bayes text baseline cannot recover this signal, ruling out surface lexical confounds. Cross-benchmark separability patterns, together with a novel Prior Harnessing Index (PHI) measuring how much a model can answer from text alone, expose two distinct regimes: textual biases, where the model answers from language priors without engaging visual representations, and spurious images, where it constructs false visual content in latent space and answers as if grounded. The distinction has direct mitigation consequences: text-distribution cleaning can address the first regime but cannot reach the second, since spurious-image mirages live in the model's visual representations rather than its text. Faithful visual grounding will require interventions at the representational level.
On the Robustness of Diffusion-Based Image Compression to Bit-Flip Errors
Apr 07, 2026Modern image compression methods are typically optimized for the rate--distortion--perception trade-off, whereas their robustness to bit-level corruption is rarely examined. We show that diffusion-based compressors built on the Reverse Channel Coding (RCC) paradigm are substantially more robust to bit flips than classical and learned codecs. We further introduce a more robust variant of Turbo-DDCM that significantly improves robustness while only minimally affecting the rate--distortion--perception trade-off. Our findings suggest that RCC-based compression can yield more resilient compressed representations, potentially reducing reliance on error-correcting codes in highly noisy environments.
BenchOverflow: Measuring Overflow in Large Language Models via Plain-Text Prompts
Jan 13, 2026We investigate a failure mode of large language models (LLMs) in which plain-text prompts elicit excessive outputs, a phenomenon we term Overflow. Unlike jailbreaks or prompt injection, Overflow arises under ordinary interaction settings and can lead to elevated serving cost, latency, and cross-user performance degradation, particularly when scaled across many requests. Beyond usability, the stakes are economic and environmental: unnecessary tokens increase per-request cost and energy consumption, compounding into substantial operational spend and carbon footprint at scale. Moreover, Overflow represents a practical vector for compute amplification and service degradation in shared environments. We introduce BenchOverflow, a model-agnostic benchmark of nine plain-text prompting strategies that amplify output volume without adversarial suffixes or policy circumvention. Using a standardized protocol with a fixed budget of 5000 new tokens, we evaluate nine open- and closed-source models and observe pronounced rightward shifts and heavy tails in length distributions. Cap-saturation rates (CSR@1k/3k/5k) and empirical cumulative distribution functions (ECDFs) quantify tail risk; within-prompt variance and cross-model correlations show that Overflow is broadly reproducible yet heterogeneous across families and attack vectors. A lightweight mitigation-a fixed conciseness reminder-attenuates right tails and lowers CSR for all strategies across the majority of models. Our findings position length control as a measurable reliability, cost, and sustainability concern rather than a stylistic quirk. By enabling standardized comparison of length-control robustness across models, BenchOverflow provides a practical basis for selecting deployments that minimize resource waste and operating expense, and for evaluating defenses that curb compute amplification without eroding task performance.
Activation Steering for Masked Diffusion Language Models
Dec 30, 2025Masked diffusion language models (MDLMs) generate text through an iterative denoising process. They have recently gained attention due to mask-parallel decoding and competitive performance with autoregressive large language models. However, effective mechanisms for inference-time control and steering in MDLMs remain largely unexplored. We present an activation-steering framework for MDLMs that computes layer-wise steering vectors from a single forward pass using contrastive examples, without simulating the denoising trajectory. These directions are applied at every reverse-diffusion step, yielding an efficient inference-time control mechanism. Experiments on LLaDA-8B-Instruct demonstrate reliable modulation of high-level attributes, with ablations examining the effects of steering across transformer sub-modules and token scope (prompt vs.\ response).
Breaking Audio Large Language Models by Attacking Only the Encoder: A Universal Targeted Latent-Space Audio Attack
Dec 29, 2025Audio-language models combine audio encoders with large language models to enable multimodal reasoning, but they also introduce new security vulnerabilities. We propose a universal targeted latent space attack, an encoder-level adversarial attack that manipulates audio latent representations to induce attacker-specified outputs in downstream language generation. Unlike prior waveform-level or input-specific attacks, our approach learns a universal perturbation that generalizes across inputs and speakers and does not require access to the language model. Experiments on Qwen2-Audio-7B-Instruct demonstrate consistently high attack success rates with minimal perceptual distortion, revealing a critical and previously underexplored attack surface at the encoder level of multimodal systems.
You Had One Job: Per-Task Quantization Using LLMs' Hidden Representations
Nov 09, 2025
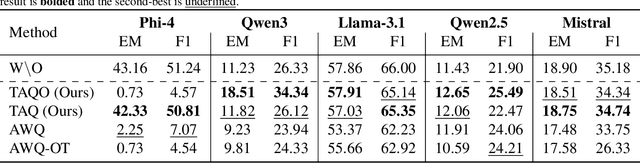
Large Language Models (LLMs) excel across diverse tasks, yet many applications require only limited capabilities, making large variants inefficient in memory and latency. Existing approaches often combine distillation and quantization, but most post-training quantization (PTQ) methods are task-agnostic, ignoring how task-specific signals are distributed across layers. In this work, we propose to use hidden representations that encode task-salient signals as a guideline for quantization. In order to fully utilize our innovative idea, this paper compares two new task-aware PTQ methods: Task-Aware Quantization (TAQ), which allocates bitwidths using task-conditioned statistics from hidden activations, and TAQO, which allocates precision based on direct layer sensitivity tests. From a small calibration set, these approaches identify task-relevant layers, preserving their precision while aggressively quantizing the rest. This yields stable task sensitivity profiles and efficient task-specialized models. Across models, TAQ and TAQO outperform the baselines; TAQ leads on Phi-4, while TAQO leads on Llama-3.1, Qwen3, and Qwen2.5. For instances, on Phi-4 it achieves 42.33 EM / 50.81 F1, far surpassing Activation-aware Weight Quantization (AWQ) (2.25 / 7.07), while remaining within < 1.0% of the original accuracy at lower average precision.
Don't Lag, RAG: Training-Free Adversarial Detection Using RAG
Apr 07, 2025Adversarial patch attacks pose a major threat to vision systems by embedding localized perturbations that mislead deep models. Traditional defense methods often require retraining or fine-tuning, making them impractical for real-world deployment. We propose a training-free Visual Retrieval-Augmented Generation (VRAG) framework that integrates Vision-Language Models (VLMs) for adversarial patch detection. By retrieving visually similar patches and images that resemble stored attacks in a continuously expanding database, VRAG performs generative reasoning to identify diverse attack types, all without additional training or fine-tuning. We extensively evaluate open-source large-scale VLMs, including Qwen-VL-Plus, Qwen2.5-VL-72B, and UI-TARS-72B-DPO, alongside Gemini-2.0, a closed-source model. Notably, the open-source UI-TARS-72B-DPO model achieves up to 95 percent classification accuracy, setting a new state-of-the-art for open-source adversarial patch detection. Gemini-2.0 attains the highest overall accuracy, 98 percent, but remains closed-source. Experimental results demonstrate VRAG's effectiveness in identifying a variety of adversarial patches with minimal human annotation, paving the way for robust, practical defenses against evolving adversarial patch attacks.
Pulling Back the Curtain: Unsupervised Adversarial Detection via Contrastive Auxiliary Networks
Feb 13, 2025



Deep learning models are widely employed in safety-critical applications yet remain susceptible to adversarial attacks -- imperceptible perturbations that can significantly degrade model performance. Conventional defense mechanisms predominantly focus on either enhancing model robustness or detecting adversarial inputs independently. In this work, we propose an Unsupervised adversarial detection via Contrastive Auxiliary Networks (U-CAN) to uncover adversarial behavior within auxiliary feature representations, without the need for adversarial examples. U-CAN is embedded within selected intermediate layers of the target model. These auxiliary networks, comprising projection layers and ArcFace-based linear layers, refine feature representations to more effectively distinguish between benign and adversarial inputs. Comprehensive experiments across multiple datasets (CIFAR-10, Mammals, and a subset of ImageNet) and architectures (ResNet-50, VGG-16, and ViT) demonstrate that our method surpasses existing unsupervised adversarial detection techniques, achieving superior F1 scores against four distinct attack methods. The proposed framework provides a scalable and effective solution for enhancing the security and reliability of deep learning systems.
On the Robustness of Kolmogorov-Arnold Networks: An Adversarial Perspective
Aug 25, 2024Kolmogorov-Arnold Networks (KANs) have recently emerged as a novel approach to function approximation, demonstrating remarkable potential in various domains. Despite their theoretical promise, the robustness of KANs under adversarial conditions has yet to be thoroughly examined. In this paper, we explore the adversarial robustness of KANs, with a particular focus on image classification tasks. We assess the performance of KANs against standard white-box adversarial attacks, comparing their resilience to that of established neural network architectures. Further, we investigate the transferability of adversarial examples between KANs and Multilayer Perceptron (MLPs), deriving critical insights into the unique vulnerabilities of KANs. Our experiments use the MNIST, FashionMNIST, and KMNIST datasets, providing a comprehensive evaluation of KANs in adversarial scenarios. This work offers the first in-depth analysis of security in KANs, laying the groundwork for future research in this emerging field.
Fortify the Guardian, Not the Treasure: Resilient Adversarial Detectors
Apr 18, 2024



This paper presents RADAR-Robust Adversarial Detection via Adversarial Retraining-an approach designed to enhance the robustness of adversarial detectors against adaptive attacks, while maintaining classifier performance. An adaptive attack is one where the attacker is aware of the defenses and adapts their strategy accordingly. Our proposed method leverages adversarial training to reinforce the ability to detect attacks, without compromising clean accuracy. During the training phase, we integrate into the dataset adversarial examples, which were optimized to fool both the classifier and the adversarial detector, enabling the adversarial detector to learn and adapt to potential attack scenarios. Experimental evaluations on the CIFAR-10 and SVHN datasets demonstrate that our proposed algorithm significantly improves a detector's ability to accurately identify adaptive adversarial attacks -- without sacrificing clean accuracy.