 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoiling Explanations in Deep Neural Networks
Paper and Code
Nov 27, 2022
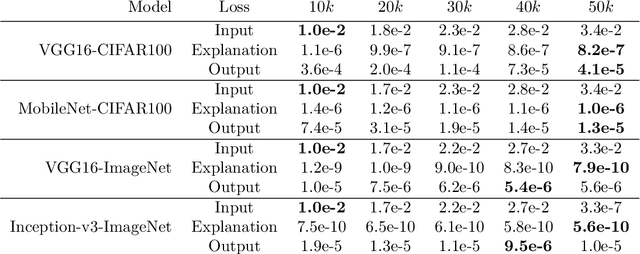

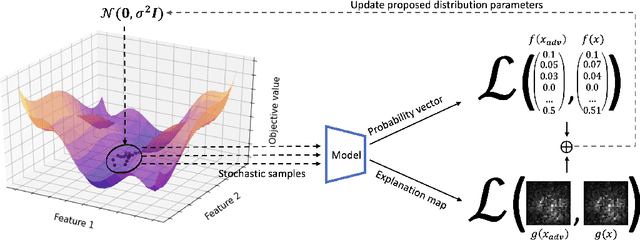
Deep neural networks (DNNs) have greatly impacted numerous fields over the past decade. Yet despite exhibiting superb performance over many problems, their black-box nature still poses a significant challenge with respect to explainability. Indeed, explainable artificial intelligence (XAI) is crucial in several fields, wherein the answer alone -- sans a reasoning of how said answer was derived -- is of little value. This paper uncovers a troubling property of explanation methods for image-based DNNs: by making small visual changes to the input image -- hardly influencing the network's output -- we demonstrate how explanations may be arbitrarily manipulated through the use of evolution strategies. Our novel algorithm, AttaXAI, a model-agnostic, adversarial attack on XAI algorithms, only requires access to the output logits of a classifier and to the explanation map; these weak assumptions render our approach highly useful where real-world models and data are concerned. We compare our method's performance on two benchmark datasets -- CIFAR100 and ImageNet -- using four different pretrained deep-learning models: VGG16-CIFAR100, VGG16-ImageNet, MobileNet-CIFAR100, and Inception-v3-ImageNet. We find that the XAI methods can be manipulated without the use of gradients or other model internals. Our novel algorithm is successfully able to manipulate an image in a manner imperceptible to the human eye, such that the XAI method outputs a specific explanation map. To our knowledge, this is the first such method in a black-box setting, and we believe it has significant value where explainability is desired, required, or legally mandatory.