 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-point quantization aware training for on-device keyword-spotting
Mar 04, 2023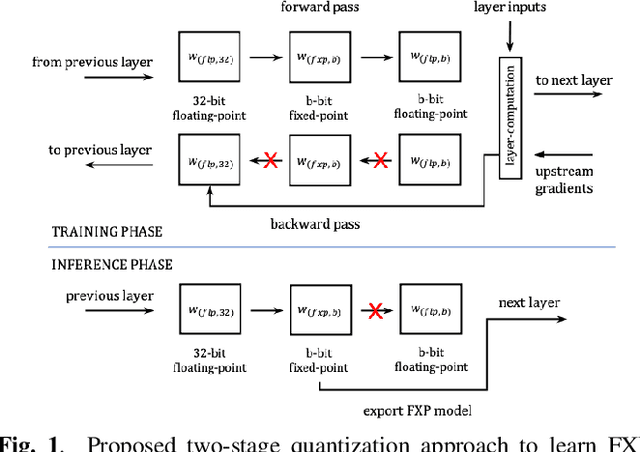

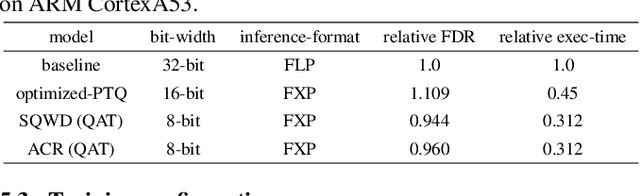
Fixed-point (FXP) inference has proven suitable for embedded devices with limited computational resources, and yet model training is continually performed in floating-point (FLP). FXP training has not been fully explored and the non-trivial conversion from FLP to FXP presents unavoidable performance drop. We propose a novel method to train and obtain FXP convolutional keyword-spotting (KWS) models. We combine our methodology with two quantization-aware-training (QAT) techniques - squashed weight distribution and absolute cosine regularization for model parameters, and propose techniques for extending QAT over transient variables, otherwise neglected by previous paradigms. Experimental results on the Google Speech Commands v2 dataset show that we can reduce model precision up to 4-bit with no loss in accuracy. Furthermore, on an in-house KWS dataset, we show that our 8-bit FXP-QAT models have a 4-6% improvement in relative false discovery rate at fixed false reject rate compared to full precision FLP models. During inference we argue that FXP-QAT eliminates q-format normalization and enables the use of low-bit accumulators while maximizing SIMD throughput to reduce user perceived latency. We demonstrate that we can reduce execution time by 68% without compromising KWS model's predictive performance or requiring model architectural changes. Our work provides novel findings that aid future research in this area and enable accurate and efficient models.
* 5 pages, 3 figures, 4 tables
Sub 8-Bit Quantization of Streaming Keyword Spotting Models for Embedded Chipsets
Jul 13, 2022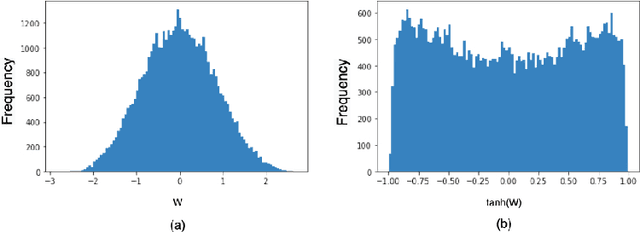
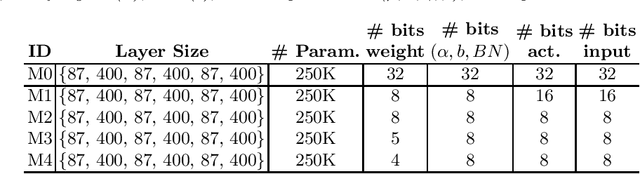
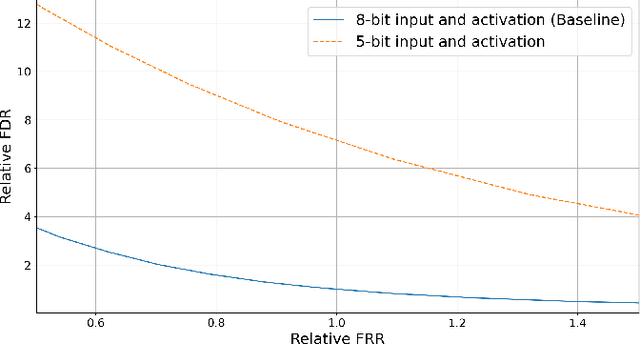
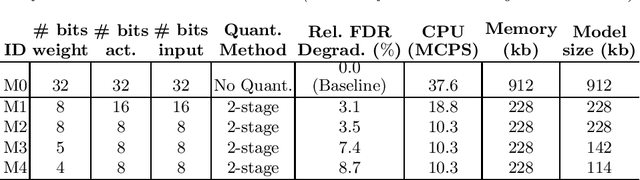
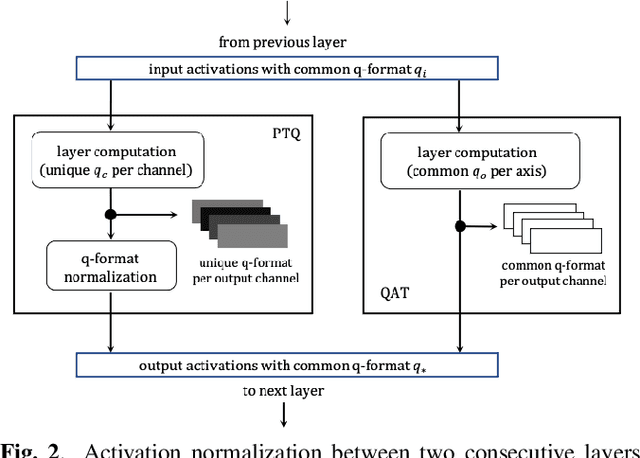
We propose a novel 2-stage sub 8-bit quantization aware training algorithm for all components of a 250K parameter feedforward, streaming, state-free keyword spotting model. For the 1st-stage, we adapt a recently proposed quantization technique using a non-linear transformation with tanh(.) on dense layer weights. In the 2nd-stage, we use linear quantization methods on the rest of the network, including other parameters (bias, gain, batchnorm), inputs, and activations. We conduct large scale experiments, training on 26,000 hours of de-identified production, far-field and near-field audio data (evaluating on 4,000 hours of data). We organize our results in two embedded chipset settings: a) with commodity ARM NEON instruction set and 8-bit containers, we present accuracy, CPU, and memory results using sub 8-bit weights (4, 5, 8-bit) and 8-bit quantization of rest of the network; b) with off-the-shelf neural network accelerators, for a range of weight bit widths (1 and 5-bit), while presenting accuracy results, we project reduction in memory utilization. In both configurations, our results show that the proposed algorithm can achieve: a) parity with a full floating point model's operating point on a detection error tradeoff (DET) curve in terms of false detection rate (FDR) at false rejection rate (FRR); b) significant reduction in compute and memory, yielding up to 3 times improvement in CPU consumption and more than 4 times improvement in memory consumption.
Accurate Detection of Wake Word Start and End Using a CNN
Aug 09, 2020

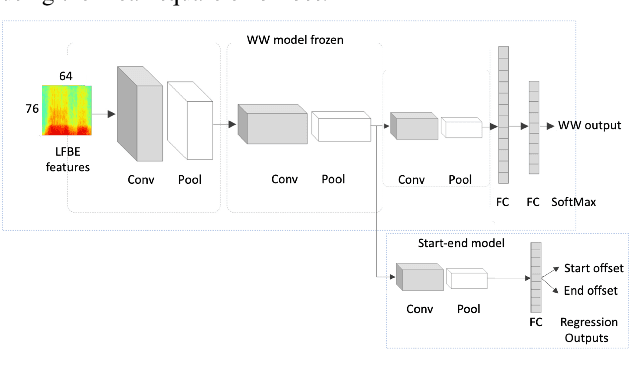

Small footprint embedded devices require keyword spotters (KWS) with small model size and detection latency for enabling voice assistants. Such a keyword is often referred to as \textit{wake word} as it is used to wake up voice assistant enabled devices. Together with wake word detection, accurate estimation of wake word endpoints (start and end) is an important task of KWS. In this paper, we propose two new methods for detecting the endpoints of wake words in neural KWS that use single-stage word-level neural networks. Our results show that the new techniques give superior accuracy for detecting wake words' endpoints of up to 50 msec standard error versus human annotations, on par with the conventional Acoustic Model plus HMM forced alignment. To our knowledge, this is the first study of wake word endpoints detection methods for single-stage neural KWS.