 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised speech representation learning for keyword-spotting with light-weight transformers
Mar 07, 2023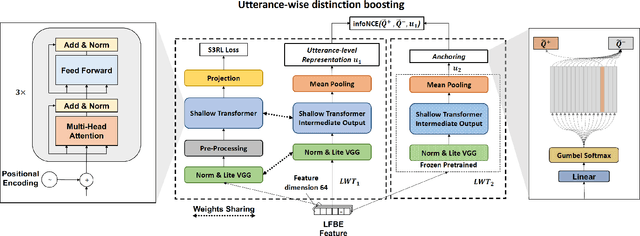
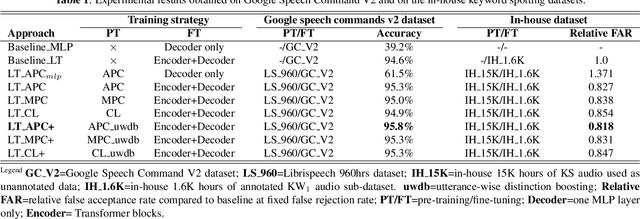
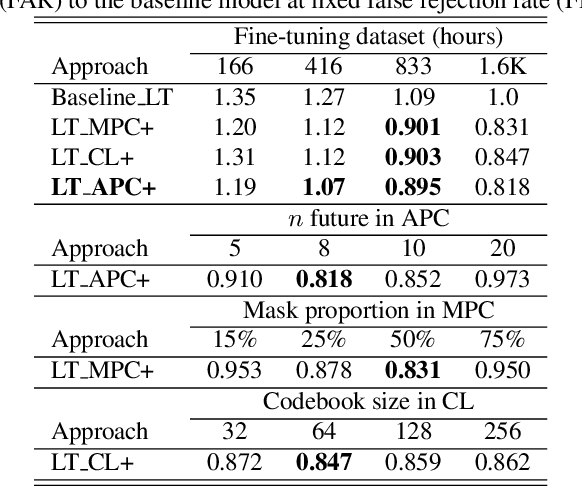
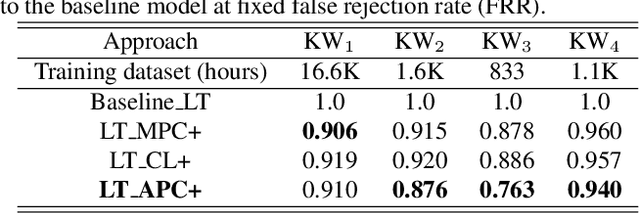
Self-supervised speech representation learning (S3RL) is revolutionizing the way we leverage the ever-growing availability of data. While S3RL related studies typically use large models, we employ light-weight networks to comply with tight memory of compute-constrained devices. We demonstrate the effectiveness of S3RL on a keyword-spotting (KS) problem by using transformers with 330k parameters and propose a mechanism to enhance utterance-wise distinction, which proves crucial for improving performance on classification tasks. On the Google speech commands v2 dataset, the proposed method applied to the Auto-Regressive Predictive Coding S3RL led to a 1.2% accuracy improvement compared to training from scratch. On an in-house KS dataset with four different keywords, it provided 6% to 23.7% relative false accept improvement at fixed false reject rate. We argue this demonstrates the applicability of S3RL approaches to light-weight models for KS and confirms S3RL is a powerful alternative to traditional supervised learning for resource-constrained applications.
Fixed-point quantization aware training for on-device keyword-spotting
Mar 04, 2023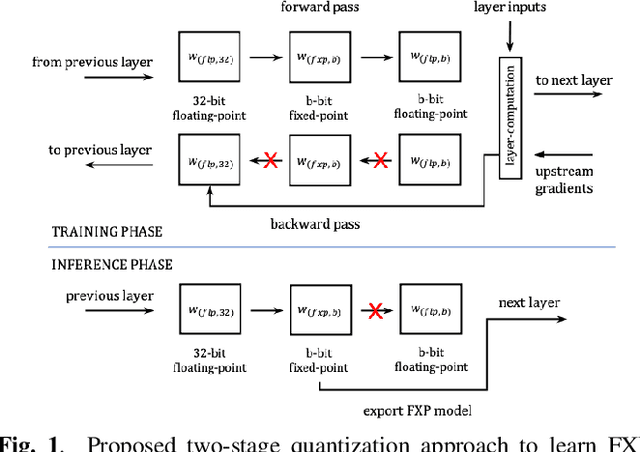

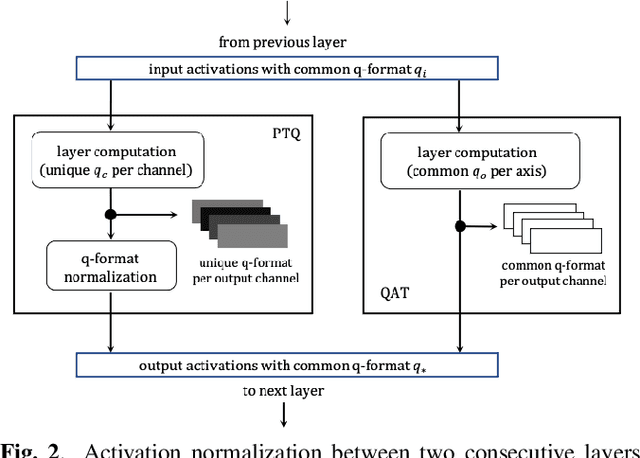
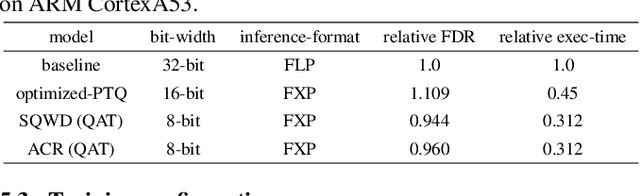
Fixed-point (FXP) inference has proven suitable for embedded devices with limited computational resources, and yet model training is continually performed in floating-point (FLP). FXP training has not been fully explored and the non-trivial conversion from FLP to FXP presents unavoidable performance drop. We propose a novel method to train and obtain FXP convolutional keyword-spotting (KWS) models. We combine our methodology with two quantization-aware-training (QAT) techniques - squashed weight distribution and absolute cosine regularization for model parameters, and propose techniques for extending QAT over transient variables, otherwise neglected by previous paradigms. Experimental results on the Google Speech Commands v2 dataset show that we can reduce model precision up to 4-bit with no loss in accuracy. Furthermore, on an in-house KWS dataset, we show that our 8-bit FXP-QAT models have a 4-6% improvement in relative false discovery rate at fixed false reject rate compared to full precision FLP models. During inference we argue that FXP-QAT eliminates q-format normalization and enables the use of low-bit accumulators while maximizing SIMD throughput to reduce user perceived latency. We demonstrate that we can reduce execution time by 68% without compromising KWS model's predictive performance or requiring model architectural changes. Our work provides novel findings that aid future research in this area and enable accurate and efficient models.
* 5 pages, 3 figures, 4 tables
The International Workshop on Osteoarthritis Imaging Knee MRI Segmentation Challenge: A Multi-Institute Evaluation and Analysis Framework on a Standardized Dataset
May 26, 2020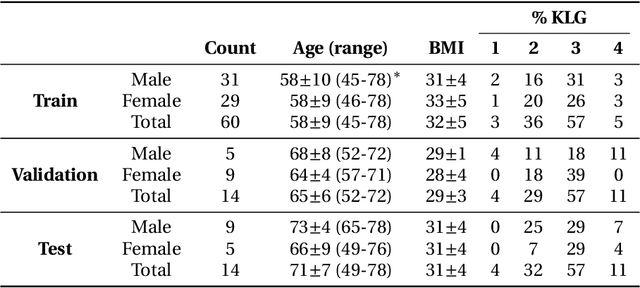
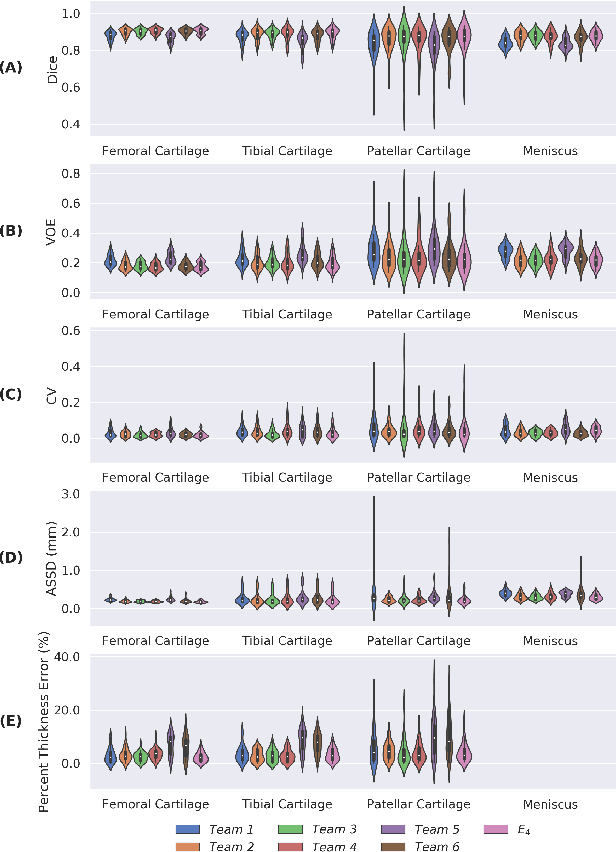
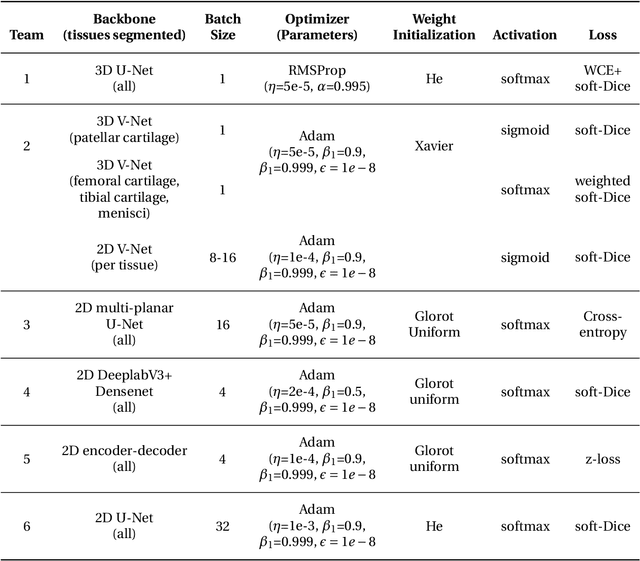
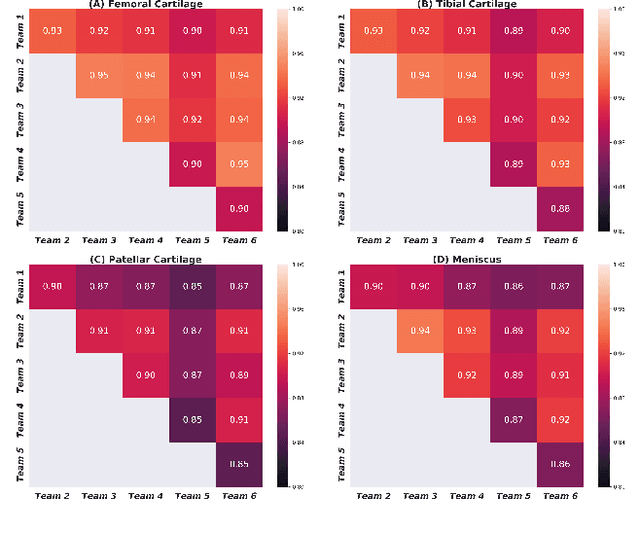
Purpose: To organize a knee MRI segmentation challenge for characterizing the semantic and clinical efficacy of automatic segmentation methods relevant for monitoring osteoarthritis progression. Methods: A dataset partition consisting of 3D knee MRI from 88 subjects at two timepoints with ground-truth articular (femoral, tibial, patellar) cartilage and meniscus segmentations was standardized. Challenge submissions and a majority-vote ensemble were evaluated using Dice score, average symmetric surface distance, volumetric overlap error, and coefficient of variation on a hold-out test set. Similarities in network segmentations were evaluated using pairwise Dice correlations. Articular cartilage thickness was computed per-scan and longitudinally. Correlation between thickness error and segmentation metrics was measured using Pearson's coefficient. Two empirical upper bounds for ensemble performance were computed using combinations of model outputs that consolidated true positives and true negatives. Results: Six teams (T1-T6) submitted entries for the challenge. No significant differences were observed across all segmentation metrics for all tissues (p=1.0) among the four top-performing networks (T2, T3, T4, T6). Dice correlations between network pairs were high (>0.85). Per-scan thickness errors were negligible among T1-T4 (p=0.99) and longitudinal changes showed minimal bias (<0.03mm). Low correlations (<0.41) were observed between segmentation metrics and thickness error. The majority-vote ensemble was comparable to top performing networks (p=1.0). Empirical upper bound performances were similar for both combinations (p=1.0). Conclusion: Diverse networks learned to segment the knee similarly where high segmentation accuracy did not correlate to cartilage thickness accuracy. Voting ensembles did not outperform individual networks but may help regularize individual models.
Hierarchical Severity Staging of Anterior Cruciate Ligament Injuries using Deep Learning with MRI Images
Apr 13, 2020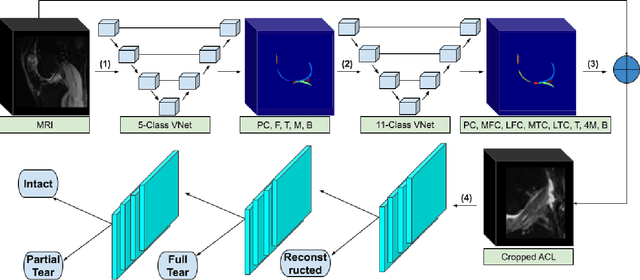
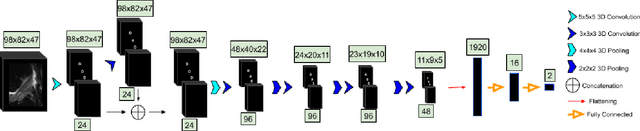
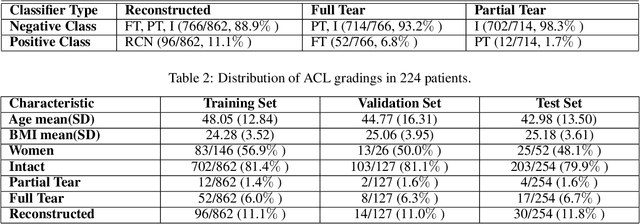
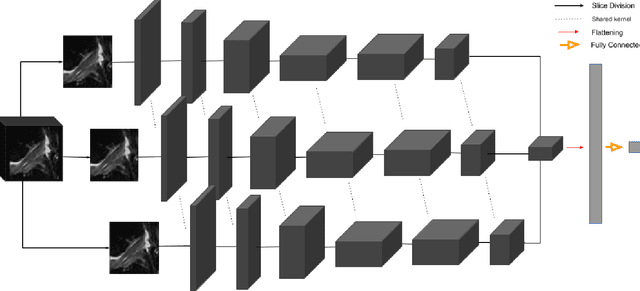
Purpose: To evaluate the diagnostic utility of two convolutional neural networks (CNNs) for severity staging of anterior cruciate ligament (ACL) injuries. Materials and Methods: This retrospective analysis was conducted on 1243 knee MR images (1008 intact, 18 partially torn, 77 fully torn, and 140 reconstructed ACLs) from 224 patients (age 47 +/- 14 years, 54% women) acquired between 2011 and 2014. The radiologists used a modified scoring metric. To classify ACL injuries with deep learning, two types of CNNs were used, one with three-dimensional (3D) and the other with two-dimensional (2D) convolutional kernels. Performance metrics included sensitivity, specificity, weighted Cohen's kappa, and overall accuracy, followed by McNemar's test to compare the CNNs performance. Results: The overall accuracy and weighted Cohen's kappa reported for ACL injury classification were higher using the 2D CNN (accuracy: 92% (233/254) and kappa: 0.83) than the 3D CNN (accuracy: 89% (225/254) and kappa: 0.83) (P = .27). The 2D CNN and 3D CNN performed similarly in classifying intact ACLs (2D CNN: 93% (188/203) sensitivity and 90% (46/51) specificity; 3D CNN: 89% (180/203) sensitivity and 88% (45/51) specificity). Classification of full tears by both networks were also comparable (2D CNN: 82% (14/17) sensitivity and 94% (222/237) specificity; 3D CNN: 76% (13/17) sensitivity and 100% (236/237) specificity). The 2D CNN classified all reconstructed ACLs correctly. Conclusion: 2D and 3D CNNs applied to ACL lesion classification had high sensitivity and specificity, suggesting that these networks could be used to help grade ACL injuries by non-experts.
Distance Map Loss Penalty Term for Semantic Segmentation
Aug 10, 2019
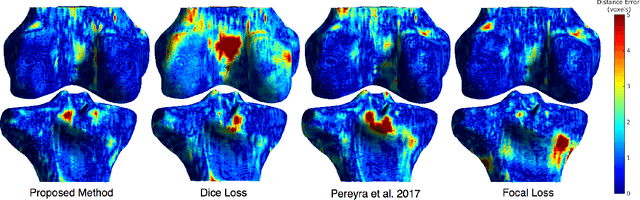
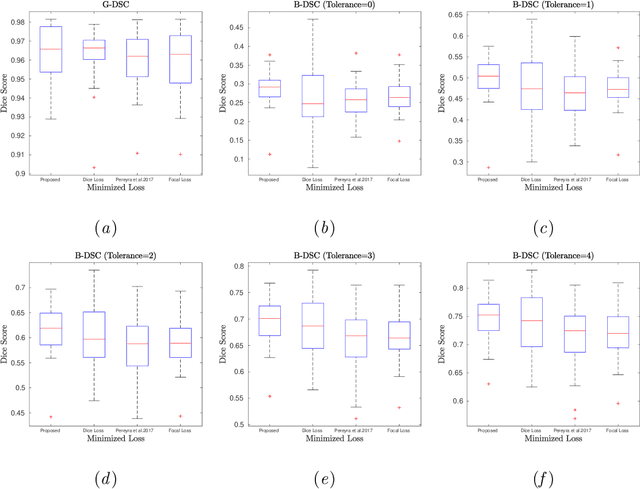
Convolutional neural networks for semantic segmentation suffer from low performance at object boundaries. In medical imaging, accurate representation of tissue surfaces and volumes is important for tracking of disease biomarkers such as tissue morphology and shape features. In this work, we propose a novel distance map derived loss penalty term for semantic segmentation. We propose to use distance maps, derived from ground truth masks, to create a penalty term, guiding the network's focus towards hard-to-segment boundary regions. We investigate the effects of this penalizing factor against cross-entropy, Dice, and focal loss, among others, evaluating performance on a 3D MRI bone segmentation task from the publicly available Osteoarthritis Initiative dataset. We observe a significant improvement in the quality of segmentation, with better shape preservation at bone boundaries and areas affected by partial volume. We ultimately aim to use our loss penalty term to improve the extraction of shape biomarkers and derive metrics to quantitatively evaluate the preservation of shape.
Deep Bayesian Uncertainty Estimation for Adaptation and Self-Annotation of Food Packaging Images
Nov 26, 2018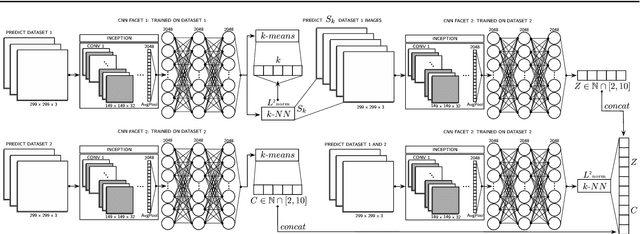
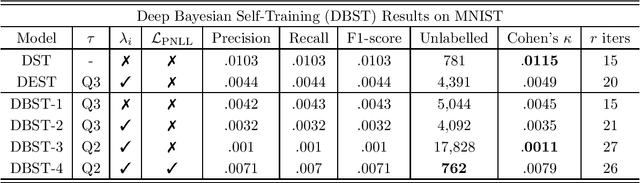
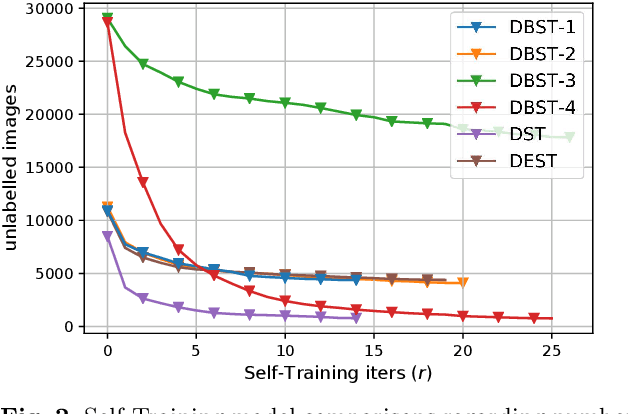
Food packaging labels provide important information for public health, such as allergens and use-by dates. Off-the-shelf Optical Character Verification (OCV) systems are good solutions for automating food label quality assessments, but are known to under perform on complex data. This paper proposes a Deep Learning based system that can identify inadequate images for OCV, due to their poor label quality, by employing state-of-the-art Convolutional Neural Network (CNN) architectures, and practical Bayesian inference techniques for automatic self-annotation. We propose a practical domain adaptation procedure based on k-means clustering of CNN latent variables, followed by a k-Nearest Neighbour classification for handling high label variability between different dataset distributions. Moreover, Supervised Learning has proven useful in such systems but manual annotation of large amounts of data is usually required. This is practically intractable in most real world problems due to time/labour constraints. In an attempt to address this issue, we introduce a self-annotating prediction model based on Self-Training of a Bayesian CNN, that leverages modern variational inference methods of deep models. In this context, we propose a new inverse uncertainty weighting technique that encourages the Self-Training model to learn from more informative data over time, potentially preventing it from becoming lazy by only selecting easy examples to learn from. An experimental study is presented illustrating the superior performance of the proposed approach over standard Self-Training, and highlighting the importance of predictive uncertainty estimates in safety-critical domains.
Towards a Deep Unified Framework for Nuclear Reactor Perturbation Analysis
Sep 08, 2018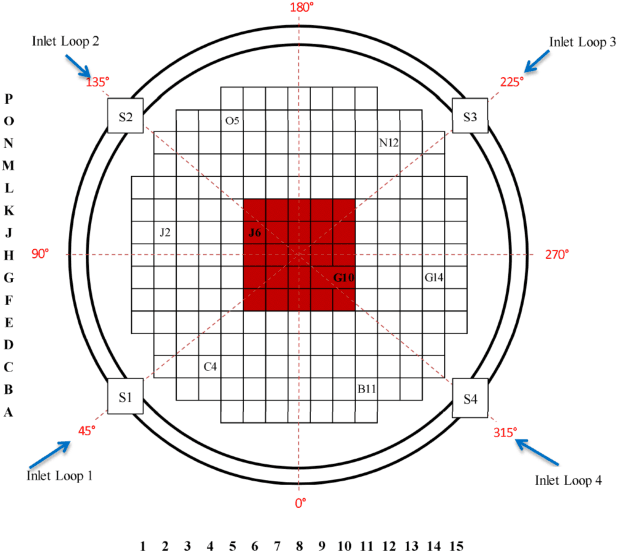
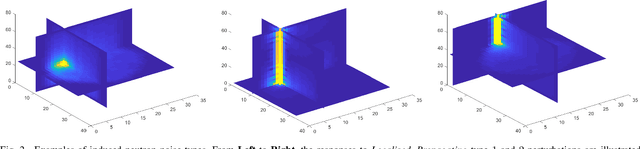


In this paper, we take the first steps towards a novel unified framework for the analysis of perturbations in both the Time and Frequency domains. The identification of type and source of such perturbations is fundamental for monitoring reactor cores and guarantee safety while running at nominal conditions. A 3D Convolutional Neural Network (3D-CNN) was employed to analyse perturbations happening in the frequency domain, such as an absorber of variable strength or propagating perturbation. Recurrent neural networks (RNN), specifically Long Short-Term Memory (LSTM) networks were used to study signal sequences related to perturbations induced in the time domain, including the vibrations of fuel assemblies and the fluctuations of thermal-hydraulic parameters at the inlet of the reactor coolant loops. 512 dimensional representations were extracted from the 3D-CNN and LSTM architectures, and used as input to a fused multi-sigmoid classification layer to recognise the perturbation type. If the perturbation is in the frequency domain, a separate fully-connected layer utilises said representations to regress the coordinates of its source. The results showed that the perturbation type can be recognised with high accuracy in all cases, and frequency domain scenario sources can be localised with high precision.