 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiAP: A Multi-Granular Stochastic Auto-Pruning Framework for Vision Transformers
Mar 12, 2026Vision Transformers require significant computational resources and memory bandwidth, severely limiting their deployment on edge devices. While recent structured pruning methods successfully reduce theoretical FLOPs, they typically operate at a single structural granularity and rely on complex, multi-stage pipelines with post-hoc thresholding to satisfy sparsity budgets. In this paper, we propose Hierarchical Auto-Pruning (HiAP), a continuous relaxation framework that discovers optimal sub-networks in a single end-to-end training phase without requiring manual importance heuristics or predefined per-layer sparsity targets. HiAP introduces stochastic Gumbel-Sigmoid gates at multiple granularities: macro-gates to prune entire attention heads and FFN blocks, and micro-gates to selectively prune intra-head dimensions and FFN neurons. By optimizing both levels simultaneously, HiAP addresses both the memory-bound overhead of loading large matrices and the compute-bound mathematical operations. HiAP naturally converges to stable sub-networks using a loss function that incorporates both structural feasibility penalties and analytical FLOPs. Extensive experiments on ImageNet demonstrate that HiAP organically discovers highly efficient architectures, and achieves a competitive accuracy-efficiency Pareto frontier for models like DeiT-Small, matching the performance of sophisticated multi-stage methods while significantly simplifying the deployment pipeline.
MMDEW: Multipurpose Multiclass Density Estimation in the Wild
Oct 02, 2025Density map estimation can be used to estimate object counts in dense and occluded scenes where discrete counting-by-detection methods fail. We propose a multicategory counting framework that leverages a Twins pyramid vision-transformer backbone and a specialised multi-class counting head built on a state-of-the-art multiscale decoding approach. A two-task design adds a segmentation-based Category Focus Module, suppressing inter-category cross-talk at training time. Training and evaluation on the VisDrone and iSAID benchmarks demonstrates superior performance versus prior multicategory crowd-counting approaches (33%, 43% and 64% reduction to MAE), and the comparison with YOLOv11 underscores the necessity of crowd counting methods in dense scenes. The method's regional loss opens up multi-class crowd counting to new domains, demonstrated through the application to a biodiversity monitoring dataset, highlighting its capacity to inform conservation efforts and enable scalable ecological insights.
EquiCaps: Predictor-Free Pose-Aware Pre-Trained Capsule Networks
Jun 11, 2025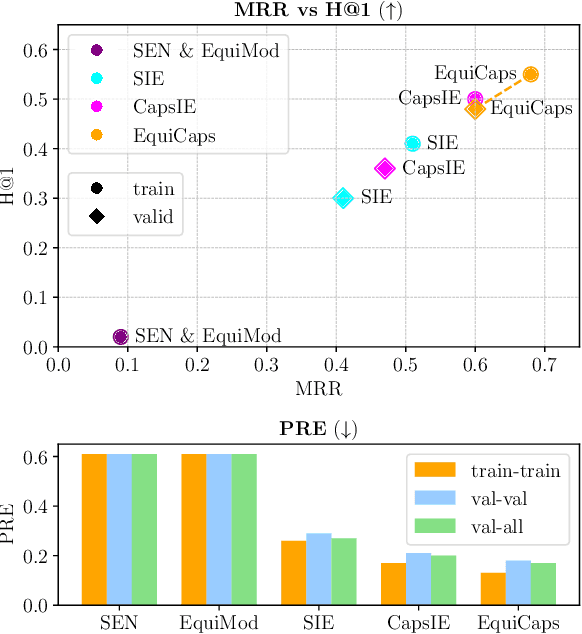
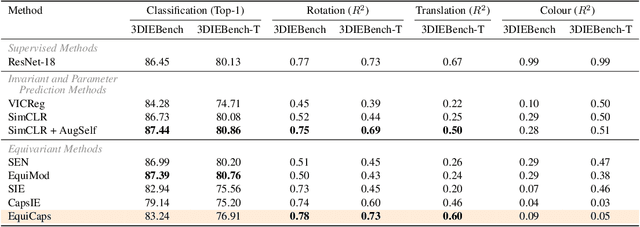
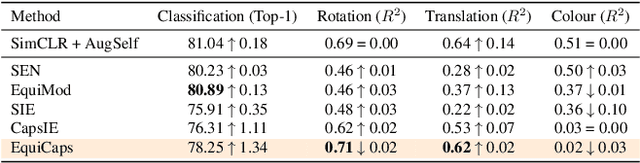
Learning self-supervised representations that are invariant and equivariant to transformations is crucial for advancing beyond traditional visual classification tasks. However, many methods rely on predictor architectures to encode equivariance, despite evidence that architectural choices, such as capsule networks, inherently excel at learning interpretable pose-aware representations. To explore this, we introduce EquiCaps (Equivariant Capsule Network), a capsule-based approach to pose-aware self-supervision that eliminates the need for a specialised predictor for enforcing equivariance. Instead, we leverage the intrinsic pose-awareness capabilities of capsules to improve performance in pose estimation tasks. To further challenge our assumptions, we increase task complexity via multi-geometric transformations to enable a more thorough evaluation of invariance and equivariance by introducing 3DIEBench-T, an extension of a 3D object-rendering benchmark dataset. Empirical results demonstrate that EquiCaps outperforms prior state-of-the-art equivariant methods on rotation prediction, achieving a supervised-level $R^2$ of 0.78 on the 3DIEBench rotation prediction benchmark and improving upon SIE and CapsIE by 0.05 and 0.04 $R^2$, respectively. Moreover, in contrast to non-capsule-based equivariant approaches, EquiCaps maintains robust equivariant performance under combined geometric transformations, underscoring its generalisation capabilities and the promise of predictor-free capsule architectures.
Enhancing Strawberry Yield Forecasting with Backcasted IoT Sensor Data and Machine Learning
Apr 25, 2025Due to rapid population growth globally, digitally-enabled agricultural sectors are crucial for sustainable food production and making informed decisions about resource management for farmers and various stakeholders. The deployment of Internet of Things (IoT) technologies that collect real-time observations of various environmental (e.g., temperature, humidity, etc.) and operational factors (e.g., irrigation) influencing production is often seen as a critical step to enable additional novel downstream tasks, such as AI-based yield forecasting. However, since AI models require large amounts of data, this creates practical challenges in a real-world dynamic farm setting where IoT observations would need to be collected over a number of seasons. In this study, we deployed IoT sensors in strawberry production polytunnels for two growing seasons to collect environmental data, including water usage, external and internal temperature, external and internal humidity, soil moisture, soil temperature, and photosynthetically active radiation. The sensor observations were combined with manually provided yield records spanning a period of four seasons. To bridge the gap of missing IoT observations for two additional seasons, we propose an AI-based backcasting approach to generate synthetic sensor observations using historical weather data from a nearby weather station and the existing polytunnel observations. We built an AI-based yield forecasting model to evaluate our approach using the combination of real and synthetic observations. Our results demonstrated that incorporating synthetic data improved yield forecasting accuracy, with models incorporating synthetic data outperforming those trained only on historical yield, weather records, and real sensor data.
Pushing the Limits of Sparsity: A Bag of Tricks for Extreme Pruning
Nov 21, 2024



Pruning of deep neural networks has been an effective technique for reducing model size while preserving most of the performance of dense networks, crucial for deploying models on memory and power-constrained devices. While recent sparse learning methods have shown promising performance up to moderate sparsity levels such as 95% and 98%, accuracy quickly deteriorates when pushing sparsities to extreme levels. Obtaining sparse networks at such extreme sparsity levels presents unique challenges, such as fragile gradient flow and heightened risk of layer collapse. In this work, we explore network performance beyond the commonly studied sparsities, and propose a collection of techniques that enable the continuous learning of networks without accuracy collapse even at extreme sparsities, including 99.90%, 99.95% and 99.99% on ResNet architectures. Our approach combines 1) Dynamic ReLU phasing, where DyReLU initially allows for richer parameter exploration before being gradually replaced by standard ReLU, 2) weight sharing which reuses parameters within a residual layer while maintaining the same number of learnable parameters, and 3) cyclic sparsity, where both sparsity levels and sparsity patterns evolve dynamically throughout training to better encourage parameter exploration. We evaluate our method, which we term Extreme Adaptive Sparse Training (EAST) at extreme sparsities using ResNet-34 and ResNet-50 on CIFAR-10, CIFAR-100, and ImageNet, achieving significant performance improvements over state-of-the-art methods we compared with.
Investigating the Capabilities of Deep Learning for Processing and Interpreting One-Shot Multi-offset GPR Data: A Numerical Case Study for Lunar and Martian Environments
Oct 18, 2024



Ground-penetrating radar (GPR) is a mature geophysical method that has gained increasing popularity in planetary science over the past decade. GPR has been utilised both for Lunar and Martian missions providing pivotal information regarding the near surface geology of Terrestrial planets. Within that context, numerous processing pipelines have been suggested to address the unique challenges present in planetary setups. These processing pipelines often require manual tuning resulting to ambiguous outputs open to non-unique interpretations. These pitfalls combined with the large number of planetary GPR data (kilometers in magnitude), highlight the necessity for automatic, objective and advanced processing and interpretation schemes. The current paper investigates the potential of deep learning for interpreting and processing GPR data. The one-shot multi-offset configuration is investigated via a coherent numerical case study, showcasing the potential of deep learning for A) reconstructing the dielectric distribution of the the near surface of Terrestrial planets, and B) filling missing or bad-quality traces. Special care was taken for the numerical data to be both realistic and challenging. Moreover, the generated synthetic data are properly labelled and made publicly available for training future data-driven pipelines and contributing towards developing pre-trained foundation models for GPR.
Capsule Network Projectors are Equivariant and Invariant Learners
May 23, 2024Learning invariant representations has been the longstanding approach to self-supervised learning. However, recently progress has been made in preserving equivariant properties in representations, yet do so with highly prescribed architectures. In this work, we propose an invariant-equivariant self-supervised architecture that employs Capsule Networks (CapsNets) which have been shown to capture equivariance with respect to novel viewpoints. We demonstrate that the use of CapsNets in equivariant self-supervised architectures achieves improved downstream performance on equivariant tasks with higher efficiency and fewer network parameters. To accommodate the architectural changes of CapsNets, we introduce a new objective function based on entropy minimisation. This approach, which we name CapsIE (Capsule Invariant Equivariant Network), achieves state-of-the-art performance across all invariant and equivariant downstream tasks on the 3DIEBench dataset, while outperforming supervised baselines. Our results demonstrate the ability of CapsNets to learn complex and generalised representations for large-scale, multi-task datasets compared to previous CapsNet benchmarks. Code is available at https://github.com/AberdeenML/CapsIE.
LeOCLR: Leveraging Original Images for Contrastive Learning of Visual Representations
Mar 11, 2024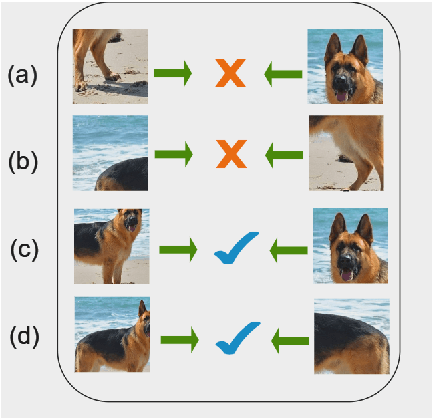
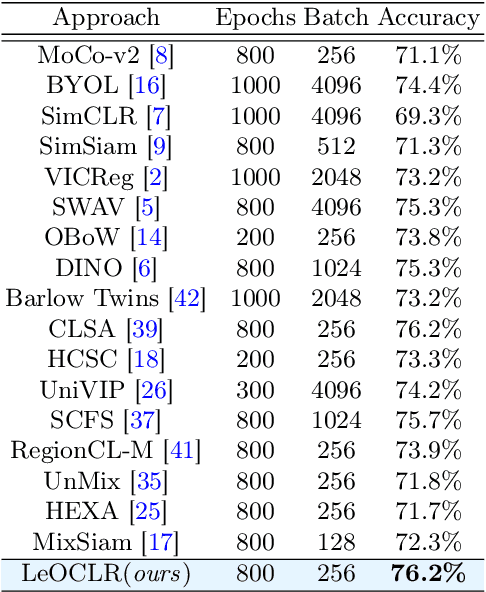
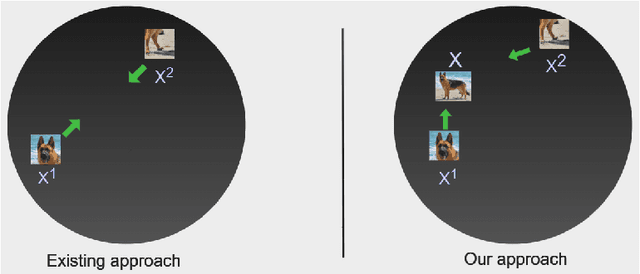
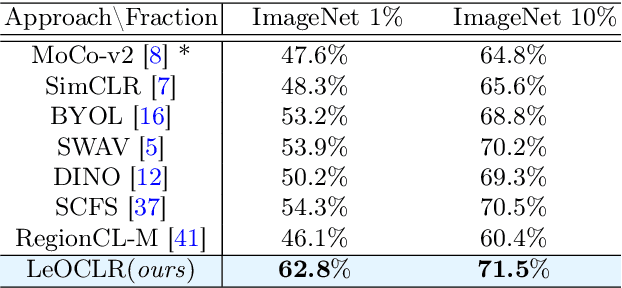
Contrastive instance discrimination outperforms supervised learning in downstream tasks like image classification and object detection. However, this approach heavily relies on data augmentation during representation learning, which may result in inferior results if not properly implemented. Random cropping followed by resizing is a common form of data augmentation used in contrastive learning, but it can lead to degraded representation learning if the two random crops contain distinct semantic content. To address this issue, this paper introduces LeOCLR (Leveraging Original Images for Contrastive Learning of Visual Representations), a framework that employs a new instance discrimination approach and an adapted loss function that ensures the shared region between positive pairs is semantically correct. The experimental results show that our approach consistently improves representation learning across different datasets compared to baseline models. For example, our approach outperforms MoCo-v2 by 5.1% on ImageNet-1K in linear evaluation and several other methods on transfer learning tasks.
Masked Capsule Autoencoders
Mar 07, 2024We propose Masked Capsule Autoencoders (MCAE), the first Capsule Network that utilises pretraining in a self-supervised manner. Capsule Networks have emerged as a powerful alternative to Convolutional Neural Networks (CNNs), and have shown favourable properties when compared to Vision Transformers (ViT), but have struggled to effectively learn when presented with more complex data, leading to Capsule Network models that do not scale to modern tasks. Our proposed MCAE model alleviates this issue by reformulating the Capsule Network to use masked image modelling as a pretraining stage before finetuning in a supervised manner. Across several experiments and ablations studies we demonstrate that similarly to CNNs and ViTs, Capsule Networks can also benefit from self-supervised pretraining, paving the way for further advancements in this neural network domain. For instance, pretraining on the Imagenette dataset, a dataset of 10 classes of Imagenet-sized images, we achieve not only state-of-the-art results for Capsule Networks but also a 9% improvement compared to purely supervised training. Thus we propose that Capsule Networks benefit from and should be trained within a masked image modelling framework, with a novel capsule decoder, to improve a Capsule Network's performance on realistic-sized images.
ProtoCaps: A Fast and Non-Iterative Capsule Network Routing Method
Jul 19, 2023Capsule Networks have emerged as a powerful class of deep learning architectures, known for robust performance with relatively few parameters compared to Convolutional Neural Networks (CNNs). However, their inherent efficiency is often overshadowed by their slow, iterative routing mechanisms which establish connections between Capsule layers, posing computational challenges resulting in an inability to scale. In this paper, we introduce a novel, non-iterative routing mechanism, inspired by trainable prototype clustering. This innovative approach aims to mitigate computational complexity, while retaining, if not enhancing, performance efficacy. Furthermore, we harness a shared Capsule subspace, negating the need to project each lower-level Capsule to each higher-level Capsule, thereby significantly reducing memory requisites during training. Our approach demonstrates superior results compared to the current best non-iterative Capsule Network and tests on the Imagewoof dataset, which is too computationally demanding to handle efficiently by iterative approaches. Our findings underscore the potential of our proposed methodology in enhancing the operational efficiency and performance of Capsule Networks, paving the way for their application in increasingly complex computational scenarios.