 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapsule Network Projectors are Equivariant and Invariant Learners
May 23, 2024Learning invariant representations has been the longstanding approach to self-supervised learning. However, recently progress has been made in preserving equivariant properties in representations, yet do so with highly prescribed architectures. In this work, we propose an invariant-equivariant self-supervised architecture that employs Capsule Networks (CapsNets) which have been shown to capture equivariance with respect to novel viewpoints. We demonstrate that the use of CapsNets in equivariant self-supervised architectures achieves improved downstream performance on equivariant tasks with higher efficiency and fewer network parameters. To accommodate the architectural changes of CapsNets, we introduce a new objective function based on entropy minimisation. This approach, which we name CapsIE (Capsule Invariant Equivariant Network), achieves state-of-the-art performance across all invariant and equivariant downstream tasks on the 3DIEBench dataset, while outperforming supervised baselines. Our results demonstrate the ability of CapsNets to learn complex and generalised representations for large-scale, multi-task datasets compared to previous CapsNet benchmarks. Code is available at https://github.com/AberdeenML/CapsIE.
Masked Capsule Autoencoders
Mar 07, 2024We propose Masked Capsule Autoencoders (MCAE), the first Capsule Network that utilises pretraining in a self-supervised manner. Capsule Networks have emerged as a powerful alternative to Convolutional Neural Networks (CNNs), and have shown favourable properties when compared to Vision Transformers (ViT), but have struggled to effectively learn when presented with more complex data, leading to Capsule Network models that do not scale to modern tasks. Our proposed MCAE model alleviates this issue by reformulating the Capsule Network to use masked image modelling as a pretraining stage before finetuning in a supervised manner. Across several experiments and ablations studies we demonstrate that similarly to CNNs and ViTs, Capsule Networks can also benefit from self-supervised pretraining, paving the way for further advancements in this neural network domain. For instance, pretraining on the Imagenette dataset, a dataset of 10 classes of Imagenet-sized images, we achieve not only state-of-the-art results for Capsule Networks but also a 9% improvement compared to purely supervised training. Thus we propose that Capsule Networks benefit from and should be trained within a masked image modelling framework, with a novel capsule decoder, to improve a Capsule Network's performance on realistic-sized images.
ProtoCaps: A Fast and Non-Iterative Capsule Network Routing Method
Jul 19, 2023Capsule Networks have emerged as a powerful class of deep learning architectures, known for robust performance with relatively few parameters compared to Convolutional Neural Networks (CNNs). However, their inherent efficiency is often overshadowed by their slow, iterative routing mechanisms which establish connections between Capsule layers, posing computational challenges resulting in an inability to scale. In this paper, we introduce a novel, non-iterative routing mechanism, inspired by trainable prototype clustering. This innovative approach aims to mitigate computational complexity, while retaining, if not enhancing, performance efficacy. Furthermore, we harness a shared Capsule subspace, negating the need to project each lower-level Capsule to each higher-level Capsule, thereby significantly reducing memory requisites during training. Our approach demonstrates superior results compared to the current best non-iterative Capsule Network and tests on the Imagewoof dataset, which is too computationally demanding to handle efficiently by iterative approaches. Our findings underscore the potential of our proposed methodology in enhancing the operational efficiency and performance of Capsule Networks, paving the way for their application in increasingly complex computational scenarios.
Vanishing Activations: A Symptom of Deep Capsule Networks
May 13, 2023Capsule Networks, an extension to Neural Networks utilizing vector or matrix representations instead of scalars, were initially developed to create a dynamic parse tree where visual concepts evolve from parts to complete objects. Early implementations of Capsule Networks achieved and maintain state-of-the-art results on various datasets. However, recent studies have revealed shortcomings in the original Capsule Network architecture, notably its failure to construct a parse tree and its susceptibility to vanishing gradients when deployed in deeper networks. This paper extends the investigation to a range of leading Capsule Network architectures, demonstrating that these issues are not confined to the original design. We argue that the majority of Capsule Network research has produced architectures that, while modestly divergent from the original Capsule Network, still retain a fundamentally similar structure. We posit that this inherent design similarity might be impeding the scalability of Capsule Networks. Our study contributes to the broader discussion on improving the robustness and scalability of Capsule Networks.
Learning with Capsules: A Survey
Jun 06, 2022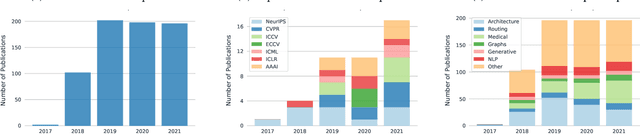
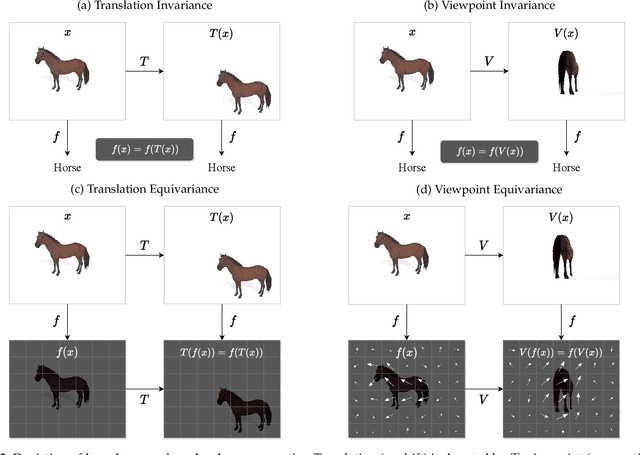
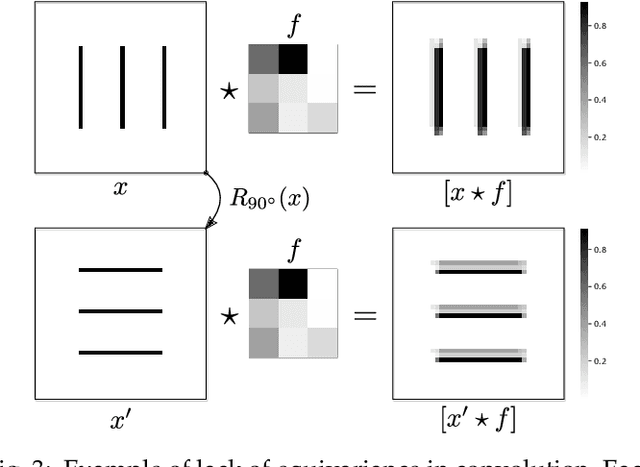
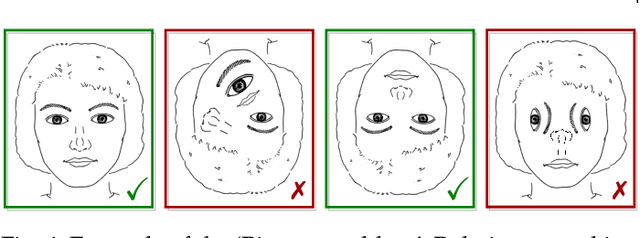
Capsule networks were proposed as an alternative approach to Convolutional Neural Networks (CNNs) for learning object-centric representations, which can be leveraged for improved generalization and sample complexity. Unlike CNNs, capsule networks are designed to explicitly model part-whole hierarchical relationships by using groups of neurons to encode visual entities, and learn the relationships between those entities. Promising early results achieved by capsule networks have motivated the deep learning community to continue trying to improve their performance and scalability across several application areas. However, a major hurdle for capsule network research has been the lack of a reliable point of reference for understanding their foundational ideas and motivations. The aim of this survey is to provide a comprehensive overview of the capsule network research landscape, which will serve as a valuable resource for the community going forward. To that end, we start with an introduction to the fundamental concepts and motivations behind capsule networks, such as equivariant inference in computer vision. We then cover the technical advances in the capsule routing mechanisms and the various formulations of capsule networks, e.g. generative and geometric. Additionally, we provide a detailed explanation of how capsule networks relate to the popular attention mechanism in Transformers, and highlight non-trivial conceptual similarities between them in the context of representation learning. Afterwards, we explore the extensive applications of capsule networks in computer vision, video and motion, graph representation learning, natural language processing, medical imaging and many others. To conclude, we provide an in-depth discussion regarding the main hurdles in capsule network research, and highlight promising research directions for future work.