 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquiCaps: Predictor-Free Pose-Aware Pre-Trained Capsule Networks
Jun 11, 2025Learning self-supervised representations that are invariant and equivariant to transformations is crucial for advancing beyond traditional visual classification tasks. However, many methods rely on predictor architectures to encode equivariance, despite evidence that architectural choices, such as capsule networks, inherently excel at learning interpretable pose-aware representations. To explore this, we introduce EquiCaps (Equivariant Capsule Network), a capsule-based approach to pose-aware self-supervision that eliminates the need for a specialised predictor for enforcing equivariance. Instead, we leverage the intrinsic pose-awareness capabilities of capsules to improve performance in pose estimation tasks. To further challenge our assumptions, we increase task complexity via multi-geometric transformations to enable a more thorough evaluation of invariance and equivariance by introducing 3DIEBench-T, an extension of a 3D object-rendering benchmark dataset. Empirical results demonstrate that EquiCaps outperforms prior state-of-the-art equivariant methods on rotation prediction, achieving a supervised-level $R^2$ of 0.78 on the 3DIEBench rotation prediction benchmark and improving upon SIE and CapsIE by 0.05 and 0.04 $R^2$, respectively. Moreover, in contrast to non-capsule-based equivariant approaches, EquiCaps maintains robust equivariant performance under combined geometric transformations, underscoring its generalisation capabilities and the promise of predictor-free capsule architectures.
Monkey Transfer Learning Can Improve Human Pose Estimation
Dec 20, 2024In this study, we investigated whether transfer learning from macaque monkeys could improve human pose estimation. Current state-of-the-art pose estimation techniques, often employing deep neural networks, can match human annotation in non-clinical datasets. However, they underperform in novel situations, limiting their generalisability to clinical populations with pathological movement patterns. Clinical datasets are not widely available for AI training due to ethical challenges and a lack of data collection. We observe that data from other species may be able to bridge this gap by exposing the network to a broader range of motion cues. We found that utilising data from other species and undertaking transfer learning improved human pose estimation in terms of precision and recall compared to the benchmark, which was trained on humans only. Compared to the benchmark, fewer human training examples were needed for the transfer learning approach (1,000 vs 19,185). These results suggest that macaque pose estimation can improve human pose estimation in clinical situations. Future work should further explore the utility of pose estimation trained with monkey data in clinical populations.
Pushing the Limits of Sparsity: A Bag of Tricks for Extreme Pruning
Nov 21, 2024



Pruning of deep neural networks has been an effective technique for reducing model size while preserving most of the performance of dense networks, crucial for deploying models on memory and power-constrained devices. While recent sparse learning methods have shown promising performance up to moderate sparsity levels such as 95% and 98%, accuracy quickly deteriorates when pushing sparsities to extreme levels. Obtaining sparse networks at such extreme sparsity levels presents unique challenges, such as fragile gradient flow and heightened risk of layer collapse. In this work, we explore network performance beyond the commonly studied sparsities, and propose a collection of techniques that enable the continuous learning of networks without accuracy collapse even at extreme sparsities, including 99.90%, 99.95% and 99.99% on ResNet architectures. Our approach combines 1) Dynamic ReLU phasing, where DyReLU initially allows for richer parameter exploration before being gradually replaced by standard ReLU, 2) weight sharing which reuses parameters within a residual layer while maintaining the same number of learnable parameters, and 3) cyclic sparsity, where both sparsity levels and sparsity patterns evolve dynamically throughout training to better encourage parameter exploration. We evaluate our method, which we term Extreme Adaptive Sparse Training (EAST) at extreme sparsities using ResNet-34 and ResNet-50 on CIFAR-10, CIFAR-100, and ImageNet, achieving significant performance improvements over state-of-the-art methods we compared with.
Capsule Network Projectors are Equivariant and Invariant Learners
May 23, 2024Learning invariant representations has been the longstanding approach to self-supervised learning. However, recently progress has been made in preserving equivariant properties in representations, yet do so with highly prescribed architectures. In this work, we propose an invariant-equivariant self-supervised architecture that employs Capsule Networks (CapsNets) which have been shown to capture equivariance with respect to novel viewpoints. We demonstrate that the use of CapsNets in equivariant self-supervised architectures achieves improved downstream performance on equivariant tasks with higher efficiency and fewer network parameters. To accommodate the architectural changes of CapsNets, we introduce a new objective function based on entropy minimisation. This approach, which we name CapsIE (Capsule Invariant Equivariant Network), achieves state-of-the-art performance across all invariant and equivariant downstream tasks on the 3DIEBench dataset, while outperforming supervised baselines. Our results demonstrate the ability of CapsNets to learn complex and generalised representations for large-scale, multi-task datasets compared to previous CapsNet benchmarks. Code is available at https://github.com/AberdeenML/CapsIE.
S-JEA: Stacked Joint Embedding Architectures for Self-Supervised Visual Representation Learning
May 19, 2023The recent emergence of Self-Supervised Learning (SSL) as a fundamental paradigm for learning image representations has, and continues to, demonstrate high empirical success in a variety of tasks. However, most SSL approaches fail to learn embeddings that capture hierarchical semantic concepts that are separable and interpretable. In this work, we aim to learn highly separable semantic hierarchical representations by stacking Joint Embedding Architectures (JEA) where higher-level JEAs are input with representations of lower-level JEA. This results in a representation space that exhibits distinct sub-categories of semantic concepts (e.g., model and colour of vehicles) in higher-level JEAs. We empirically show that representations from stacked JEA perform on a similar level as traditional JEA with comparative parameter counts and visualise the representation spaces to validate the semantic hierarchies.
HMSN: Hyperbolic Self-Supervised Learning by Clustering with Ideal Prototypes
May 18, 2023



Hyperbolic manifolds for visual representation learning allow for effective learning of semantic class hierarchies by naturally embedding tree-like structures with low distortion within a low-dimensional representation space. The highly separable semantic class hierarchies produced by hyperbolic learning have shown to be powerful in low-shot tasks, however, their application in self-supervised learning is yet to be explored fully. In this work, we explore the use of hyperbolic representation space for self-supervised representation learning for prototype-based clustering approaches. First, we extend the Masked Siamese Networks to operate on the Poincar\'e ball model of hyperbolic space, secondly, we place prototypes on the ideal boundary of the Poincar\'e ball. Unlike previous methods we project to the hyperbolic space at the output of the encoder network and utilise a hyperbolic projection head to ensure that the representations used for downstream tasks remain hyperbolic. Empirically we demonstrate the ability of these methods to perform comparatively to Euclidean methods in lower dimensions for linear evaluation tasks, whilst showing improvements in extreme few-shot learning tasks.
Hyperspherically Regularized Networks for BYOL Improves Feature Uniformity and Separability
Apr 29, 2021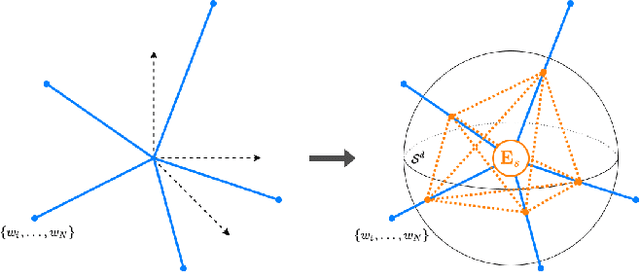

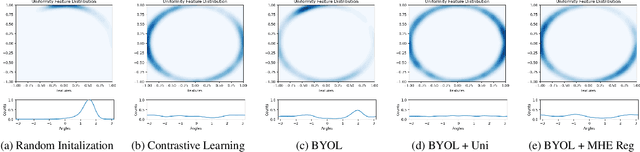

Bootstrap Your Own Latent (BYOL) introduced an approach to self-supervised learning avoiding the contrastive paradigm and subsequently removing the computational burden of negative sampling. However, feature representations under this paradigm are poorly distributed on the surface of the unit-hypersphere representation space compared to contrastive methods. This work empirically demonstrates that feature diversity enforced by contrastive losses is beneficial when employed in BYOL, and as such, provides greater inter-class feature separability. Therefore to achieve a more uniform distribution of features, we advocate the minimization of hyperspherical energy (i.e. maximization of entropy) in BYOL network weights. We show that directly optimizing a measure of uniformity alongside the standard loss, or regularizing the networks of the BYOL architecture to minimize the hyperspherical energy of neurons can produce more uniformly distributed and better performing representations for downstream tasks.
The Role of Cross-Silo Federated Learning in Facilitating Data Sharing in the Agri-Food Sector
Apr 14, 2021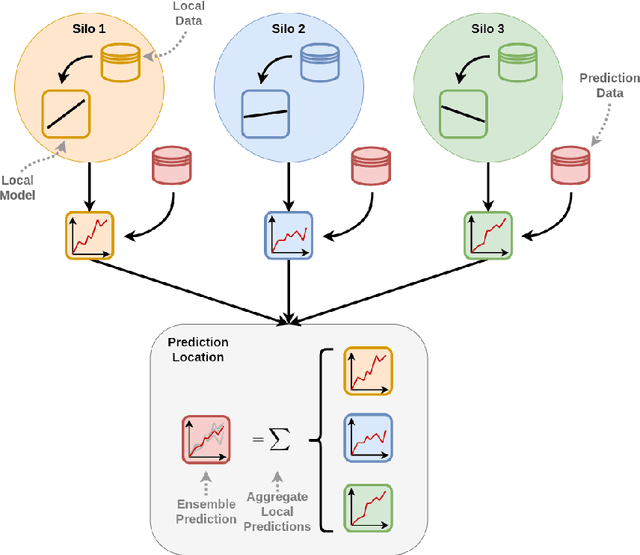

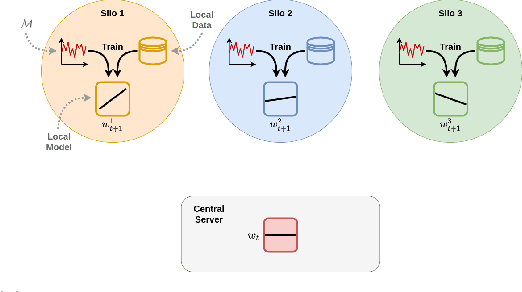
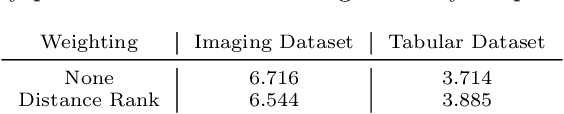
Data sharing remains a major hindering factor when it comes to adopting emerging AI technologies in general, but particularly in the agri-food sector. Protectiveness of data is natural in this setting; data is a precious commodity for data owners, which if used properly can provide them with useful insights on operations and processes leading to a competitive advantage. Unfortunately, novel AI technologies often require large amounts of training data in order to perform well, something that in many scenarios is unrealistic. However, recent machine learning advances, e.g. federated learning and privacy-preserving technologies, can offer a solution to this issue via providing the infrastructure and underpinning technologies needed to use data from various sources to train models without ever sharing the raw data themselves. In this paper, we propose a technical solution based on federated learning that uses decentralized data, (i.e. data that are not exchanged or shared but remain with the owners) to develop a cross-silo machine learning model that facilitates data sharing across supply chains. We focus our data sharing proposition on improving production optimization through soybean yield prediction, and provide potential use-cases that such methods can assist in other problem settings. Our results demonstrate that our approach not only performs better than each of the models trained on an individual data source, but also that data sharing in the agri-food sector can be enabled via alternatives to data exchange, whilst also helping to adopt emerging machine learning technologies to boost productivity.