 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Cross-Silo Federated Learning in Facilitating Data Sharing in the Agri-Food Sector
Apr 14, 2021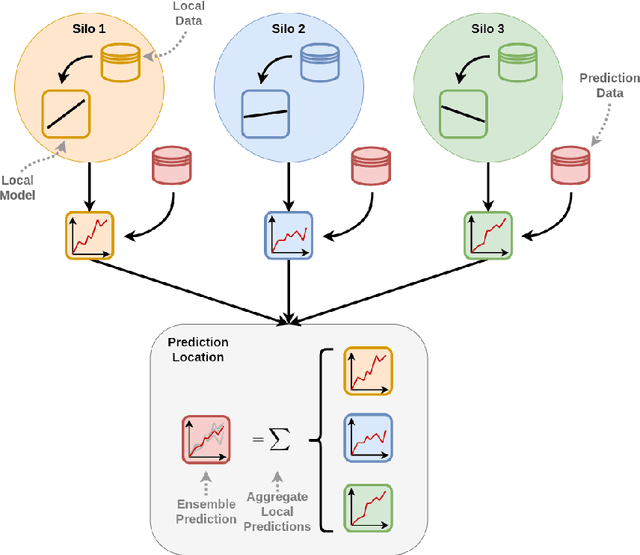

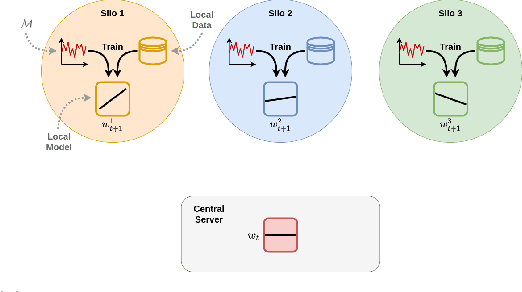
Data sharing remains a major hindering factor when it comes to adopting emerging AI technologies in general, but particularly in the agri-food sector. Protectiveness of data is natural in this setting; data is a precious commodity for data owners, which if used properly can provide them with useful insights on operations and processes leading to a competitive advantage. Unfortunately, novel AI technologies often require large amounts of training data in order to perform well, something that in many scenarios is unrealistic. However, recent machine learning advances, e.g. federated learning and privacy-preserving technologies, can offer a solution to this issue via providing the infrastructure and underpinning technologies needed to use data from various sources to train models without ever sharing the raw data themselves. In this paper, we propose a technical solution based on federated learning that uses decentralized data, (i.e. data that are not exchanged or shared but remain with the owners) to develop a cross-silo machine learning model that facilitates data sharing across supply chains. We focus our data sharing proposition on improving production optimization through soybean yield prediction, and provide potential use-cases that such methods can assist in other problem settings. Our results demonstrate that our approach not only performs better than each of the models trained on an individual data source, but also that data sharing in the agri-food sector can be enabled via alternatives to data exchange, whilst also helping to adopt emerging machine learning technologies to boost productivity.