 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquiCaps: Predictor-Free Pose-Aware Pre-Trained Capsule Networks
Jun 11, 2025Learning self-supervised representations that are invariant and equivariant to transformations is crucial for advancing beyond traditional visual classification tasks. However, many methods rely on predictor architectures to encode equivariance, despite evidence that architectural choices, such as capsule networks, inherently excel at learning interpretable pose-aware representations. To explore this, we introduce EquiCaps (Equivariant Capsule Network), a capsule-based approach to pose-aware self-supervision that eliminates the need for a specialised predictor for enforcing equivariance. Instead, we leverage the intrinsic pose-awareness capabilities of capsules to improve performance in pose estimation tasks. To further challenge our assumptions, we increase task complexity via multi-geometric transformations to enable a more thorough evaluation of invariance and equivariance by introducing 3DIEBench-T, an extension of a 3D object-rendering benchmark dataset. Empirical results demonstrate that EquiCaps outperforms prior state-of-the-art equivariant methods on rotation prediction, achieving a supervised-level $R^2$ of 0.78 on the 3DIEBench rotation prediction benchmark and improving upon SIE and CapsIE by 0.05 and 0.04 $R^2$, respectively. Moreover, in contrast to non-capsule-based equivariant approaches, EquiCaps maintains robust equivariant performance under combined geometric transformations, underscoring its generalisation capabilities and the promise of predictor-free capsule architectures.
LLEDA -- Lifelong Self-Supervised Domain Adaptation
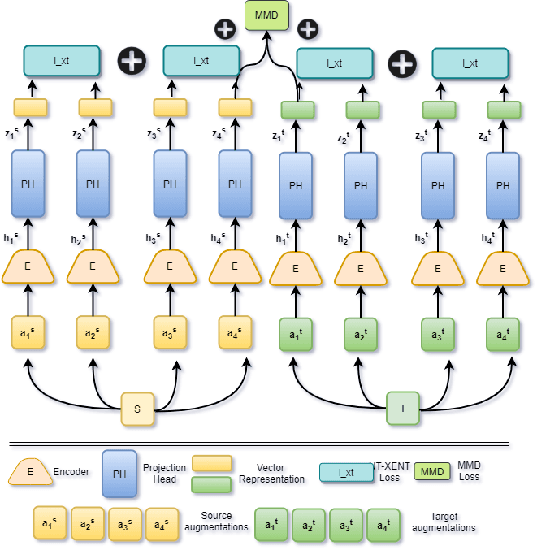
Nov 12, 2022Lifelong domain adaptation remains a challenging task in machine learning due to the differences among the domains and the unavailability of historical data. The ultimate goal is to learn the distributional shifts while retaining the previously gained knowledge. Inspired by the Complementary Learning Systems (CLS) theory, we propose a novel framework called Lifelong Self-Supervised Domain Adaptation (LLEDA). LLEDA addresses catastrophic forgetting by replaying hidden representations rather than raw data pixels and domain-agnostic knowledge transfer using self-supervised learning. LLEDA does not access labels from the source or the target domain and only has access to a single domain at any given time. Extensive experiments demonstrate that the proposed method outperforms several other methods and results in a long-term adaptation, while being less prone to catastrophic forgetting when transferred to new domains.
Contrastive Domain Adaptation
Mar 26, 2021


Recently, contrastive self-supervised learning has become a key component for learning visual representations across many computer vision tasks and benchmarks. However, contrastive learning in the context of domain adaptation remains largely underexplored. In this paper, we propose to extend contrastive learning to a new domain adaptation setting, a particular situation occurring where the similarity is learned and deployed on samples following different probability distributions without access to labels. Contrastive learning learns by comparing and contrasting positive and negative pairs of samples in an unsupervised setting without access to source and target labels. We have developed a variation of a recently proposed contrastive learning framework that helps tackle the domain adaptation problem, further identifying and removing possible negatives similar to the anchor to mitigate the effects of false negatives. Extensive experiments demonstrate that the proposed method adapts well, and improves the performance on the downstream domain adaptation task.
Multi-Source Deep Domain Adaptation for Quality Control in Retail Food Packaging
Jan 28, 2020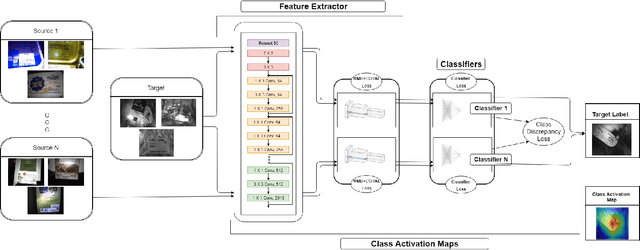


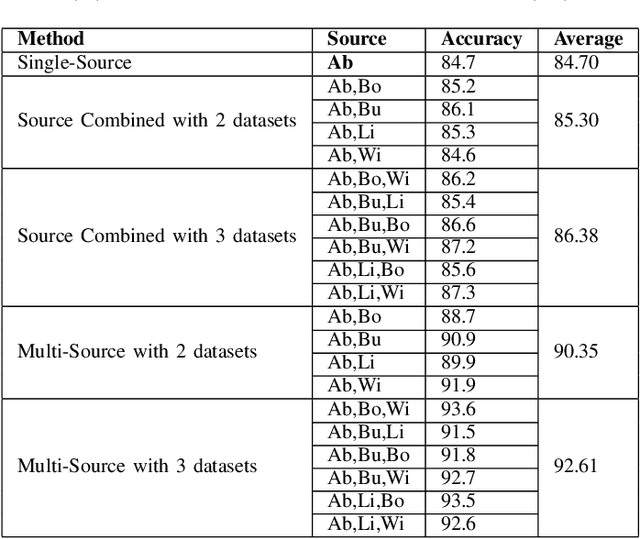
Retail food packaging contains information which informs choice and can be vital to consumer health, including product name, ingredients list, nutritional information, allergens, preparation guidelines, pack weight, storage and shelf life information (use-by / best before dates). The presence and accuracy of such information is critical to ensure a detailed understanding of the product and to reduce the potential for health risks. Consequently, erroneous or illegible labeling has the potential to be highly detrimental to consumers and many other stakeholders in the supply chain. In this paper, a multi-source deep learning-based domain adaptation system is proposed and tested to identify and verify the presence and legibility of use-by date information from food packaging photos taken as part of the validation process as the products pass along the food production line. This was achieved by improving the generalization of the techniques via making use of multi-source datasets in order to extract domain-invariant representations for all domains and aligning distribution of all pairs of source and target domains in a common feature space, along with the class boundaries. The proposed system performed very well in the conducted experiments, for automating the verification process and reducing labeling errors that could otherwise threaten public health and contravene legal requirements for food packaging information and accuracy. Comprehensive experiments on our food packaging datasets demonstrate that the proposed multi-source deep domain adaptation method significantly improves the classification accuracy and therefore has great potential for application and beneficial impact in food manufacturing control systems.