 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Capsules: A Survey
Paper and Code
Jun 06, 2022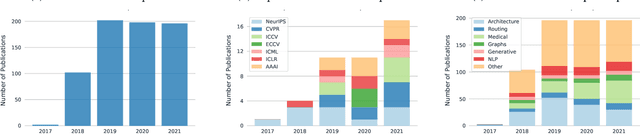
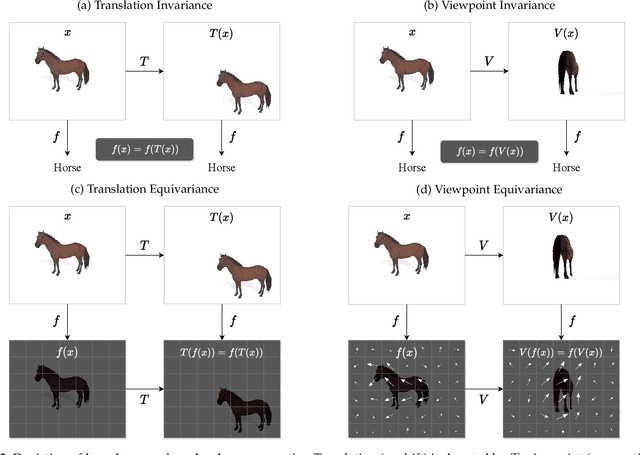
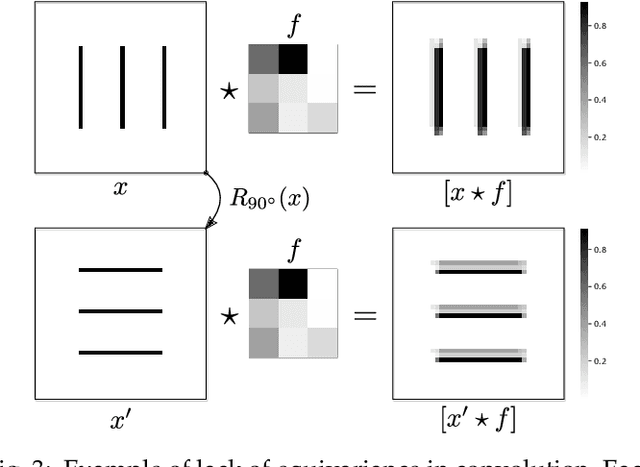
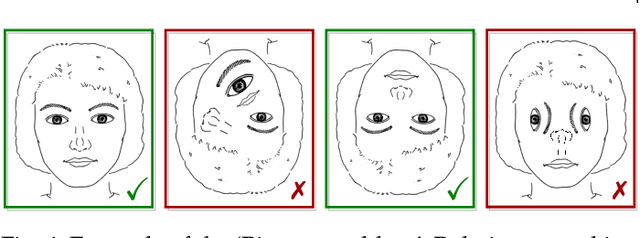
Capsule networks were proposed as an alternative approach to Convolutional Neural Networks (CNNs) for learning object-centric representations, which can be leveraged for improved generalization and sample complexity. Unlike CNNs, capsule networks are designed to explicitly model part-whole hierarchical relationships by using groups of neurons to encode visual entities, and learn the relationships between those entities. Promising early results achieved by capsule networks have motivated the deep learning community to continue trying to improve their performance and scalability across several application areas. However, a major hurdle for capsule network research has been the lack of a reliable point of reference for understanding their foundational ideas and motivations. The aim of this survey is to provide a comprehensive overview of the capsule network research landscape, which will serve as a valuable resource for the community going forward. To that end, we start with an introduction to the fundamental concepts and motivations behind capsule networks, such as equivariant inference in computer vision. We then cover the technical advances in the capsule routing mechanisms and the various formulations of capsule networks, e.g. generative and geometric. Additionally, we provide a detailed explanation of how capsule networks relate to the popular attention mechanism in Transformers, and highlight non-trivial conceptual similarities between them in the context of representation learning. Afterwards, we explore the extensive applications of capsule networks in computer vision, video and motion, graph representation learning, natural language processing, medical imaging and many others. To conclude, we provide an in-depth discussion regarding the main hurdles in capsule network research, and highlight promising research directions for future work.