 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeOCLR: Leveraging Original Images for Contrastive Learning of Visual Representations
Mar 11, 2024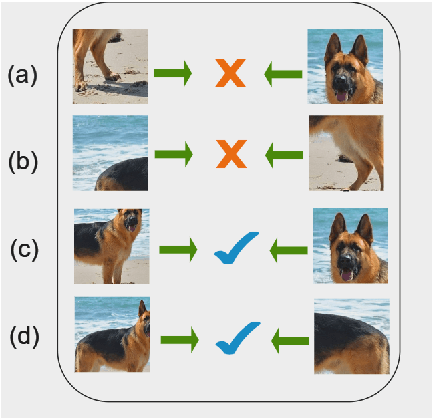
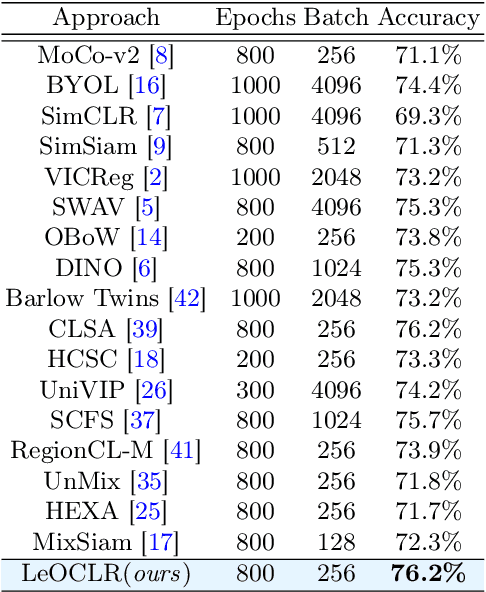
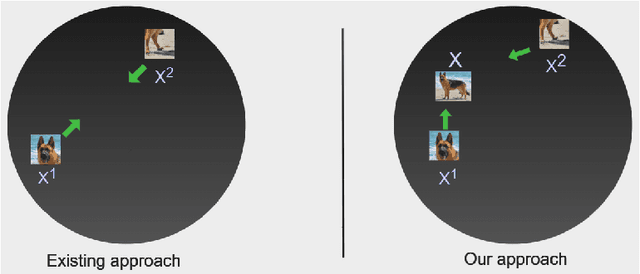
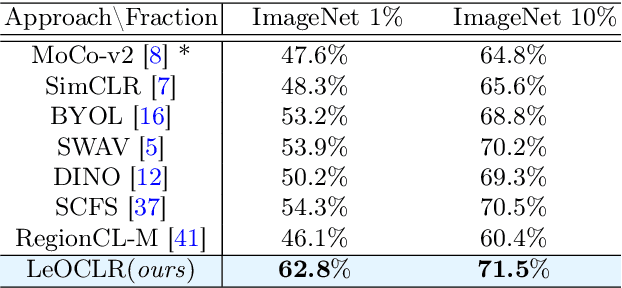
Contrastive instance discrimination outperforms supervised learning in downstream tasks like image classification and object detection. However, this approach heavily relies on data augmentation during representation learning, which may result in inferior results if not properly implemented. Random cropping followed by resizing is a common form of data augmentation used in contrastive learning, but it can lead to degraded representation learning if the two random crops contain distinct semantic content. To address this issue, this paper introduces LeOCLR (Leveraging Original Images for Contrastive Learning of Visual Representations), a framework that employs a new instance discrimination approach and an adapted loss function that ensures the shared region between positive pairs is semantically correct. The experimental results show that our approach consistently improves representation learning across different datasets compared to baseline models. For example, our approach outperforms MoCo-v2 by 5.1% on ImageNet-1K in linear evaluation and several other methods on transfer learning tasks.
Semantic Positive Pairs for Enhancing Contrastive Instance Discrimination
Jun 28, 2023Self-supervised learning algorithms based on instance discrimination effectively prevent representation collapse and produce promising results in representation learning. However, the process of attracting positive pairs (i.e., two views of the same instance) in the embedding space and repelling all other instances (i.e., negative pairs) irrespective of their categories could result in discarding important features. To address this issue, we propose an approach to identifying those images with similar semantic content and treating them as positive instances, named semantic positive pairs set (SPPS), thereby reducing the risk of discarding important features during representation learning. Our approach could work with any contrastive instance discrimination framework such as SimCLR or MOCO. We conduct experiments on three datasets: ImageNet, STL-10 and CIFAR-10 to evaluate our approach. The experimental results show that our approach consistently outperforms the baseline method vanilla SimCLR across all three datasets; for example, our approach improves upon vanilla SimCLR under linear evaluation protocol by 4.18% on ImageNet with a batch size 1024 and 800 epochs.