 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Mask Self-Supervised Learning for Physics-Guided Neural Networks in Highly Accelerated MRI
Aug 13, 2020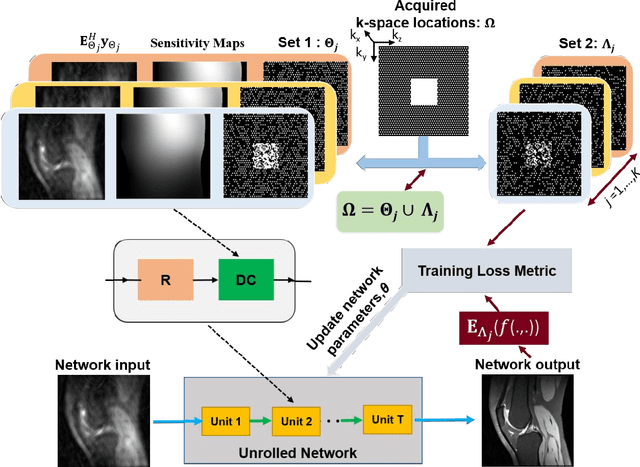
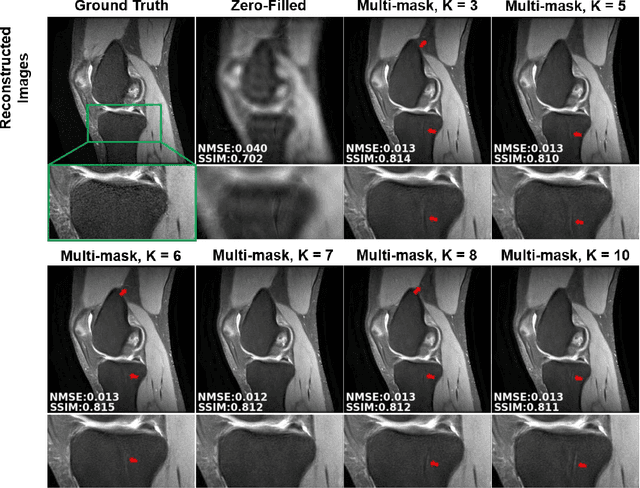
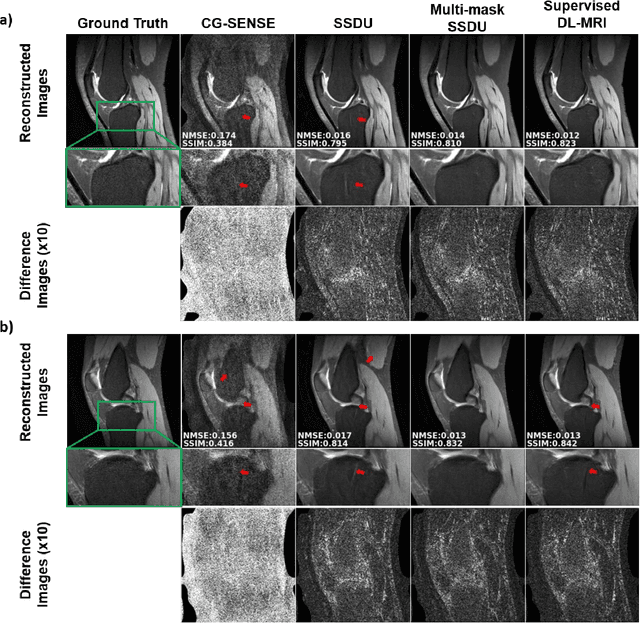
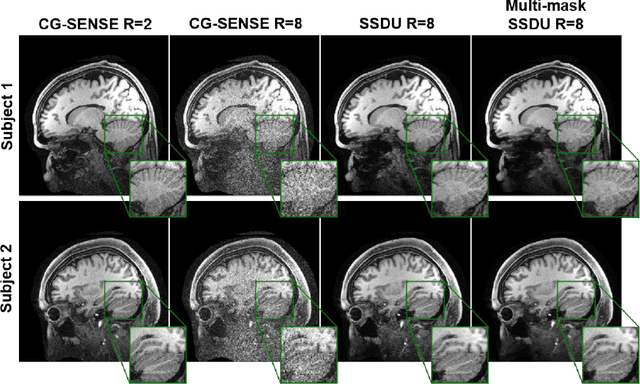
Purpose: To develop an improved self-supervised learning strategy that efficiently uses the acquired data for training a physics-guided reconstruction network without a database of fully-sampled data. Methods: Currently self-supervised learning for physics-guided reconstruction networks splits acquired undersampled data into two disjoint sets, where one is used for data consistency (DC) in the unrolled network and the other to define the training loss. The proposed multi-mask self-supervised learning via data undersampling (SSDU) splits acquired measurements into multiple pairs of disjoint sets for each training sample, while using one of these sets for DC units and the other for defining loss, thereby more efficiently using the undersampled data. Multi-mask SSDU is applied on fully-sampled 3D knee and prospectively undersampled 3D brain MRI datasets, which are retrospectively subsampled to acceleration rate (R)=8, and compared to CG-SENSE and single-mask SSDU DL-MRI, as well as supervised DL-MRI when fully-sampled data is available. Results: Results on knee MRI show that the proposed multi-mask SSDU outperforms SSDU and performs closely with supervised DL-MRI, while significantly outperforming CG-SENSE. A clinical reader study further ranks the multi-mask SSDU higher than supervised DL-MRI in terms of SNR and aliasing artifacts. Results on brain MRI show that multi-mask SSDU achieves better reconstruction quality compared to SSDU and CG-SENSE. Reader study demonstrates that multi-mask SSDU at R=8 significantly improves reconstruction compared to single-mask SSDU at R=8, as well as CG-SENSE at R=2. Conclusion: The proposed multi-mask SSDU approach enables improved training of physics-guided neural networks without fully-sampled data, by enabling efficient use of the undersampled data with multiple masks.
The International Workshop on Osteoarthritis Imaging Knee MRI Segmentation Challenge: A Multi-Institute Evaluation and Analysis Framework on a Standardized Dataset
May 26, 2020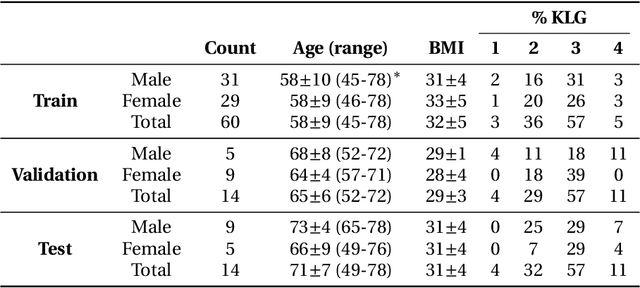
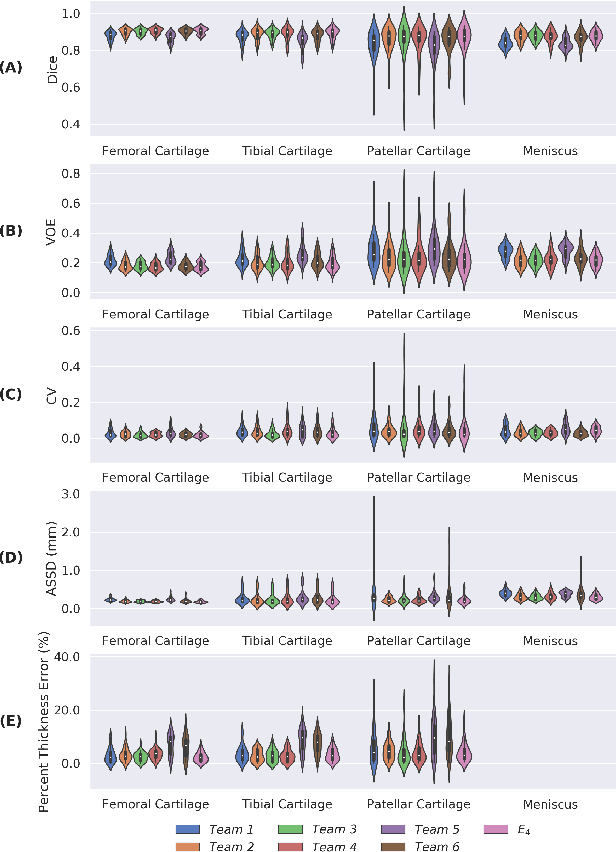
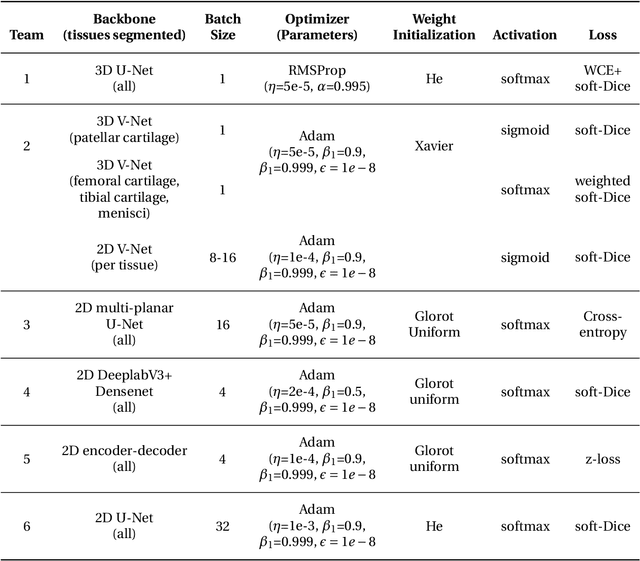
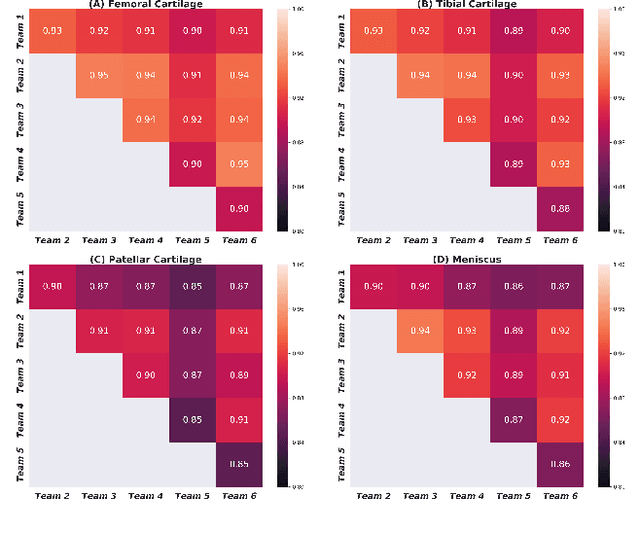
Purpose: To organize a knee MRI segmentation challenge for characterizing the semantic and clinical efficacy of automatic segmentation methods relevant for monitoring osteoarthritis progression. Methods: A dataset partition consisting of 3D knee MRI from 88 subjects at two timepoints with ground-truth articular (femoral, tibial, patellar) cartilage and meniscus segmentations was standardized. Challenge submissions and a majority-vote ensemble were evaluated using Dice score, average symmetric surface distance, volumetric overlap error, and coefficient of variation on a hold-out test set. Similarities in network segmentations were evaluated using pairwise Dice correlations. Articular cartilage thickness was computed per-scan and longitudinally. Correlation between thickness error and segmentation metrics was measured using Pearson's coefficient. Two empirical upper bounds for ensemble performance were computed using combinations of model outputs that consolidated true positives and true negatives. Results: Six teams (T1-T6) submitted entries for the challenge. No significant differences were observed across all segmentation metrics for all tissues (p=1.0) among the four top-performing networks (T2, T3, T4, T6). Dice correlations between network pairs were high (>0.85). Per-scan thickness errors were negligible among T1-T4 (p=0.99) and longitudinal changes showed minimal bias (<0.03mm). Low correlations (<0.41) were observed between segmentation metrics and thickness error. The majority-vote ensemble was comparable to top performing networks (p=1.0). Empirical upper bound performances were similar for both combinations (p=1.0). Conclusion: Diverse networks learned to segment the knee similarly where high segmentation accuracy did not correlate to cartilage thickness accuracy. Voting ensembles did not outperform individual networks but may help regularize individual models.
Self-Supervised Learning of Physics-Based Reconstruction Neural Networks without Fully-Sampled Reference Data
Dec 16, 2019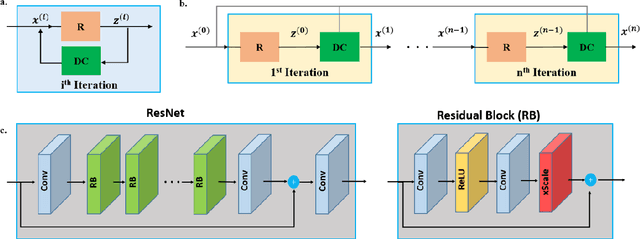
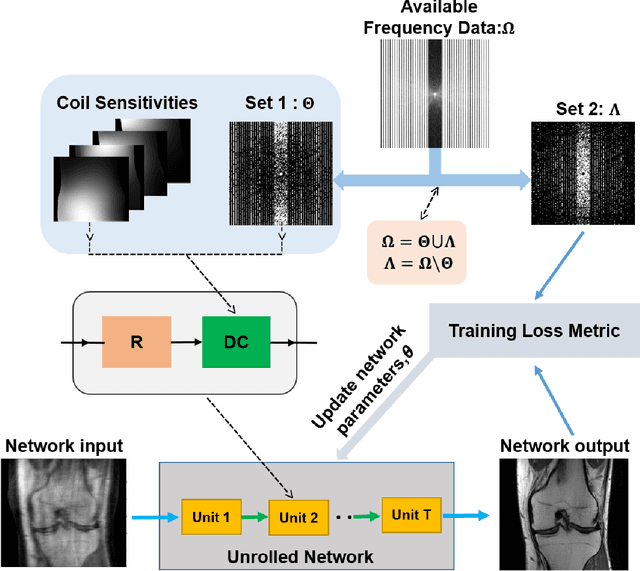
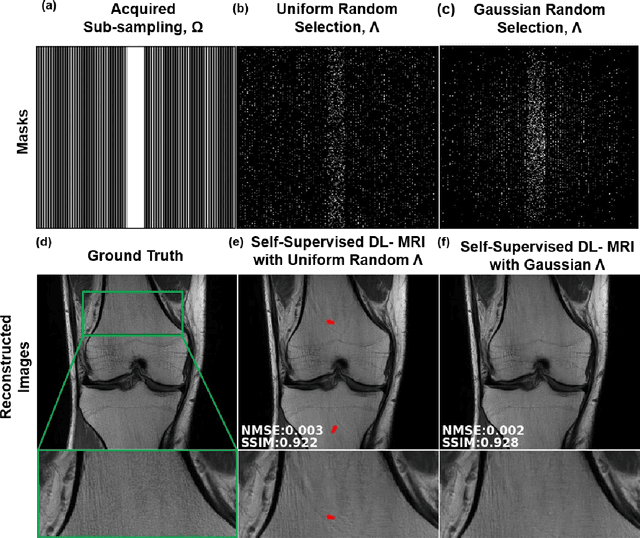
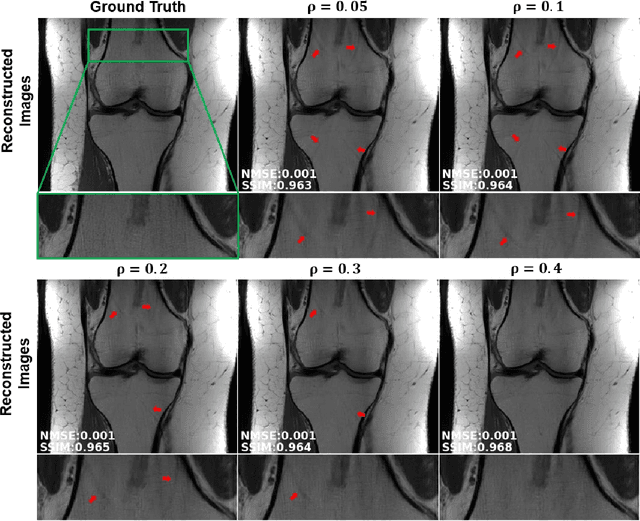
Purpose: To develop a strategy for training a physics-driven MRI reconstruction neural network without a database of fully-sampled datasets. Theory and Methods: Self-supervised learning via data under-sampling (SSDU) for physics-based deep learning (DL) reconstruction partitions available measurements into two sets, one of which is used in the data consistency units in the unrolled network and the other is used to define the loss for training. The proposed training without fully-sampled data is compared to fully-supervised training with ground-truth data, as well as conventional compressed sensing and parallel imaging methods using the publicly available fastMRI knee database. The same physics-based neural network is used for both proposed SSDU and supervised training. The SSDU training is also applied to prospectively 2-fold accelerated high-resolution brain datasets at different acceleration rates, and compared to parallel imaging. Results: Results on five different knee sequences at acceleration rate of 4 shows that proposed self-supervised approach performs closely with supervised learning, while significantly outperforming conventional compressed sensing and parallel imaging, as characterized by quantitative metrics and a clinical reader study. The results on prospectively sub-sampled brain datasets, where supervised learning cannot be employed due to lack of ground-truth reference, show that the proposed self-supervised approach successfully perform reconstruction at high acceleration rates (4, 6 and 8). Image readings indicate improved visual reconstruction quality with the proposed approach compared to parallel imaging at acquisition acceleration. Conclusion: The proposed SSDU approach allows training of physics-based DL-MRI reconstruction without fully-sampled data, while achieving comparable results with supervised DL-MRI trained on fully-sampled data.
Self-Supervised Physics-Based Deep Learning MRI Reconstruction Without Fully-Sampled Data
Oct 21, 2019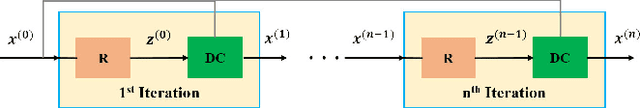
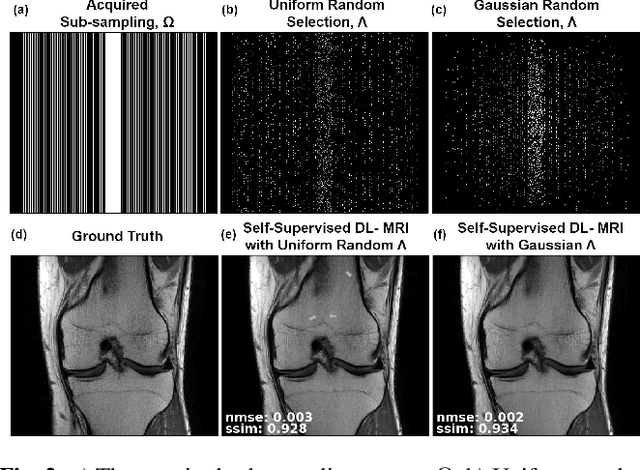
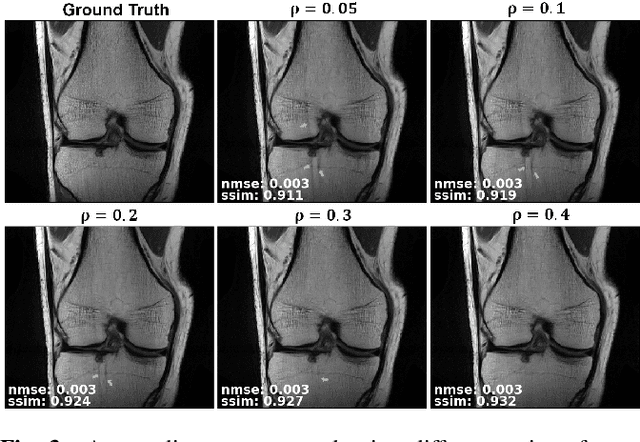
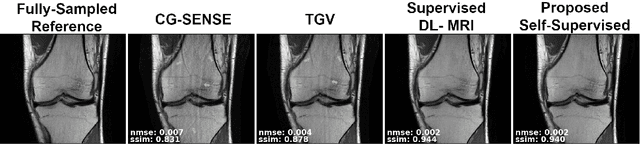
Deep learning (DL) has emerged as a tool for improving accelerated MRI reconstruction. A common strategy among DL methods is the physics-based approach, where a regularized iterative algorithm alternating between data consistency and a regularizer is unrolled for a finite number of iterations. This unrolled network is then trained end-to-end in a supervised manner, using fully-sampled data as ground truth for the network output. However, in a number of scenarios, it is difficult to obtain fully-sampled datasets, due to physiological constraints such as organ motion or physical constraints such as signal decay. In this work, we tackle this issue and propose a self-supervised learning strategy that enables physics-based DL reconstruction without fully-sampled data. Our approach is to divide the acquired sub-sampled points for each scan into training and validation subsets. During training, data consistency is enforced over the training subset, while the validation subset is used to define the loss function. Results show that the proposed self-supervised learning method successfully reconstructs images without fully-sampled data, performing similarly to the supervised approach that is trained with fully-sampled references. This has implications for physics-based inverse problem approaches for other settings, where fully-sampled data is not available or possible to acquire.