 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge20-fold Accelerated 7T fMRI Using Referenceless Self-Supervised Deep Learning Reconstruction
May 12, 2021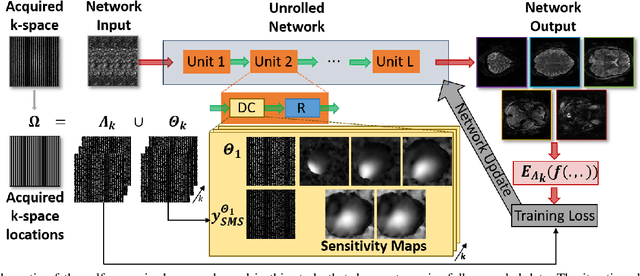
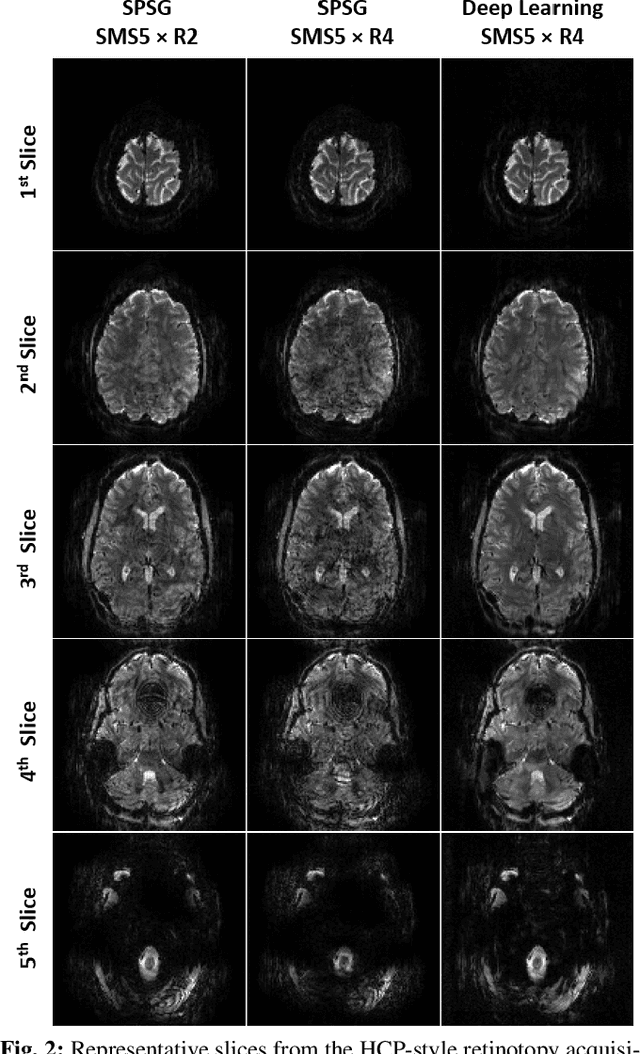
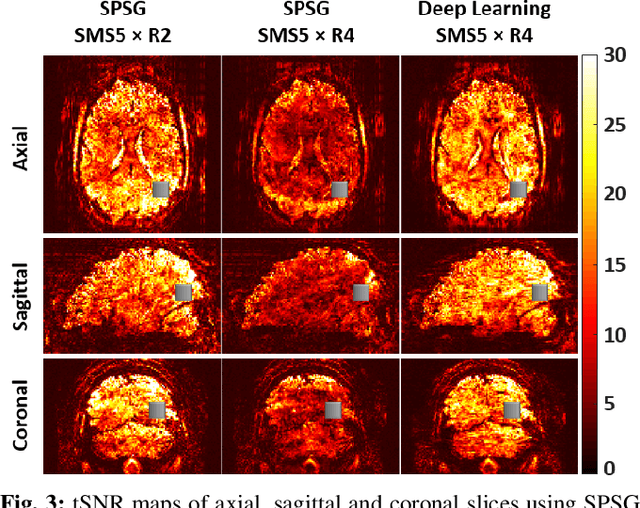
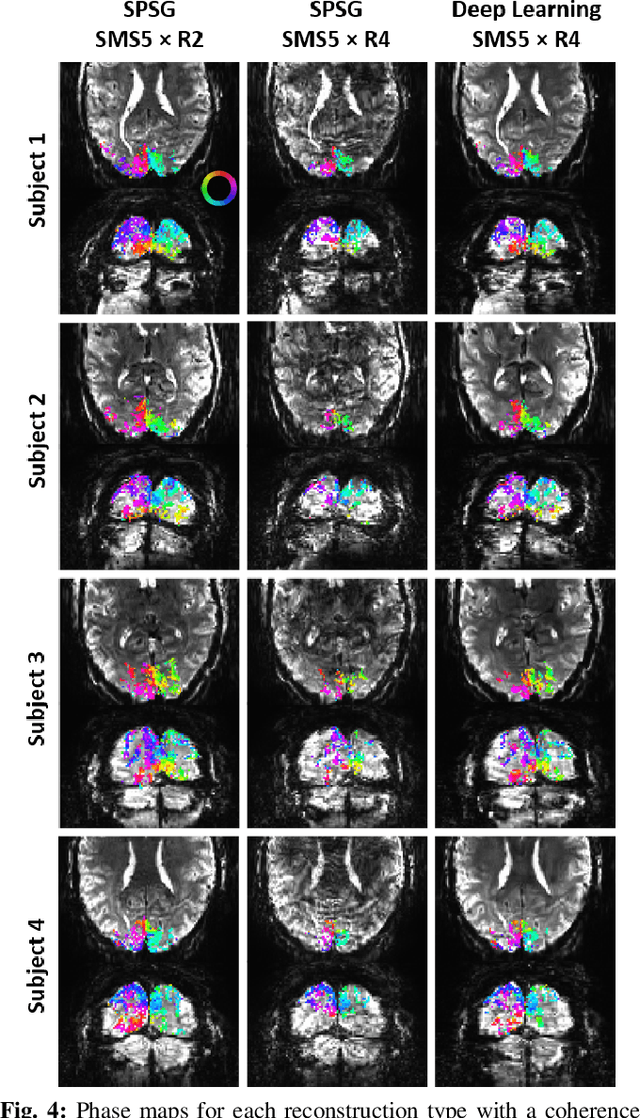
High spatial and temporal resolution across the whole brain is essential to accurately resolve neural activities in fMRI. Therefore, accelerated imaging techniques target improved coverage with high spatio-temporal resolution. Simultaneous multi-slice (SMS) imaging combined with in-plane acceleration are used in large studies that involve ultrahigh field fMRI, such as the Human Connectome Project. However, for even higher acceleration rates, these methods cannot be reliably utilized due to aliasing and noise artifacts. Deep learning (DL) reconstruction techniques have recently gained substantial interest for improving highly-accelerated MRI. Supervised learning of DL reconstructions generally requires fully-sampled training datasets, which is not available for high-resolution fMRI studies. To tackle this challenge, self-supervised learning has been proposed for training of DL reconstruction with only undersampled datasets, showing similar performance to supervised learning. In this study, we utilize a self-supervised physics-guided DL reconstruction on a 5-fold SMS and 4-fold in-plane accelerated 7T fMRI data. Our results show that our self-supervised DL reconstruction produce high-quality images at this 20-fold acceleration, substantially improving on existing methods, while showing similar functional precision and temporal effects in the subsequent analysis compared to a standard 10-fold accelerated acquisition.
Improved Simultaneous Multi-Slice Functional MRI Using Self-supervised Deep Learning
May 10, 2021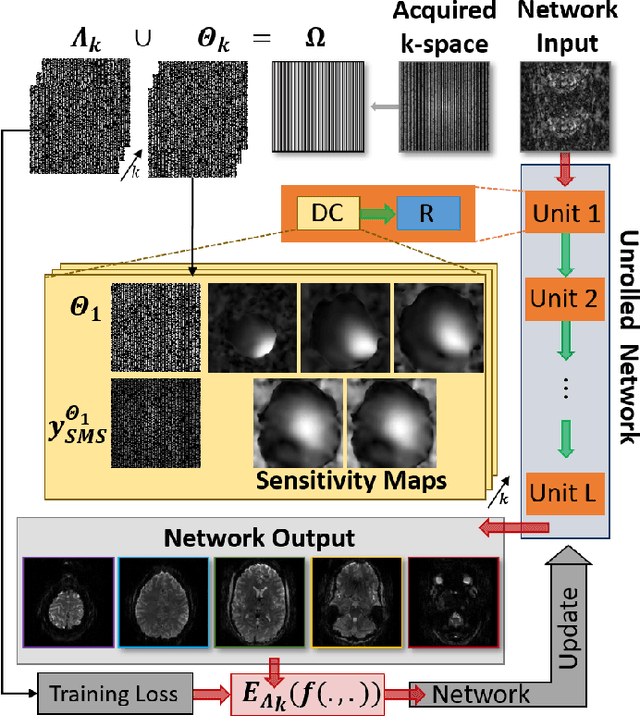
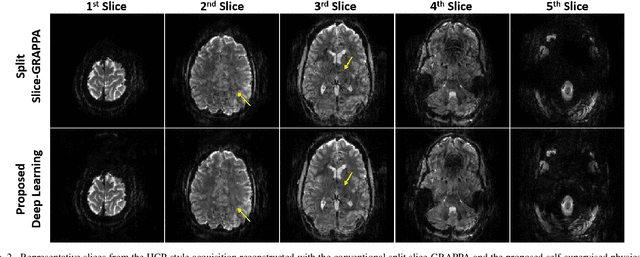
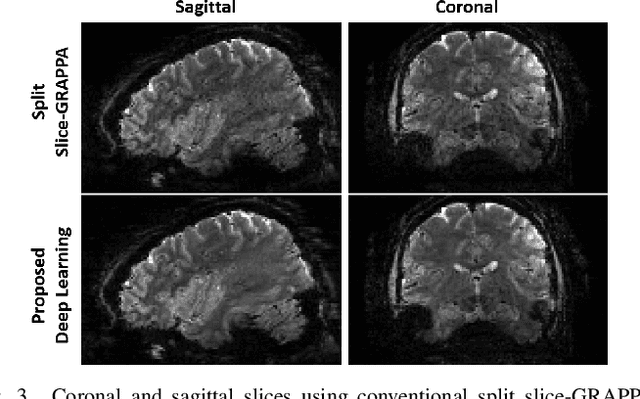
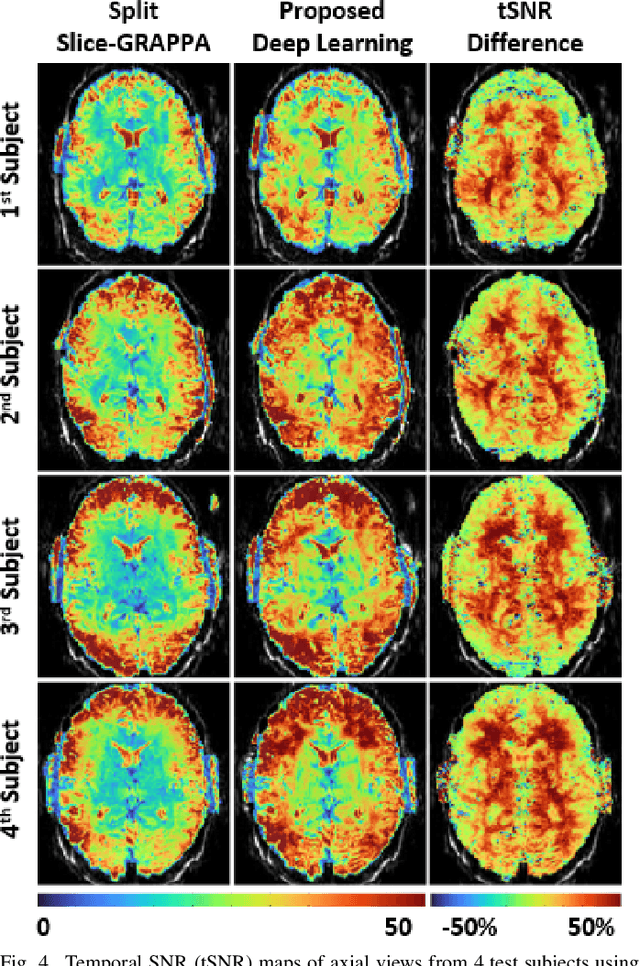
Functional MRI (fMRI) is commonly used for interpreting neural activities across the brain. Numerous accelerated fMRI techniques aim to provide improved spatiotemporal resolutions. Among these, simultaneous multi-slice (SMS) imaging has emerged as a powerful strategy, becoming a part of large-scale studies, such as the Human Connectome Project. However, when SMS imaging is combined with in-plane acceleration for higher acceleration rates, conventional SMS reconstruction methods may suffer from noise amplification and other artifacts. Recently, deep learning (DL) techniques have gained interest for improving MRI reconstruction. However, these methods are typically trained in a supervised manner that necessitates fully-sampled reference data, which is not feasible in highly-accelerated fMRI acquisitions. Self-supervised learning that does not require fully-sampled data has recently been proposed and has shown similar performance to supervised learning. However, it has only been applied for in-plane acceleration. Furthermore the effect of DL reconstruction on subsequent fMRI analysis remains unclear. In this work, we extend self-supervised DL reconstruction to SMS imaging. Our results on prospectively 10-fold accelerated 7T fMRI data show that self-supervised DL reduces reconstruction noise and suppresses residual artifacts. Subsequent fMRI analysis remains unaltered by DL processing, while the improved temporal signal-to-noise ratio produces higher coherence estimates between task runs.
Multi-Mask Self-Supervised Learning for Physics-Guided Neural Networks in Highly Accelerated MRI
Aug 13, 2020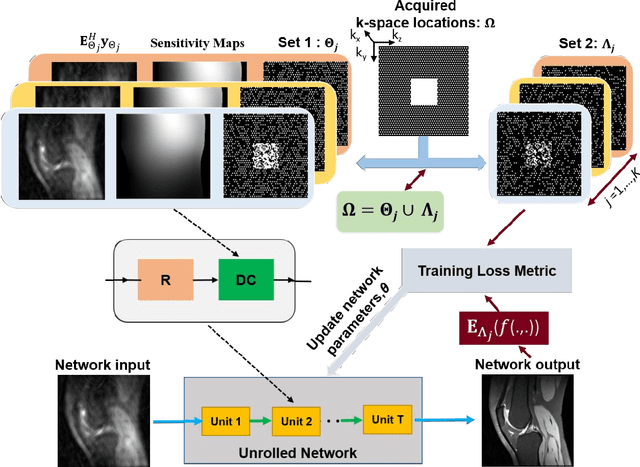
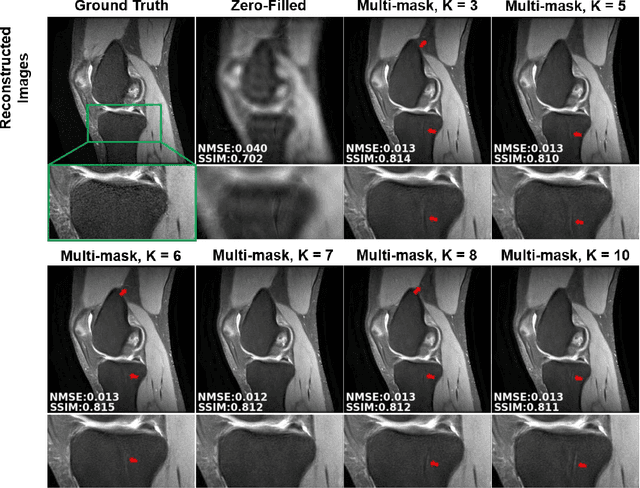
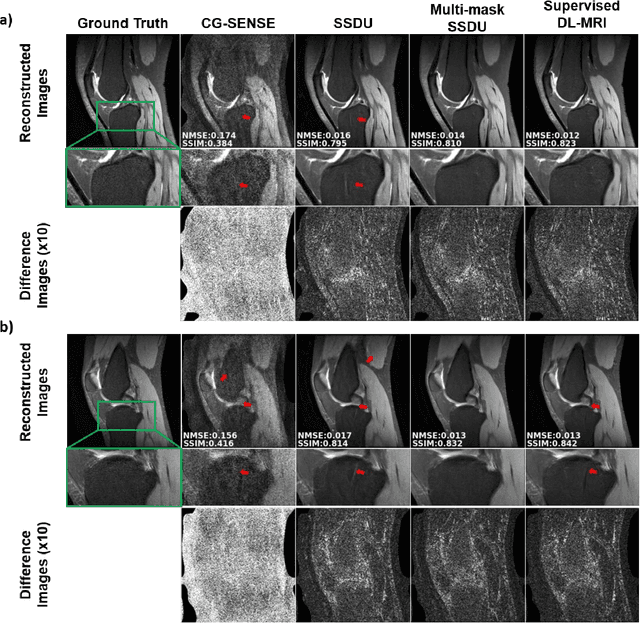
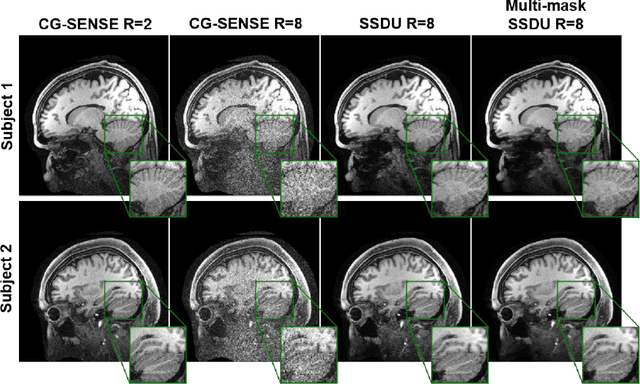
Purpose: To develop an improved self-supervised learning strategy that efficiently uses the acquired data for training a physics-guided reconstruction network without a database of fully-sampled data. Methods: Currently self-supervised learning for physics-guided reconstruction networks splits acquired undersampled data into two disjoint sets, where one is used for data consistency (DC) in the unrolled network and the other to define the training loss. The proposed multi-mask self-supervised learning via data undersampling (SSDU) splits acquired measurements into multiple pairs of disjoint sets for each training sample, while using one of these sets for DC units and the other for defining loss, thereby more efficiently using the undersampled data. Multi-mask SSDU is applied on fully-sampled 3D knee and prospectively undersampled 3D brain MRI datasets, which are retrospectively subsampled to acceleration rate (R)=8, and compared to CG-SENSE and single-mask SSDU DL-MRI, as well as supervised DL-MRI when fully-sampled data is available. Results: Results on knee MRI show that the proposed multi-mask SSDU outperforms SSDU and performs closely with supervised DL-MRI, while significantly outperforming CG-SENSE. A clinical reader study further ranks the multi-mask SSDU higher than supervised DL-MRI in terms of SNR and aliasing artifacts. Results on brain MRI show that multi-mask SSDU achieves better reconstruction quality compared to SSDU and CG-SENSE. Reader study demonstrates that multi-mask SSDU at R=8 significantly improves reconstruction compared to single-mask SSDU at R=8, as well as CG-SENSE at R=2. Conclusion: The proposed multi-mask SSDU approach enables improved training of physics-guided neural networks without fully-sampled data, by enabling efficient use of the undersampled data with multiple masks.
Self-Supervised Learning of Physics-Based Reconstruction Neural Networks without Fully-Sampled Reference Data
Dec 16, 2019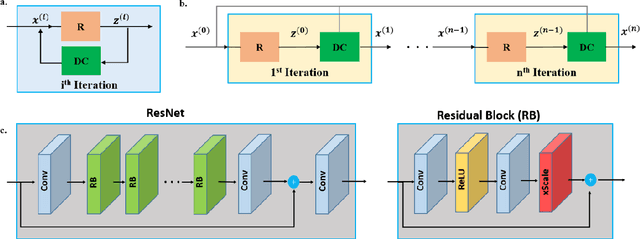
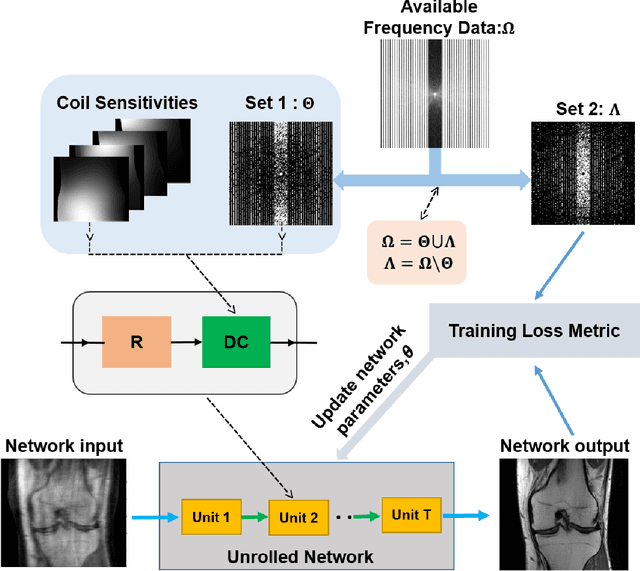
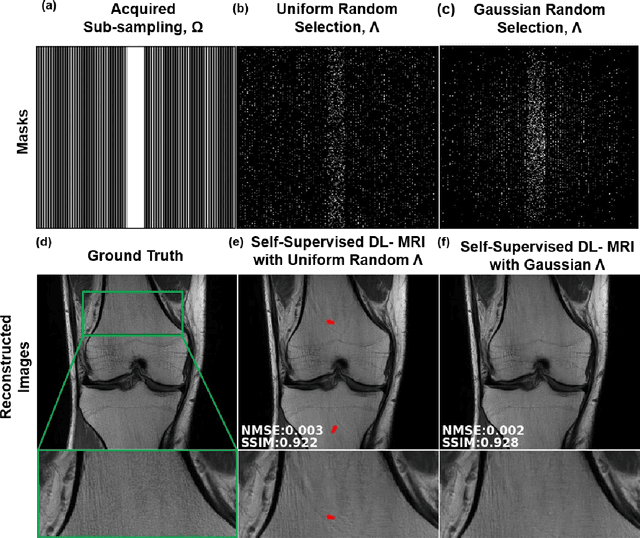
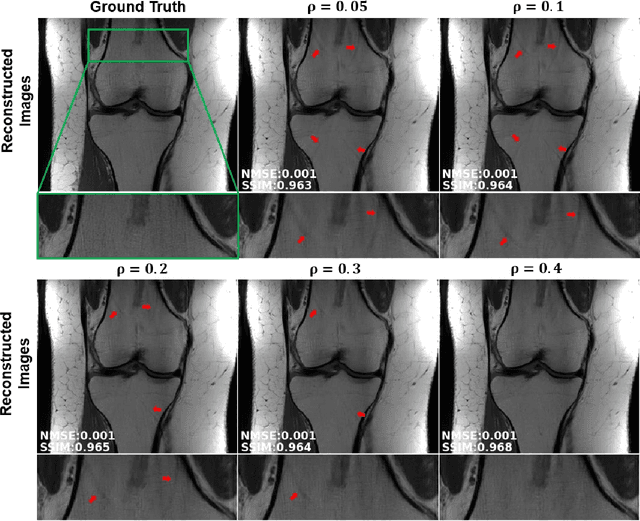
Purpose: To develop a strategy for training a physics-driven MRI reconstruction neural network without a database of fully-sampled datasets. Theory and Methods: Self-supervised learning via data under-sampling (SSDU) for physics-based deep learning (DL) reconstruction partitions available measurements into two sets, one of which is used in the data consistency units in the unrolled network and the other is used to define the loss for training. The proposed training without fully-sampled data is compared to fully-supervised training with ground-truth data, as well as conventional compressed sensing and parallel imaging methods using the publicly available fastMRI knee database. The same physics-based neural network is used for both proposed SSDU and supervised training. The SSDU training is also applied to prospectively 2-fold accelerated high-resolution brain datasets at different acceleration rates, and compared to parallel imaging. Results: Results on five different knee sequences at acceleration rate of 4 shows that proposed self-supervised approach performs closely with supervised learning, while significantly outperforming conventional compressed sensing and parallel imaging, as characterized by quantitative metrics and a clinical reader study. The results on prospectively sub-sampled brain datasets, where supervised learning cannot be employed due to lack of ground-truth reference, show that the proposed self-supervised approach successfully perform reconstruction at high acceleration rates (4, 6 and 8). Image readings indicate improved visual reconstruction quality with the proposed approach compared to parallel imaging at acquisition acceleration. Conclusion: The proposed SSDU approach allows training of physics-based DL-MRI reconstruction without fully-sampled data, while achieving comparable results with supervised DL-MRI trained on fully-sampled data.