 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised speech representation learning for keyword-spotting with light-weight transformers
Paper and Code
Mar 07, 2023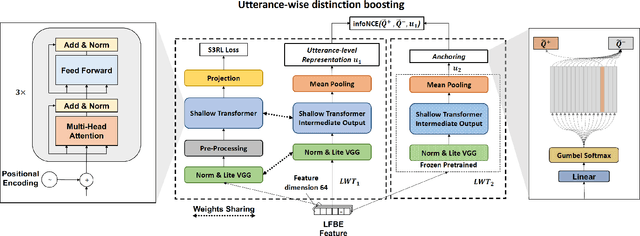
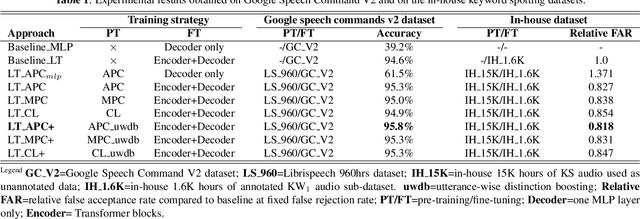
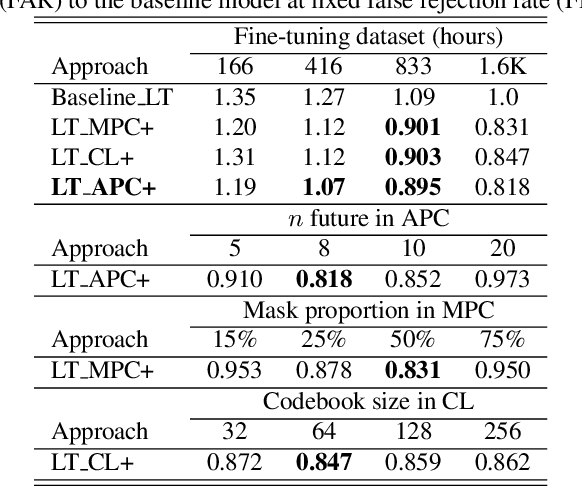
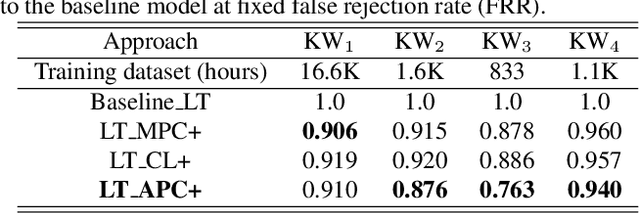
Self-supervised speech representation learning (S3RL) is revolutionizing the way we leverage the ever-growing availability of data. While S3RL related studies typically use large models, we employ light-weight networks to comply with tight memory of compute-constrained devices. We demonstrate the effectiveness of S3RL on a keyword-spotting (KS) problem by using transformers with 330k parameters and propose a mechanism to enhance utterance-wise distinction, which proves crucial for improving performance on classification tasks. On the Google speech commands v2 dataset, the proposed method applied to the Auto-Regressive Predictive Coding S3RL led to a 1.2% accuracy improvement compared to training from scratch. On an in-house KS dataset with four different keywords, it provided 6% to 23.7% relative false accept improvement at fixed false reject rate. We argue this demonstrates the applicability of S3RL approaches to light-weight models for KS and confirms S3RL is a powerful alternative to traditional supervised learning for resource-constrained applications.