 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Data-efficient Modeling for Wake Word Spotting
Paper and Code
Oct 13, 2020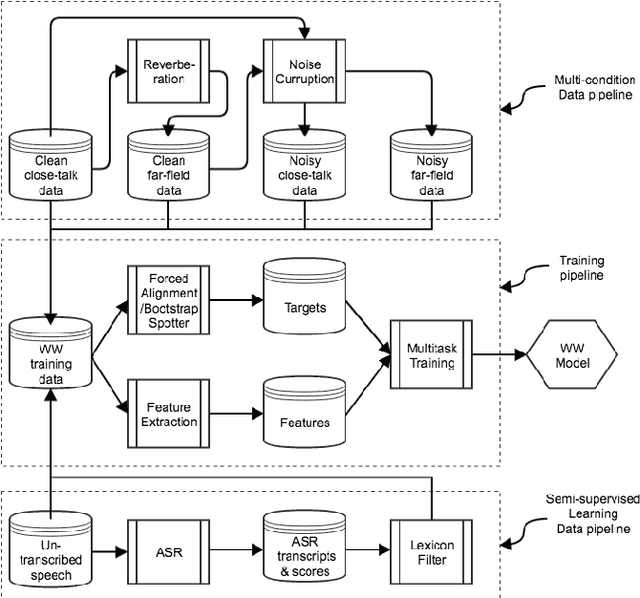
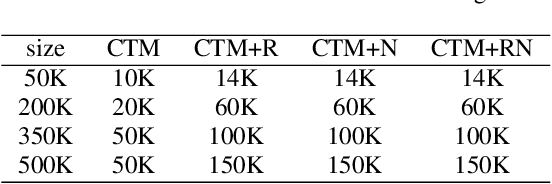
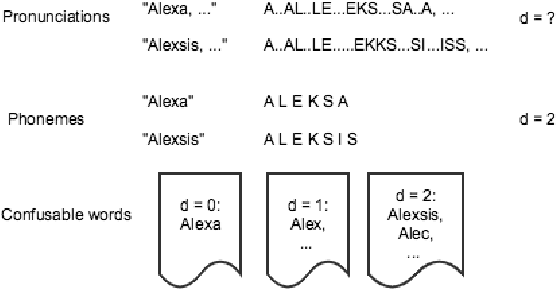

Wake word (WW) spotting is challenging in far-field not only because of the interference in signal transmission but also the complexity in acoustic environments. Traditional WW model training requires large amount of in-domain WW-specific data with substantial human annotations therefore it is hard to build WW models without such data. In this paper we present data-efficient solutions to address the challenges in WW modeling, such as domain-mismatch, noisy conditions, limited annotation, etc. Our proposed system is composed of a multi-condition training pipeline with a stratified data augmentation, which improves the model robustness to a variety of predefined acoustic conditions, together with a semi-supervised learning pipeline to accurately extract the WW and confusable examples from untranscribed speech corpus. Starting from only 10 hours of domain-mismatched WW audio, we are able to enlarge and enrich the training dataset by 20-100 times to capture the acoustic complexity. Our experiments on real user data show that the proposed solutions can achieve comparable performance of a production-grade model by saving 97\% of the amount of WW-specific data collection and 86\% of the bandwidth for annotation.