 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-Best Hypotheses Reranking for Text-To-SQL Systems
Paper and Code



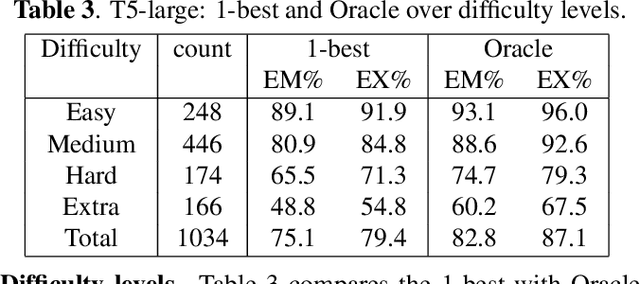
Text-to-SQL task maps natural language utterances to structured queries that can be issued to a database. State-of-the-art (SOTA) systems rely on finetuning large, pre-trained language models in conjunction with constrained decoding applying a SQL parser. On the well established Spider dataset, we begin with Oracle studies: specifically, choosing an Oracle hypothesis from a SOTA model's 10-best list, yields a $7.7\%$ absolute improvement in both exact match (EM) and execution (EX) accuracy, showing significant potential improvements with reranking. Identifying coherence and correctness as reranking approaches, we design a model generating a query plan and propose a heuristic schema linking algorithm. Combining both approaches, with T5-Large, we obtain a consistent $1\% $ improvement in EM accuracy, and a $~2.5\%$ improvement in EX, establishing a new SOTA for this task. Our comprehensive error studies on DEV data show the underlying difficulty in making progress on this task.