 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Deep Learning Research with Kubernetes on the NRP Nautilus HyperCluster
Nov 18, 2024



Throughout the scientific computing space, deep learning algorithms have shown excellent performance in a wide range of applications. As these deep neural networks (DNNs) continue to mature, the necessary compute required to train them has continued to grow. Today, modern DNNs require millions of FLOPs and days to weeks of training to generate a well-trained model. The training times required for DNNs are oftentimes a bottleneck in DNN research for a variety of deep learning applications, and as such, accelerating and scaling DNN training enables more robust and accelerated research. To that end, in this work, we explore utilizing the NRP Nautilus HyperCluster to automate and scale deep learning model training for three separate applications of DNNs, including overhead object detection, burned area segmentation, and deforestation detection. In total, 234 deep neural models are trained on Nautilus, for a total time of 4,040 hours
Broad Area Search and Detection of Surface-to-Air Missile Sites Using Spatial Fusion of Component Object Detections from Deep Neural Networks
Mar 23, 2020

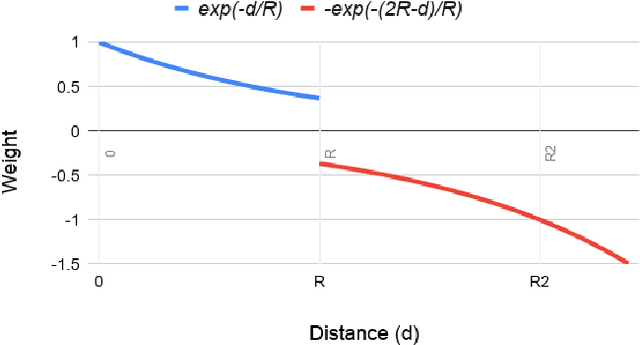
Here we demonstrate how Deep Neural Network (DNN) detections of multiple constitutive or component objects that are part of a larger, more complex, and encompassing feature can be spatially fused to improve the search, detection, and retrieval (ranking) of the larger complex feature. First, scores computed from a spatial clustering algorithm are normalized to a reference space so that they are independent of image resolution and DNN input chip size. Then, multi-scale DNN detections from various component objects are fused to improve the detection and retrieval of DNN detections of a larger complex feature. We demonstrate the utility of this approach for broad area search and detection of Surface-to-Air Missile (SAM) sites that have a very low occurrence rate (only 16 sites) over a ~90,000 km^2 study area in SE China. The results demonstrate that spatial fusion of multi-scale component-object DNN detections can reduce the detection error rate of SAM Sites by $>$85% while still maintaining a 100% recall. The novel spatial fusion approach demonstrated here can be easily extended to a wide variety of other challenging object search and detection problems in large-scale remote sensing image datasets.
Recognizing Image Objects by Relational Analysis Using Heterogeneous Superpixels and Deep Convolutional Features
Aug 02, 2019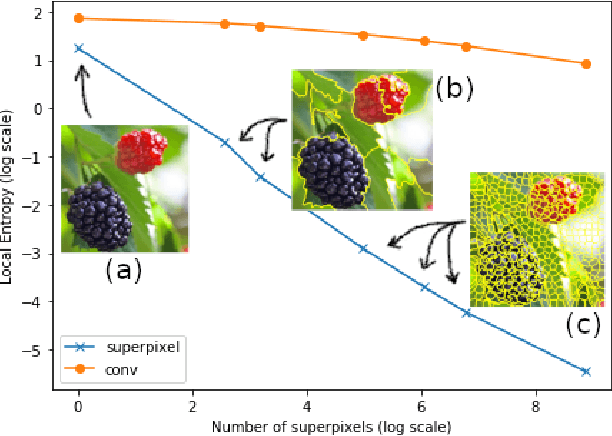



Superpixel-based methodologies have become increasingly popular in computer vision, especially when the computation is too expensive in time or memory to perform with a large number of pixels or features. However, rarely is superpixel segmentation examined within the context of deep convolutional neural network architectures. This paper presents a novel neural architecture that exploits the superpixel feature space. The visual feature space is organized using superpixels to provide the neural network with a substructure of the images. As the superpixels associate the visual feature space with parts of the objects in an image, the visual feature space is transformed into a structured vector representation per superpixel. It is shown that it is feasible to learn superpixel features using capsules and it is potentially beneficial to perform image analysis in such a structured manner. This novel deep learning architecture is examined in the context of an image classification task, highlighting explicit interpretability (explainability) of the network's decision making. The results are compared against a baseline deep neural model, as well as among superpixel capsule networks with a variety of hyperparameter settings.