 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
Evaluating the Impact of Underwater Image Enhancement on Object Detection Performance: A Comprehensive Study
Nov 26, 2024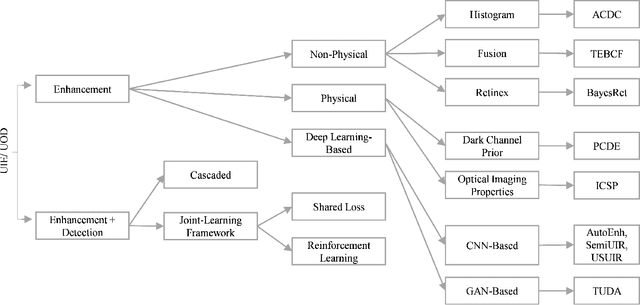
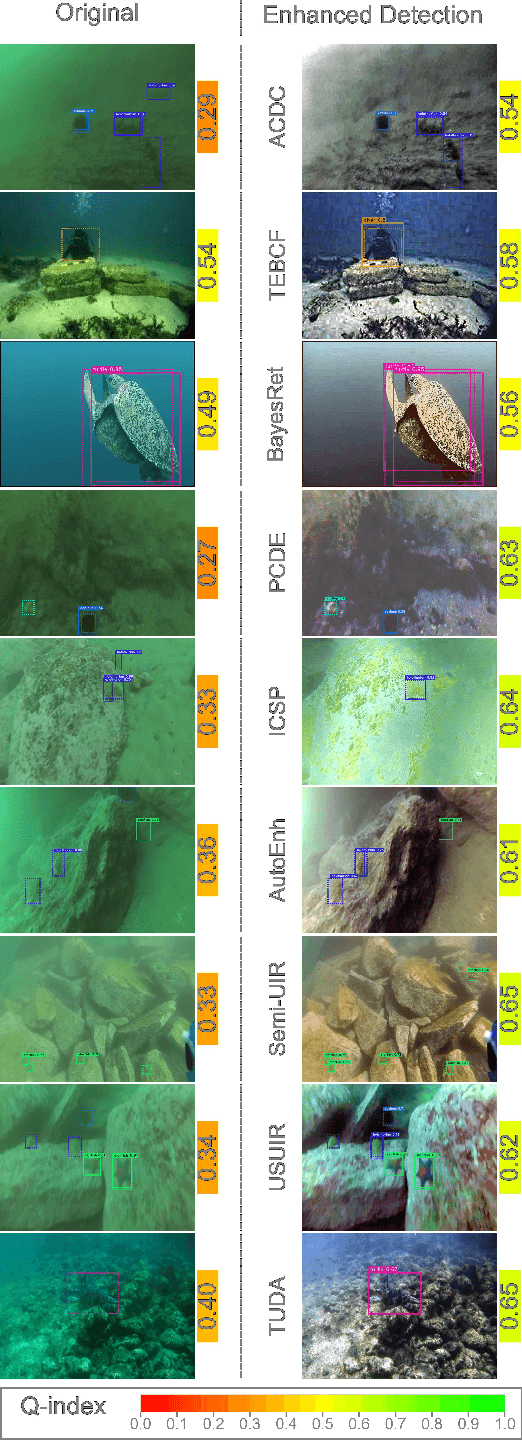

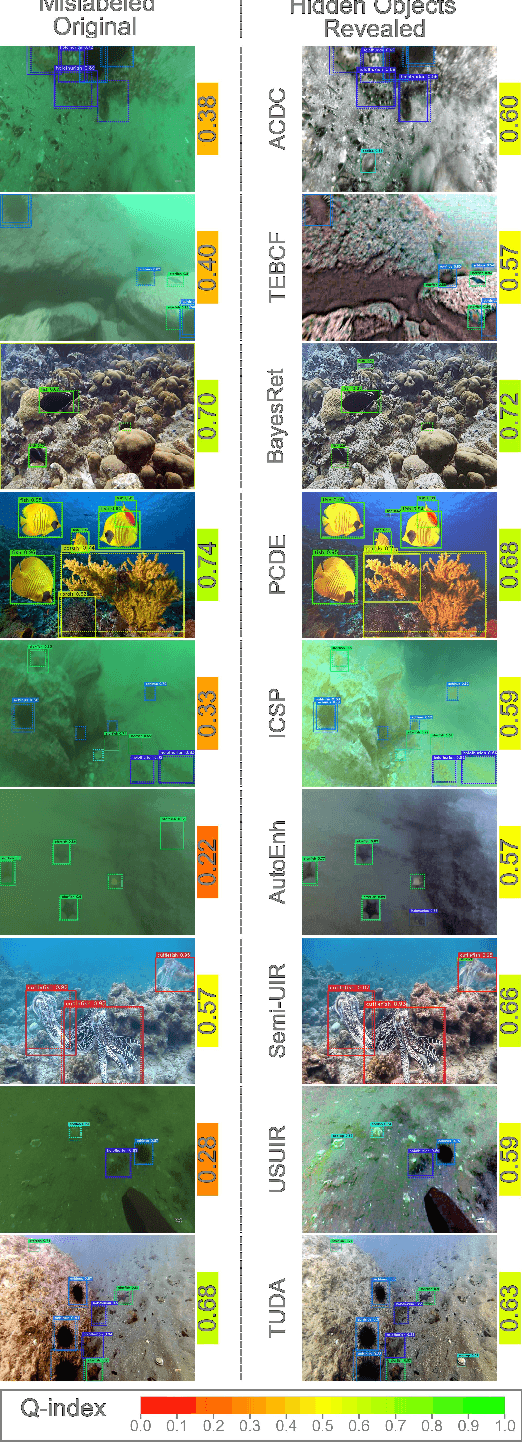
Underwater imagery often suffers from severe degradation that results in low visual quality and object detection performance. This work aims to evaluate state-of-the-art image enhancement models, investigate their impact on underwater object detection, and explore their potential to improve detection performance. To this end, we selected representative underwater image enhancement models covering major enhancement categories and applied them separately to two recent datasets: 1) the Real-World Underwater Object Detection Dataset (RUOD), and 2) the Challenging Underwater Plant Detection Dataset (CUPDD). Following this, we conducted qualitative and quantitative analyses on the enhanced images and developed a quality index (Q-index) to compare the quality distribution of the original and enhanced images. Subsequently, we compared the performance of several YOLO-NAS detection models that are separately trained and tested on the original and enhanced image sets. Then, we performed a correlation study to examine the relationship between enhancement metrics and detection performance. We also analyzed the inference results from the trained detectors presenting cases where enhancement increased the detection performance as well as cases where enhancement revealed missed objects by human annotators. This study suggests that although enhancement generally deteriorates the detection performance, it can still be harnessed in some cases for increased detection performance and more accurate human annotation.
Extra Global Attention Designation Using Keyword Detection in Sparse Transformer Architectures
Oct 11, 2024In this paper, we propose an extension to Longformer Encoder-Decoder, a popular sparse transformer architecture. One common challenge with sparse transformers is that they can struggle with encoding of long range context, such as connections between topics discussed at a beginning and end of a document. A method to selectively increase global attention is proposed and demonstrated for abstractive summarization tasks on several benchmark data sets. By prefixing the transcript with additional keywords and encoding global attention on these keywords, improvement in zero-shot, few-shot, and fine-tuned cases is demonstrated for some benchmark data sets.
Exploring the Readiness of Prominent Small Language Models for the Democratization of Financial Literacy
Oct 09, 2024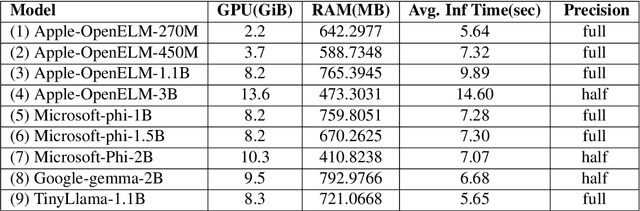
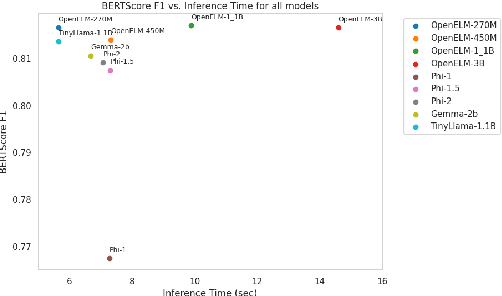

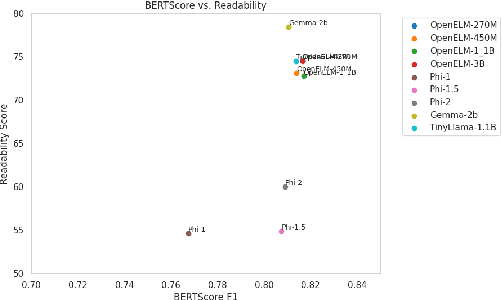
The use of small language models (SLMs), herein defined as models with less than three billion parameters, is increasing across various domains and applications. Due to their ability to run on more accessible hardware and preserve user privacy, SLMs possess the potential to democratize access to language models for individuals of different socioeconomic status and with different privacy preferences. This study assesses several state-of-the-art SLMs (e.g., Apple's OpenELM, Microsoft's Phi, Google's Gemma, and the Tinyllama project) for use in the financial domain to support the development of financial literacy LMs. Democratizing access to quality financial information for those who are financially under educated is greatly needed in society, particularly as new financial markets and products emerge and participation in financial markets increases due to ease of access. We are the first to examine the use of open-source SLMs to democratize access to financial question answering capabilities for individuals and students. To this end, we provide an analysis of the memory usage, inference time, similarity comparisons to ground-truth answers, and output readability of prominent SLMs to determine which models are most accessible and capable of supporting access to financial information. We analyze zero-shot and few-shot learning variants of the models. The results suggest that some off-the-shelf SLMs merit further exploration and fine-tuning to prepare them for individual use, while others may have limits to their democratization.
For those who don't know to ask: Building a dataset of technology questions for digital newcomers
Mar 26, 2024While the rise of large language models (LLMs) has created rich new opportunities to learn about digital technology, many on the margins of this technology struggle to gain and maintain competency due to lexical or conceptual barriers that prevent them from asking appropriate questions. Although there have been many efforts to understand factuality of LLM-created content and ability of LLMs to answer questions, it is not well understood how unclear or nonstandard language queries affect the model outputs. We propose the creation of a dataset that captures questions of digital newcomers and outsiders, utilizing data we have compiled from a decade's worth of one-on-one tutoring. In this paper we lay out our planned efforts and some potential uses of this dataset.