 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Kernel Clustering: Approximate Kernel k-means
Paper and Code
Feb 16, 2014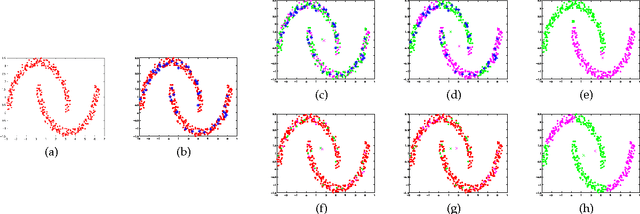
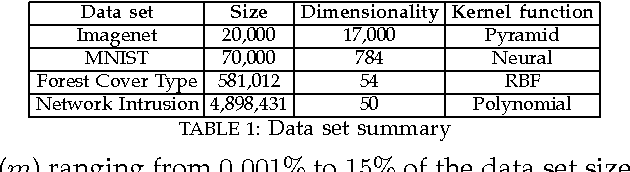
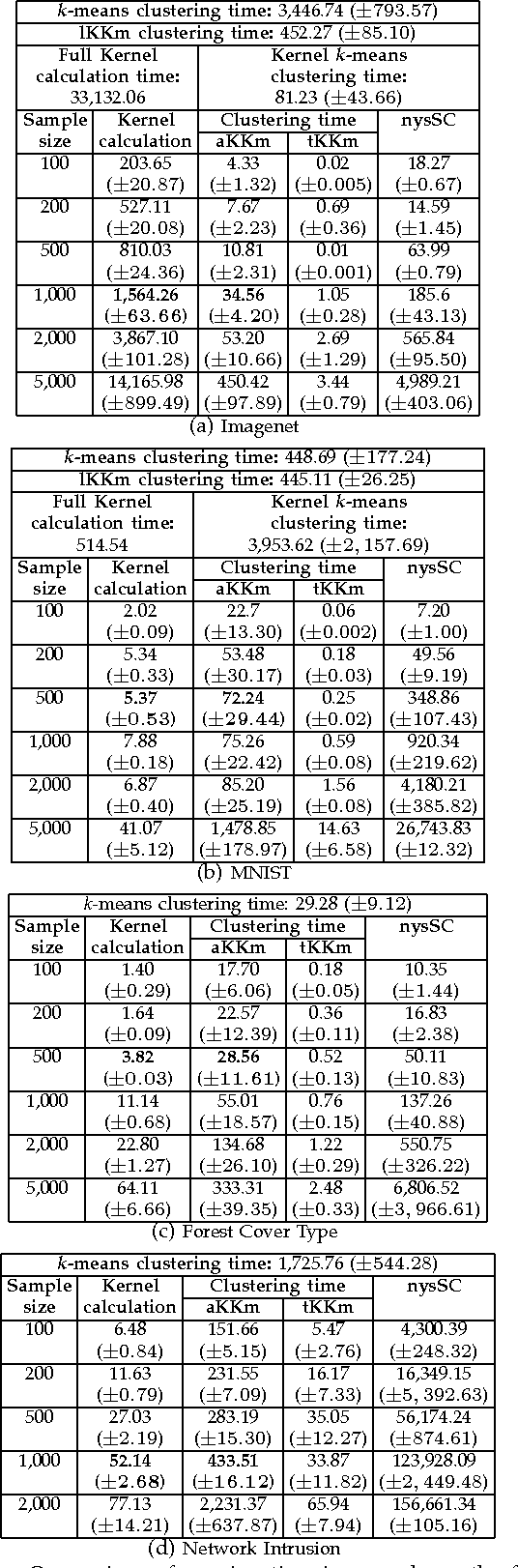
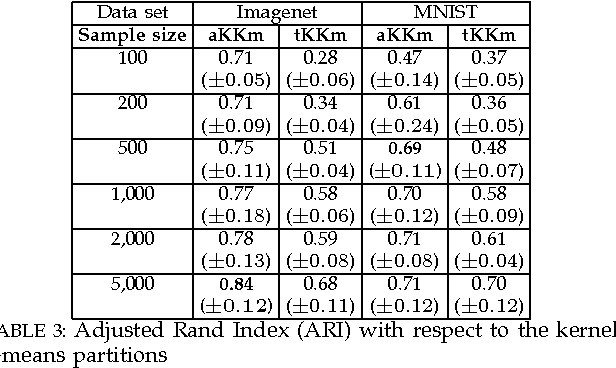
Kernel-based clustering algorithms have the ability to capture the non-linear structure in real world data. Among various kernel-based clustering algorithms, kernel k-means has gained popularity due to its simple iterative nature and ease of implementation. However, its run-time complexity and memory footprint increase quadratically in terms of the size of the data set, and hence, large data sets cannot be clustered efficiently. In this paper, we propose an approximation scheme based on randomization, called the Approximate Kernel k-means. We approximate the cluster centers using the kernel similarity between a few sampled points and all the points in the data set. We show that the proposed method achieves better clustering performance than the traditional low rank kernel approximation based clustering schemes. We also demonstrate that its running time and memory requirements are significantly lower than those of kernel k-means, with only a small reduction in the clustering quality on several public domain large data sets. We then employ ensemble clustering techniques to further enhance the performance of our algorithm.