 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Characterization of a Point-Cloud-Based Path Planner in Off-Road Terrain
Sep 09, 2025We present a comprehensive evaluation of a point-cloud-based navigation stack, MUONS, for autonomous off-road navigation. Performance is characterized by analyzing the results of 30,000 planning and navigation trials in simulation and validated through field testing. Our simulation campaign considers three kinematically challenging terrain maps and twenty combinations of seven path-planning parameters. In simulation, our MUONS-equipped AGV achieved a 0.98 success rate and experienced no failures in the field. By statistical and correlation analysis we determined that the Bi-RRT expansion radius used in the initial planning stages is most correlated with performance in terms of planning time and traversed path length. Finally, we observed that the proportional variation due to changes in the tuning parameters is remarkably well correlated to performance in field testing. This finding supports the use of Monte-Carlo simulation campaigns for performance assessment and parameter tuning.
Multifractal Terrain Generation for Evaluating Autonomous Off-Road Ground Vehicles
Jan 04, 2025



We present a multifractal artificial terrain generation method that uses the 3D Weierstrass-Mandelbrot function to control roughness. By varying the fractal dimension used in terrain generation across three different values, we generate 60 unique off-road terrains. We use gradient maps to categorize the roughness of each terrain, consisting of low-, semi-, and high-roughness areas. To test how the fractal dimension affects the difficulty of vehicle traversals, we measure the success rates, vertical accelerations, pitch and roll rates, and traversal times of an autonomous ground vehicle traversing 20 randomized straight-line paths in each terrain. As we increase the fractal dimension from 2.3 to 2.45 and from 2.45 to 2.6, we find that the median area of low-roughness terrain decreases 13.8% and 7.16%, the median area of semi-rough terrain increases 11.7% and 5.63%, and the median area of high-roughness terrain increases 1.54% and 3.33%, all respectively. We find that the median success rate of the vehicle decreases 22.5% and 25% as the fractal dimension increases from 2.3 to 2.45 and from 2.45 to 2.6, respectively. Successful traversal results show that the median root-mean-squared vertical accelerations, median root-mean-squared pitch and roll rates, and median traversal times all increase with the fractal dimension.
Machine learning method for light field refocusing
Mar 30, 2021

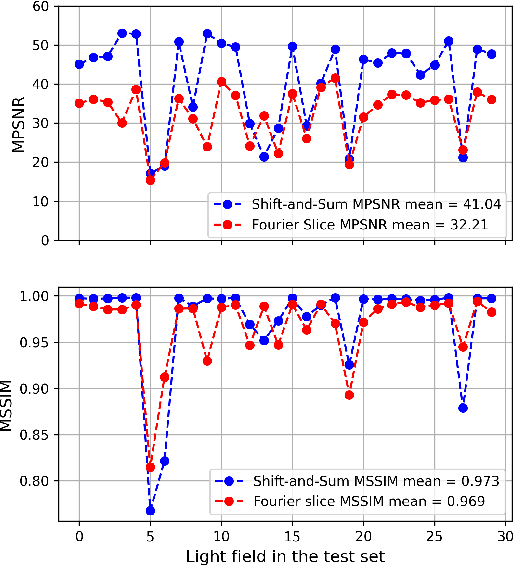

Light field imaging introduced the capability to refocus an image after capturing. Currently there are two popular methods for refocusing, shift-and-sum and Fourier slice methods. Neither of these two methods can refocus the light field in real-time without any pre-processing. In this paper we introduce a machine learning based refocusing technique that is capable of extracting 16 refocused images with refocusing parameters of \alpha=0.125,0.250,0.375,...,2.0 in real-time. We have trained our network, which is called RefNet, in two experiments. Once using the Fourier slice method as the training -- i.e., "ground truth" -- data and another using the shift-and-sum method as the training data. We showed that in both cases, not only is the RefNet method at least 134x faster than previous approaches, but also the color prediction of RefNet is superior to both Fourier slice and shift-and-sum methods while having similar depth of field and focus distance performance.
Light Field Compression by Residual CNN Assisted JPEG
Sep 30, 2020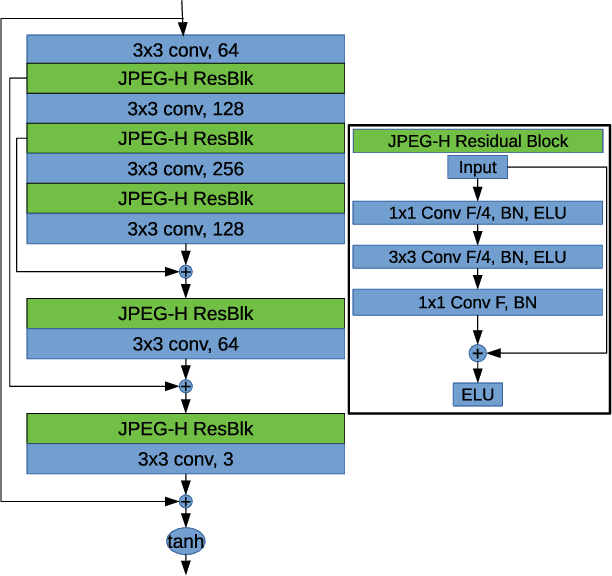

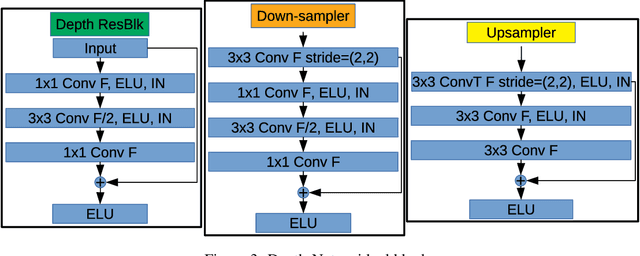
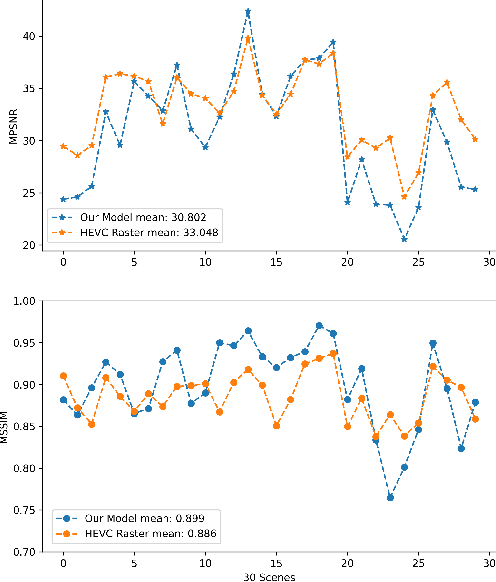
Light field (LF) imaging has gained significant attention due to its recent success in 3-dimensional (3D) displaying and rendering as well as augmented and virtual reality usage. Nonetheless, because of the two extra dimensions, LFs are much larger than conventional images. We develop a JPEG-assisted learning-based technique to reconstruct an LF from a JPEG bitstream with a bit per pixel ratio of 0.0047 on average. For compression, we keep the LF's center view and use JPEG compression with 50\% quality. Our reconstruction pipeline consists of a small JPEG enhancement network (JPEG-Hance), a depth estimation network (Depth-Net), followed by view synthesizing by warping the enhanced center view. Our pipeline is significantly faster than using video compression on pseudo-sequences extracted from an LF, both in compression and decompression, while maintaining effective performance. We show that with a 1\% compression time cost and 18x speedup for decompression, our methods reconstructed LFs have better structural similarity index metric (SSIM) and comparable peak signal-to-noise ratio (PSNR) compared to the state-of-the-art video compression techniques used to compress LFs.